12.02.2024
Modelle, Tools, Bereitstellung
1. Teil: „Demokratisierung der KI-Technologie“
Demokratisierung der KI-Technologie
Autor: Bernd Reder



Shutterstock / LookerStudio
chatGPT brachte für generative KI den Durchbruch. Inzwischen gibt es eine Vielzahl solcher Modelle und die Unternehmen haben die Qual der Wahl.
Im Bereich künstliche Intelligenz stehen derzeit generative KI-Anwendungen (GenAI) im Mittelpunkt des Interesses. Dazu zählen unter anderem Chat-GPT von OpenAI, Bard von Google und Copilot von Microsoft. Sie basieren auf großen Sprachmodellen (Large Language Models, LLMs) wie Llama 2 von Meta AI, GPT von OpenAI, Falcon von TTI und Palm von Google. Auch Luminous des deutschen Start-up-Unternehmen Aleph-Alpha gehört in diese Riege.
„Generative KI bekommt aus mehreren Gründen große Aufmerksamkeit. Bei Kreativ-Anwendungen hat der Ansatz bewiesen, dass Nutzer damit attraktive Inhalte erstellen können“, erläutert Markus W. Hacker, Direktor Enterprise Business DACH bei Nvidia. „Es lassen sich außerdem realistische Simulationen und synthetische Daten erzeugen, die in Bereichen wie autonome Fahrzeuge, Robotik und Gesundheitswesen von großem Nutzen sind.“ Generative KI wird außerdem eingesetzt, um Inhalte und Empfehlungen für Nutzer zu personalisieren und das Nutzererlebnis in Bereichen wie E-Commerce, Streaming-Diensten und Social-Media-Plattformen zu optimieren.
Demokratisierung von KI
Ein weiterer Grund für die hohe Popularität von GenAI ist „eine Demokratisierung der KI durch die Einführung von Transformer-Modellen, die Large Language Models antreiben“, erläutert Mat Keep, Distinguished Product Manager bei MongoDB, einem Anbieter von Datenservices für KI-Anwendungen. Die Transformer-Architektur ermögliche es im Vergleich zu Recurrent Neural Networks (RNN), Texte schneller zu erfassen und den Kontext von Wörtern besser zu verstehen.
-
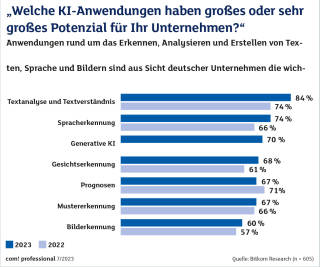
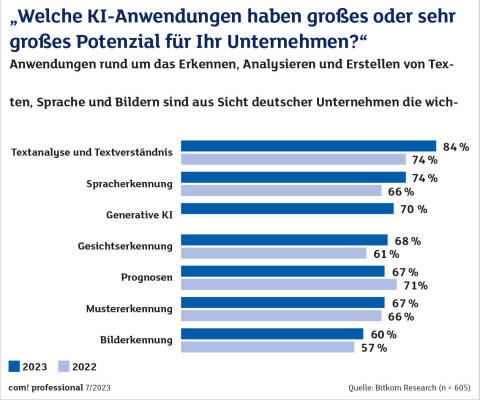
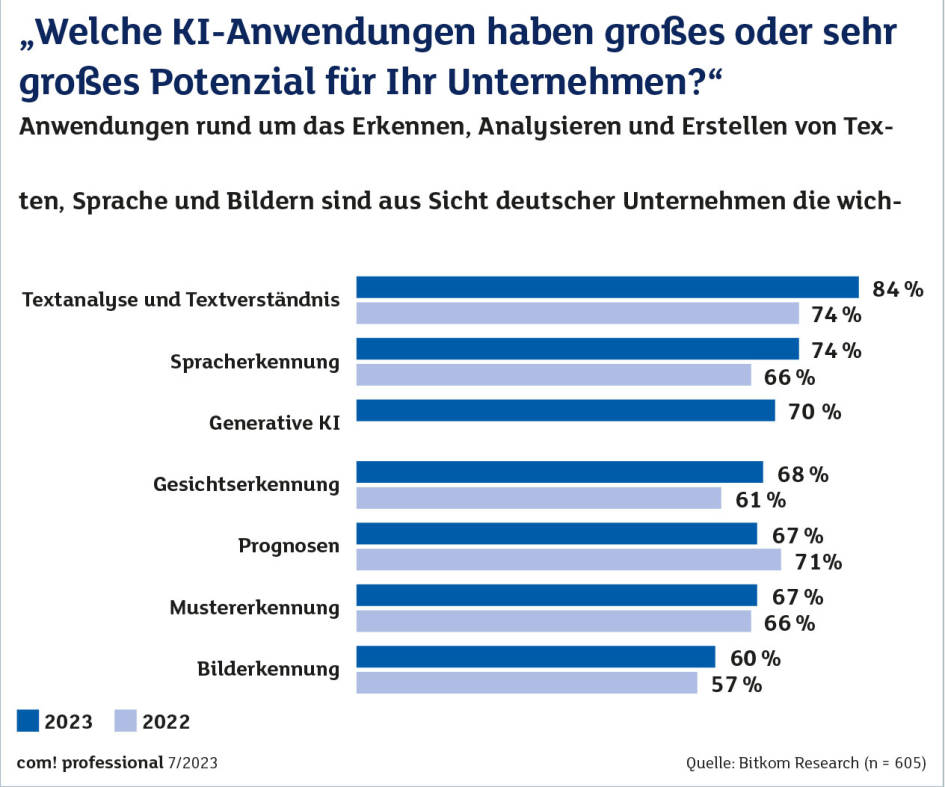
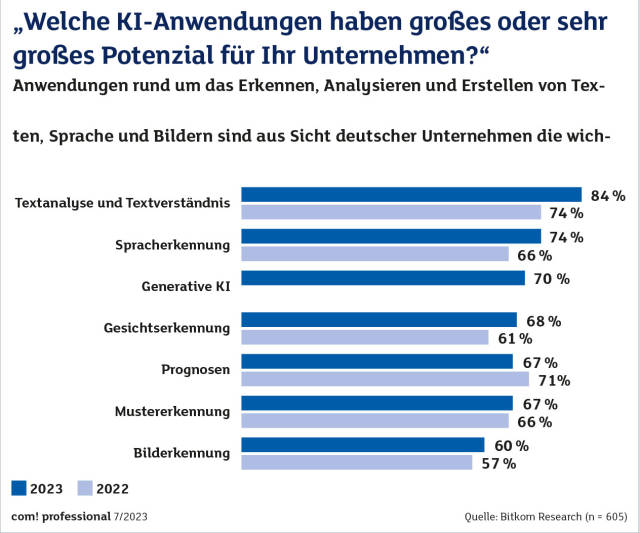 KI-AnwendungenQuelle:Bitkom Research
KI-AnwendungenQuelle:Bitkom Research
Durch die Kombination von Transformator-Ansätzen mit Techniken wie künstlichen neuronalen Netzen (Generative Adversarial Networks, GANs) und Variational Autoencoders (VAEs) werden KI-Anwendungen, speziell GenAI, leistungsfähiger und letztlich auch bezahlbarer. Damit erhalten auch kleinere Unternehmen einen besseren Zugang zu KI-Entwicklungsressourcen und Applikationen. „Dabei kann es sich um Anwendungen handeln, die auf der Verarbeitung natürlicher Sprache basieren, beispielsweise Chatbots, Spracherkennung und Übersetzungen“, so Keep weiter. Oder auch um Code-Assistenten sowie analytische Aufgaben wie die Planung von Marketingkampagnen.
Die Basis von Allem: ein Modell
Die Grundlage von KI-Anwendungen bildet ein Modell. Bei Generative AI sind dies Large Language Models. Vereinfacht gesagt versteht man unter einem Modell Programme, die mithilfe von Daten trainiert werden. Dadurch sind sie der Lage, Muster zu erkennen und selbstständig zu lernen und Entscheidungen zu treffen. Eine Herausforderung besteht darin, aus das passende Modell auswählen. Der Grund: „Auf der Open-Source Plattform Hugging Face gibt es mittlerweile über hunderttausend generative KI-Modelle in verschiedenen Größen und für diverse Anwendungsfälle“, berichtet Nils Nörmann, Advisory Technical Specialist – Watson, Data & AI bei IBM Technology. Ein Teil dieser LLMs stammt von Universitäten und Forschungseinrichtungen wie dem Big Science Project („Bloom“), dem europäischen OpenGPT-X-Projekt und dem Technology Innovation Institute („Falcon“). Hinzu kommen Modelle von Firmen wie Meta AI, Google, OpenAI, IBM, Microsoft und vielen weiteren Unternehmen.
Große Datenmengen – viele Parameter
„Large“ bezieht sich bei LLMs darauf, dass die Modelle mit großen Datenmengen trainiert werden: Bildern, Texten und Symbolen. Diese Informationen stammen aus dem Internet, Büchern, Programmcode und den Eingaben der Nutzer. Außerdem kann ein Unternehmen eigene Datenquellen nutzen, um ein Modell zu trainieren.
Ein Indikator für die Leistungsfähigkeit eines LLM ist die Zahl der verwendeten Parameter. Diese stieg in den vergangenen Jahren deutlich an. So verfügt GPT-4 von OpenAI über 1,76 Billionen Parameter. Beim Vorgänger GPT-3 waren es nur 175 Milliarden. Ein Parameter steht für die Stärke der neuronalen Verbindungen, die ein Modell während des Trainingsvorgangs aufbaut. Eine hohe Zahl von Parametern ermöglicht es dem Modell, nuancierte und komplexere Muster von Sprachinformationen zu erfassen. Das führt zu einer besseren Darstellung von Wörtern und Konzepten, die für das Verständnis des Kontextes und das Erstellen von Texten wichtig sind.
Ein weiterer Faktor, der die Performance von LLMs beeinflusst, ist die Zahl der Token. Das sind die Einheiten, in die ein Text unterteilt ist. Das können einzelne Zeichen, Silben oder ganze Wörter sein. Der Satz „Er kommt hundertprozentig zu spät“ lässt sich beispielsweise in Token wie „Er“, „kommt“, „hundert“, „prozent“ et cetera aufteilen. Während des Trainings lernt ein Modell, in welchem Kontext bestimmte Token verwendet werden. Dadurch kann es präziser und schneller vorhersagen, welche Wörter in einem Satz vermutlich als nächste folgen und damit seine Ausgabegenauigkeit erhöhen.
Start mit Foundation-Modellen
Ein guter Einstiegspunkt in generative KI sind Basismodelle (Foundation Models). Dazu zählen die LLMs der etablierten Anbieter. Diese Modelle werden vortrainiert, verfügen also gewissermaßen bereits über ein „Allgemeinwissen“. Fähigkeiten, die auf spezielle Einsatzfelder zugeschnitten sind, können Firmen durch ein Feintuning hinzufügen. Dabei wird den Modellen domänenspezifisches Wissen vermittelt, häufig mit Unterstützung von Menschen. Diese stellen dem Modell Eingabe-Ausgabe-Kombinationen zur Verfügung, etwa Antworten auf bestimmte Fragen.
„Durch zielgerichtetes Prompting und Feintuning können Nutzer Modelle anpassen und mit eigenen, kleineren Datenmengen die Ergebnisqualität deutlich verbessern“, bestätigt Nils Nörmann von IBM. Diese Feinabstimmung nehmen auf Wunsch auch externe Spezialisten vor, neben IBM beispielsweise Nvidia, Google, AWS, H2O oder Hugging Face.
Ein Beispiel ist die Klassifizierung von Kundenanfragen, die per E-Mail eingehen. „Kundenanfragen können auf einfache Weise typisiert und nach Art der Anfrage klassifiziert werden, etwa ob es sich um eine Bestellung oder eine Support-Anfrage handelt“, erläutert Mark Neufurth, Lead Strategist beim Cloud-Serviceprovider Ionos. „Zudem lassen sich Textdokumente zusammenfassen, gruppieren und suchen. Das erfolgt mithilfe der KI in wenigen Augenblicken und mit einem kurzen Prompt.“
Durch die Kombination von Basismodell und Feintuning reichen einige Tage oder gar Stunden aus, um einem GenAI-Modell branchenspezifisches Wissen zu vermitteln. Trainiert ein Nutzer dagegen ein Modell von Grund auf, kann dies je nach Größe des Modells mehrere Wochen in Anspruch nehmen.
Selbst entwickeln oder kaufen?
Eine Kernfrage bei KI ist, ob Interessenten KI-Modelle in Eigenregie entwickeln sollen oder besser vorgefertigte Lösungen erwerben. Die Antwort darauf hängt von mehreren Faktoren ab, wie AppliedAI in einem Whitepaper erläutert. Diese Initiative mit Sitz in München fördert die Anwendung vertrauenswürdiger KI-Technologie in Unternehmen. Zu diesen Faktoren zählen:
- Die Unternehmensstrategie und die Rolle von KI
- Vom Einsatzfeld hängt etwa ab, ob multimodale GenAI-Modelle erforderlich sind, die neben Text auch Bilder oder Videos unterstützen
- Der Bedarf an kundenspezifischen Anpassungen
- Die Qualität der (eigenen) Daten, die für das Training genutzt werden
- Der Schutzbedarf der unternehmenseigenen Daten und der IT-Infrastruktur
- Ob die Abhängigkeit von einzelnen Anbietern von KI-Lösungen vermieden werden soll. In diesem Fall bietet sich der Einsatz von Open-Source-Modellen an
- Die Verfügbarkeit von Experten im eigenen Haus
Für Branchen mit hohen Anforderungen in Bezug auf Compliance und Datenschutz, etwa den Finanzsektor und den Pharma- und Gesundheitsbereich, kommt eine „Ende-zu-Ende“-Strategie in Frage. Das heißt, sowohl die Entwicklung der KI-Anwendung als auch das Pre-Training und Tuning der Modelle finden im eigenen Haus statt. Der Vorteil: Anwendungen, Daten und KI-Modelle bleiben unter der Kontrolle der Unternehmen. Dem stehen höhere Kosten und möglicherweise ein höherer Zeitaufwand gegenüber. Für die meisten Firmen kommen daher Mischkonzepte in Frage. Eine Option ist, KI-Anwendungen selbst zu entwickeln und vortrainierte oder bereits optimierte Large Language Models von externen Anbietern zu beziehen. Der Vorteil ist, dass der Aufwand für das Training und Bereitstellen der Modelle sinkt. Anbieter wie Microsoft (Azure OpenAI) und KI-Plattformen stellen entsprechende Schnittstellen (APIs) für solche LLMs zur Verfügung. Allerdings müssen Datenschutz- und Compliance-Regelungen diesen Ansatz unterstützen.
Kosten nicht unterschätzen
Ein weiterer Punkt, der bei GenAI nicht unterschätzt werden sollte, ist der Aufwand, der mit dem Training von KI-Modellen verbunden ist, speziell von umfangreichen Large Langue Models. Laut dem „AI Index 2023“ des Institute for Human-Centered Artificial Intelligence (HA) der Stanford-Universität lagen beispielsweise 2022 die Trainingskosten eines LLM auf Basis des Palm-Modells bei acht Millionen Dollar. Niedriger waren sie bei GPT-NeoX-20B mit rund einer Viertelmillion Dollar und bei Stable Diffusion bei 0,6 Millionen Dollar.
Laut Tests von MosaicML, dem Betreiber einer KI- und Machine-Learning-Plattform, sind die Trainingskosten allerdings oft geringer, als dies Unternehmen glauben. Das Training eines GPT-3-Modells mit 30 Milliarden Parametern und 610 Milliarden Token kostete demnach auf der MosaicML-Plattform Ende 2022 rund 450.000 Dollar. Etwa 79 Prozent der befragten KI-Fachleute gingen von höheren Summen aus, rund 60 Prozent von einer Million Dollar und mehr. Vergleichbare Ergebnisse ergab 2023 ein Test von MosaicML mit dem Stable-Diffusion-Modell.
Dennoch sollten Unternehmen, die KI-Modelle entwickeln und trainieren möchten, den Faktor Kosten im Auge behalten: „Die größten Hürden für Unternehmen, die KI-Lösungen implementieren wollen, sind die Vorabkosten für Hard- und Software sowie für den Aufbau eines Teams mit KI-Kenntnissen, das die Infrastruktur einrichtet und wartet“, erläutert Markus Hacker von Nvidia. Unternehmen seien sich in der Regel darüber im Klaren, dass die Investition in eine KI in den Folgejahren Kosten sparen. „Sie benötigen jedoch eine Möglichkeit, Modelle zu testen oder mit ihnen zu experimentieren, um sie an ihre branchenspezifischen Bedürfnisse anzupassen“, so der Experte.
2. Teil: „„Generative KI ist so flexibel wie ein 3D-Drucker““
„Generative KI ist so flexibel wie ein 3D-Drucker“
Der Star unter den KI-Technologien ist derzeit zweifellos Generative AI. Daniel Hummel, Associate Partner beim Dienstleister KI Reply, erläutert, warum das so ist und welches Potenzial dieser Ansatz hat.
com! professional: Herr Hummel, welcher KI-Ansatz und, damit verbunden, welche KI- und Machine-Learning-Modelle haben derzeit das größte Potenzial?
-


 Daniel Hummel Associate Partner, KI ReplyQuelle:KI Reply
Daniel Hummel Associate Partner, KI ReplyQuelle:KI Reply

com! professional: Derzeit stehen vor allem generative KI-Lösungen im Mittelpunkt des Interesses. Was ist der Grund dafür?
Hummel: Generative AI ist derzeit im Fokus, weil sie sich von der klassischen KI unterscheidet: Sie zielt nicht darauf ab, Entscheidungen zu treffen oder Aktionen auszuführen, sondern schafft täuschend echt aussehende Daten. Die Technologie kann eine Vielzahl von Inhalten wie Texte, Bilder und sogar Musik generieren, was sie besonders nützlich für kreative und designorientierte Anwendungen macht.
com! professional: Es gibt eine Fülle von Bereichen, in denen KI zum Einsatz kommen kann. Welche sind aus Ihrer Sicht besonders wichtig?
Hummel: Ein Bereich, in denen Reply generative KI und andere KI-Lösungen einsetzt, ist die Software-Entwicklung. Frameworks wie Kicode Reply ermöglichen es, den gesamten Lebenszyklus bei der Softwareentwicklung automatisiert zu durchlaufen, und das auf der Grundlage einer einzigen Anweisung – von der Idee bis zur Bereitstellung. Ein weiteres Beispiel sind KI-gestützte Tools und Low-Code/No-Code-Plattformen, um die Entwicklung und Leistungsfähigkeit von Software zu verbessern. Außerdem nutzen wir KI bei „Digital Humans“. Es werden Schnittstellen entwickelt, die natürliche und einfühlsame Interaktionen zwischen Menschen und digitalen Ökosystemen ermöglichen, etwa beim personalisierten „Customer Engagement“. Auch experimentiert Reply mit generativer KI in der Videoproduktion, um visuelle und Audio-Inhalte zu schaffen.
com! professional: Im Zusammenhang mit GenAI taucht oft der Begriff Multimodalität auf. Welche Rolle spielt er?
Hummel: Durch die Multimodalität ist Generative AI nicht auf ein bestimmtes Medium wie Musik, Sprache oder Bild beschränkt, sondern verknüpft diese miteinander. Technisch handelt es sich hierbei um einen gleichen „Embedding Space“. Bilder, Musik und Text lassen sich nun in neuronalen Netzwerken ähnlich oder gleich repräsentieren. Das erlaubt wiederum die problemlose Umwandlung von Bild zu Text, Text zu Bild sowie Bild und Audio zu Text, was wiederum viele Möglichkeiten eröffnet, die zuvor nur mit viel Mühe mit Hilfe von maßgeschneiderten Machine-Learning-Lösungen realisiert werden konnten.
com! professional: Welche Vorteile bringt das den Firmen?
Hummel: Im Vergleich mit traditionellen Prozessen, bei denen immer erst ein Datensatz gesammelt, trainiert und validiert werden musste, bietet der Ansatz Nutzern die Chance, sehr schnell Automatisierung und unterstützende Funktionen bereitzustellen. So kann gleichsam unmittelbar eine Produktivitätssteigerung für fast alle Businessprozesse erzielt werden – was wiederum die Investitionen in KI rechtfertigt.
Die Flexibilität von Generative AI lässt sich mit einem 3D-Drucker vergleichen, der Objekte in jeglicher Form drucken kann. Dagegen ähneln traditionelle Modelle, die auf spezifischen Datensätzen beruhen, klassischen Industriemaschinen, die immer nur ein bestimmtes Bauteil produzieren können.
com! professional: Welches Know-how erfordert der Einsatz von GenAI im Vergleich zu anderen KI-Ansätzen? Ist die Hürde dort vielleicht sogar höher?
Hummel: Nein, Generative AI lässt die „Barrier-to-Entry“ sogar sinken. Auch ohne Fachkenntnisse kann man das gleiche Netzwerk zur Lösung einer Vielzahl unterschiedlicher Probleme „out-of-the box“ nutzen – und das mit sehr guten Ergebnissen. Generative AI ist damit ein Schritt in Richtung genereller KI-Lösungen, die auch als Artificial General Intelligence, kurz AGI, bezeichnet werden.
3. Teil: „„KI-Modelle können zu Angriffszielen werden““
„KI-Modelle können zu Angriffszielen werden“
Auch beim Training und Einsatz von KI-Modellen sind Sicherheitsvorkehrungen erforderlich. Wo Risiken liegen und was dagegen zu tun ist, erläutert Moritz Plassnig, Chief Product Officer beim Datensicherheitsspezialisten Immuta.
com! professional: Herr Plassnig, KI-Modelle werden häufig mit unstrukturierten Daten trainiert. Bringt das besondere Risiken mit sich?
-


 Moritz Plassnig Datensicherheitsexperte und Chief Product Officer, ImmutaQuelle:Immuta
Moritz Plassnig Datensicherheitsexperte und Chief Product Officer, ImmutaQuelle:Immuta

com! professional: Können Sie dazu ein Beispiel nennen?
Plassnig: In einem Text, in dem es beispielsweise um eine bestimmte Krankheit geht, würde es in automatisierten Prozessen schwierig werden, zwischen einem wissenschaftlichen Text, der Forschungsarbeiten thematisiert, und einem medizinischen Befund zu unterscheiden. Ohne präzise Datenklassifizierung besteht die Gefahr, dass ein Modell mit sensiblen Daten trainiert wird.
com! professional: Sind Large Language Models, wie sie bei generativer KI zum Einsatz kommen, stärker gefährdet als kleinere, selbst erstellte Modelle?
Plassnig: Öffentliche Modelle sind weitaus anfälliger für Diebstahl als kleinere private Modelle. In absehbarer Zukunft könnten öffentlich zugängliche Modelle zudem zu begehrten Angriffszielen für sogenanntes Data Poisoning werden, bei dem ungenaue Daten in den Trainingsprozess eingeschleust werden. Ein solcher Datenverfälschungsansatz wurde bereits bei Anwendungen beobachtet, die nicht auf KI basieren, etwa Online-Märkten und deren Bewertungssystemen.
com! professional: Wie ist es um die Sicherheit von KI-Modellen bestellt, die Unternehmen über Cloud-Plattformen beziehen, etwa von AWS, Microsoft Azure und Google?
Plassnig: Solche Plattformen stellen Modellvorhersagen ausschließlich über API-Endpunkte bereit, was das Risiko eines Modelldiebstahls erheblich minimiert. Sicherheitsvorfälle, wie das online durchgesickerte Facebook-Llama-Modell, zeigen jedoch, dass das Risiko auch hier nicht bei null liegt.
Die Sicherheit von KI-Modellen ist und bleibt ein wichtiges Thema, das kontinuierlich analysiert und angepasst werden muss, um die Integrität und den Schutz von Nutzerdaten und Anwendungen zu gewährleisten. Angesichts des Fortschritts in der KI-Entwicklung ist es wahrscheinlich, dass künftige Spitzen-KI-Modelle verstärkt aus der Open-Source-Community stammen, was die Aufmerksamkeit vermehrt auf Sicherheitsaspekte lenken könnte.
com! professional: Welche Gegenmaßnahmen stehen zur Verfügung?
Plassnig: Bei den meisten Gegenmaßnahmen handelt es sich um bewährte Verfahren im Bereich Datensicherheit. Dazu gehören Zugriffskontrolle, Hygiene der Datenwege sowie die Verschleierung sensibler Daten. Einige dieser Best Practices sind jedoch im Kontext von LLMs nicht gleichermaßen effektiv. Es hat sich gezeigt, dass das einfache Schwärzen vertraulicher Informationen in unstrukturierten Datensätzen nach wie vor dazu führen kann, dass sensible Daten unbeabsichtigt preisgegeben werden.
Selbst Trainingsmodelle mit stochastischen Schutzmaßnahmen, etwa der differenziellen Privatsphäre, „verlieren“ immer noch Informationen, wenn sie nicht richtig angewendet werden. Daher ist es wichtig, bei der Auswahl von Gegenmaßnahmen im Bereich KI-Sicherheit sorgfältig vorzugehen und sich bewusst zu sein, dass nicht alle herkömmlichen Ansätze in dieser speziellen Domäne gleichermaßen wirksam sind.
4. Teil: „Plattformen als Wege zum Modell“
Plattformen als Wege zum Modell
Wer KI-Modelle entwickeln und testen möchte, muss nicht zwangsläufig die IT-Infrastruktur, Tools und Basismodelle im eigenen Haus vorhalten. Eine Alternative sind KI-Plattformen, beispielsweise von Anbietern wie Hugging Face, H2O, Datarobot und MosaicML und IBM (Watsonx). Nvidia bietet für solche Aufgaben AI Workbench an. Damit können Entwickler KI-Umgebungen in Form von Containern auf Linux- und Windows-Systemen einrichten, inklusive Modellen und Tools von Github. Die KI-Workloads lassen sich bei Bedarf in Cloud-Umgebungen oder die DGX-Cloud von Nvidia verschieben. Dort stehen Grafikprozessoren und weitere KI-Modelle zur Verfügung.
Auch die Datenplattformen von Databricks und MongoDB mit Services wie MongoDB Atlas können den Weg zum KI-Modell ebnen. „Unternehmen sollten darauf achten, sich nicht in die Abhängigkeit einzelner Anbieter zu begeben“, mahnt Matt Keep von MongoDB. „MongoDB Atlas Vector Search läuft daher auf AWS, Microsoft Azure und Google Cloud und arbeitet mit KI-Modellen von Bedrock AI, OpenAI, Google Vertex AI oder Hugging Face zusammen, ohne dass Entwickler auch nur eine Codezeile in ihrer Anwendung ändern müssen.“
KI-Modell via Cloud-Service
Eine weitere Nutzungsoption sind Dienste von Cloud-Serviceprovidern, und zwar nicht nur die der Hyperscaler- Mittlerweile bieten auch Provider mit Sitz in der Europäischen Union den Zugang zu KI-Diensten und Entwicklungsressourcen. „Wir sehen uns aktuell in der Rolle, KI zu demokratisieren – besonders für kleine und mittelständische Unternehmen“, sagt beispielsweise Mark Neufurth, Lead Strategist bei Ionos. „Wir verstehen uns als Partner auf Augenhöhe, der KI-Tools auch kuratiert anbieten kann, anstatt KMU auf die Suche in den Dschungel der Tools zu schicken.“
Neufurth betont einen weiterer Vorteil von EU-Anbietern für die Unternehmen: „Da die Daten in europäischen Rechenzentren gehostet werden, gehen die Kunden und Anwender sicher, dass sie Herr über ihre Daten bleiben. Dies ist insbesondere bei sensiblen Daten entscheidend.“
Für Cloud-Plattformen generell spricht, dass sie eine skalierbare Infrastruktur für KI-Modelle und entsprechende Anwendungen zur Verfügung stellen.
-


 Balance-Akt: Der in zwei bis drei Jahren in Kraft tretende EU AI Act soll die Risiken bändigen, ohne die Chancen abzuwürgen.Quelle:Shutterstock / AlexLMX
Balance-Akt: Der in zwei bis drei Jahren in Kraft tretende EU AI Act soll die Risiken bändigen, ohne die Chancen abzuwürgen.Quelle:Shutterstock / AlexLMX

Kombination von KI-Spielarten
Doch trotz des „Hype“, den GenAI ausgelöst hat, wird die KI-Welt auch künftig nicht nur aus diesem Ansatz bestehen: „Die klassischen KI-Anwendungsfälle sind nach wie vor wichtig, und es wird weiterhin große Investitionen in diesen Bereichen geben“, betont Mat Keep. Als Beispiel führt er die KI-gestützte Verwaltung von Lagerbeständen an. Auch die Sprachsteuerung von Edge-Systemen in der Industrie und im Home-Automation-Bereich erfordere nicht zwangsläufig Generative AI.
Auch Nils Nörmann von IBM Technology plädiert für eine differenzierte Sichtweise: „Generative KI kann für viele Anwendungsfälle sehr gute Ergebnisse liefern. Die hohen Betriebskosten können sie allerdings für manche Szenarien unwirtschaftlich machen.“ Daher sei Conversational AI, die sich auf die Interaktionen von Mensch und Maschine konzentriere, in einigen Fällen die bessere Alternative. „Conversational AI analysiert und erkennt Intents und gleicht sie mit vortrainierten Antworten ab, kann aber im Gegensatz zu generativer KI nicht ‚kreativ‘ werden und neue Antworten generieren“, so der Fachmann.
In der Praxis werden sich daher Einsatzszenarien entwickeln, in denen beide KI-Ansätze zum Tragen kommen, zum Beispiel bei der Automatisierung von Kundenservice-Anfragen mit Hilfe von Chatbots.
-
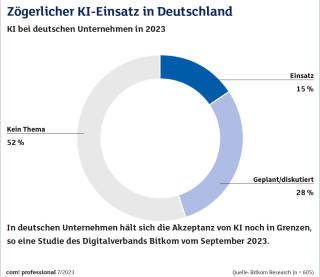
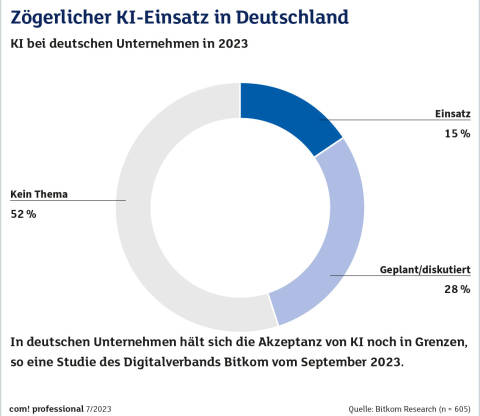
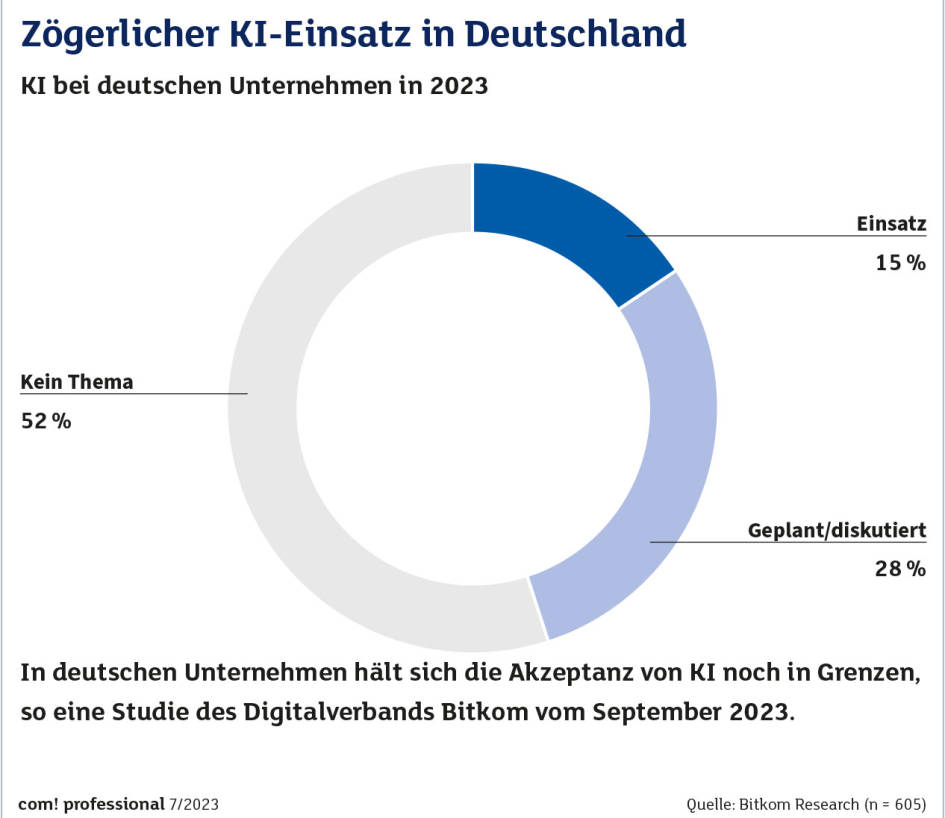
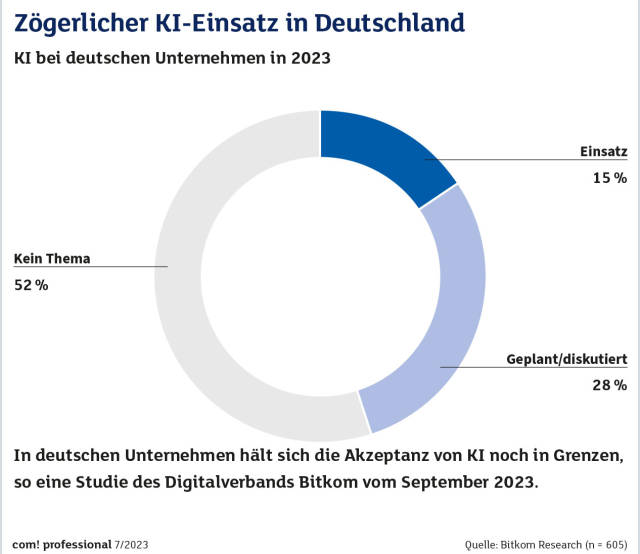 KI-EinsatzQuelle:Bitkom Research
KI-EinsatzQuelle:Bitkom Research
Heiße KI-Trends
Zum Abschluss ein Blick auf die Trends, die bei KI allgemein und GenAI im Besonderen derzeit an Bedeutung gewinnen. Zu diesen zählt Retrieval Augmented Generation (RAG). Dieser Ansatz kombiniert KI-Modelle, die auf Abfragen basieren, mit Generative AI. Die Abfragen extrahieren Wissen aus vorhandenen Quellen wie Datenbanken, Dokumenten, Web-Seiten und Blogs. Unternehmen können dafür außerdem eigene, geschäftsspezifische Informationen verwenden. In die Antworten von GenAI-Systemen fließen dadurch verstärkt aktuelle Informationen ein. Dies reduziert die Gefahr, dass eine generative KI-Anwendung falsche Antworten „halluziniert“.
Ein weiterer Vorteil ist, dass Nutzer das KI-Modell nicht permanent mit neuen Daten trainieren und dessen Parameter ständig neu justieren müssen. Zu den Plattformen, die RAG-Funktionen bereitstellen, zählen IBM Watsonx, Cohesity, Microsoft Azure OpenAI und Google in Verbindung mit dem Vertex-Palm-2-LLM.
Noch einen Schritt weiter als RAG gehen KI-basierte autonome Agenten. Auch ihre Grundlage sind große Sprachmodelle. Solche Agenten sollen in der Lage sein, eigenständig Aufgaben zu erfüllen – ähnlich wie ein Mensch. Dazu zählen Telefonate führen, E-Mails versenden und Aufgabenlisten erstellen, inklusive Erinnerungen. Erste Feldversuche mit solchen KI-Technologien laufen bereits, etwa mit AutoGPT von OpenAI und Jarvis von Meta.
5. Teil: „Fazit & Ausblick“
Fazit & Ausblick
Generative KI-Anwendungen werden mit Sicherheit in viele Lebensbereichen Einzug halten, sowohl in der beruflichen wie in der privaten Sphäre. Das ist gut, solange sich diese Anwendungen an die „Spielregeln“ halten, also weder Fehlinformationen liefern noch Datenlecks und Deepfakes produzieren noch Menschen wegen unzureichender Trainingsdaten diskriminieren. Auch die Debatten über Verstöße gegen das Urheberrecht durch GenAI zeigen, dass sich Mensch und KI noch aneinander gewöhnen müssen.
Eine neue Dimension werden die Debatten erreichen, wenn Ansätze wie autonome KI-Agenten einsatzbereit sind. Sie basieren ebenfalls auf GenAI-Technologien, solllen aber mal in der Lage sein, eigenständig komplexe Aufgabe zu erledigen. Sie sollen E-Mail-Korrespodenzen, Telefonate, To-Do-Listen und sogar Vertragsverhandlungen übernehmen. Da ist nicht nur Zukunftsmusik. AutoGPT (OpenAI), Jarvis (Meta) und BabyAGI der gleichnamigen Projektgruppe sind aktuell bereits dabei, in Sphären vorzustoßen, die bislang Menschen vorbehalten waren.
-
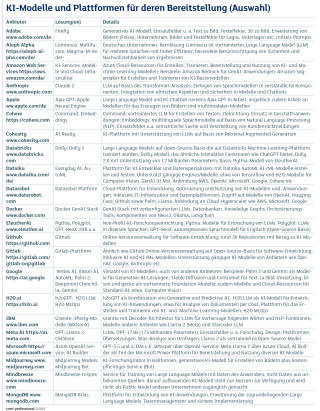
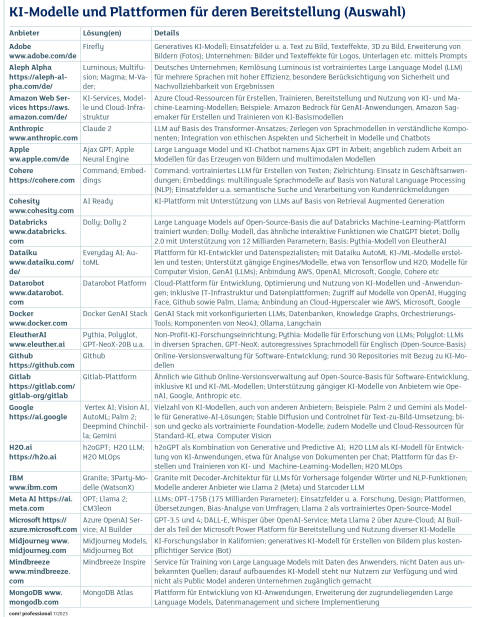
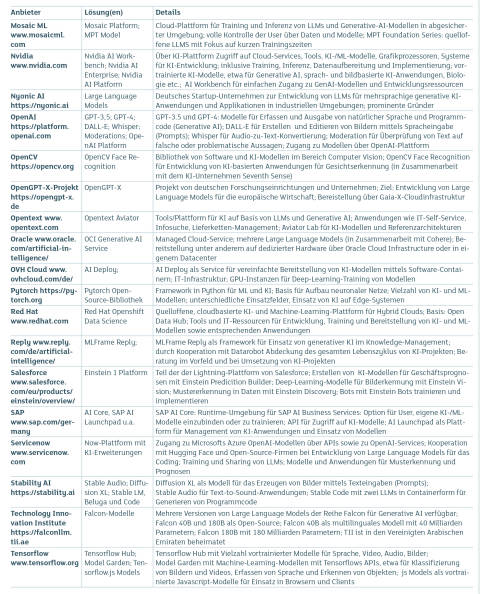
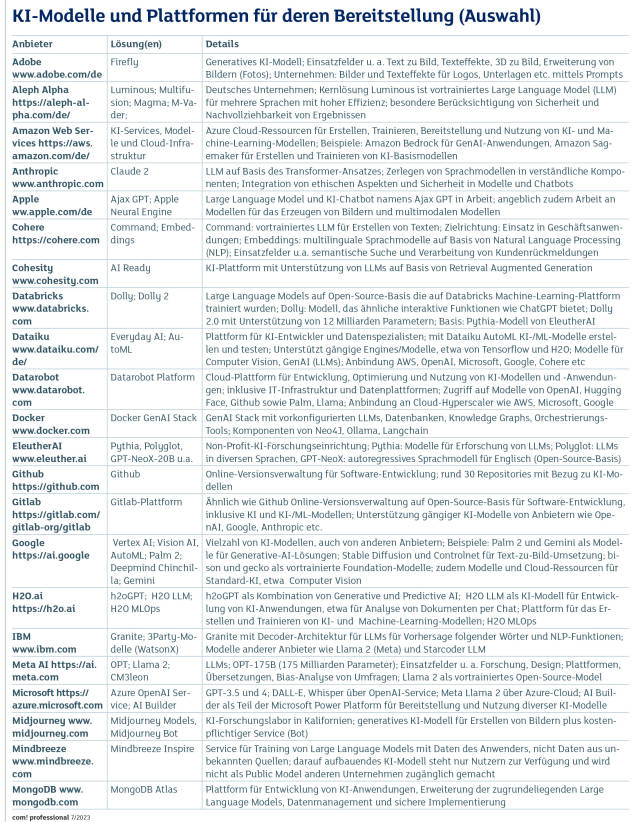 KI-Modelle und Plattformen Teil 1Quelle:com! professional
KI-Modelle und Plattformen Teil 1Quelle:com! professional
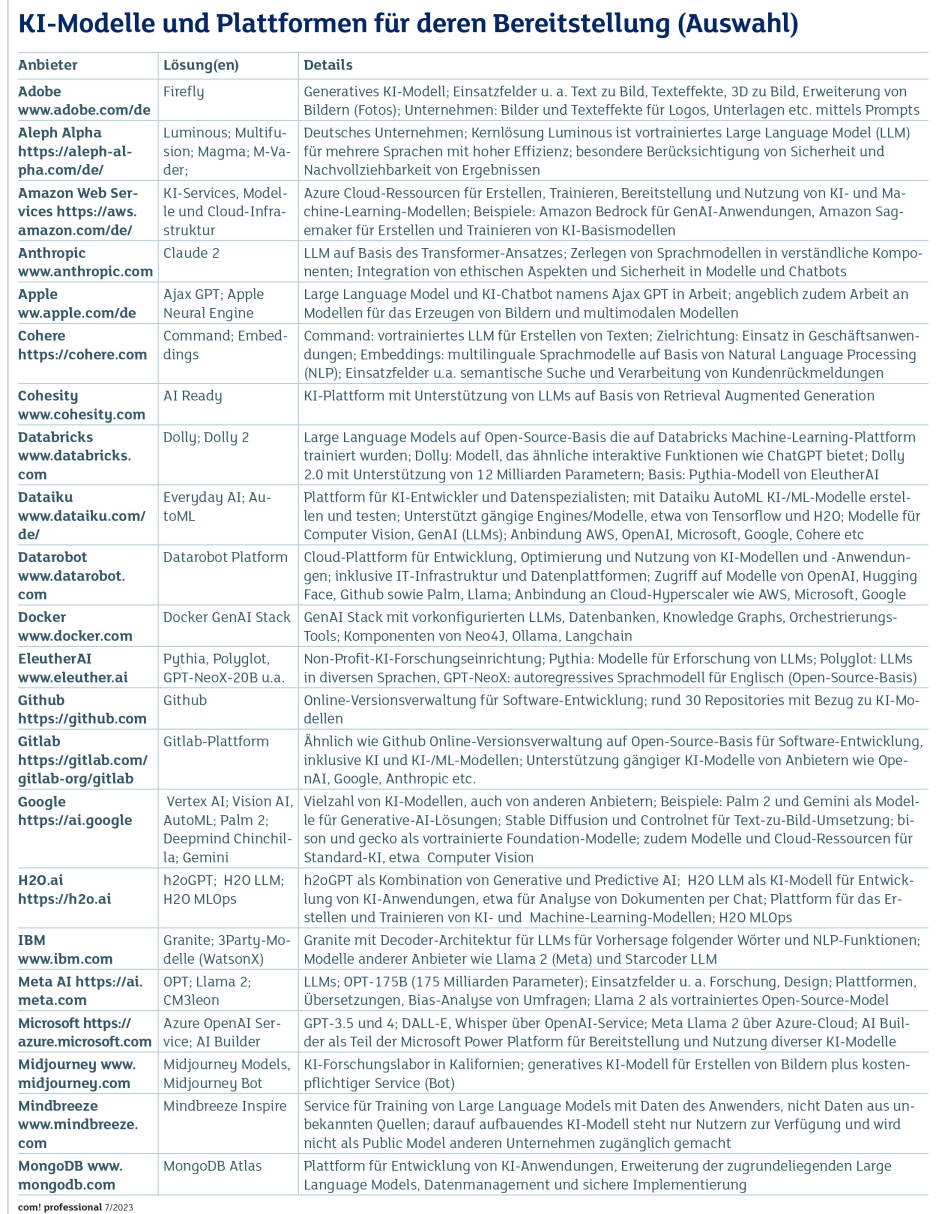
-

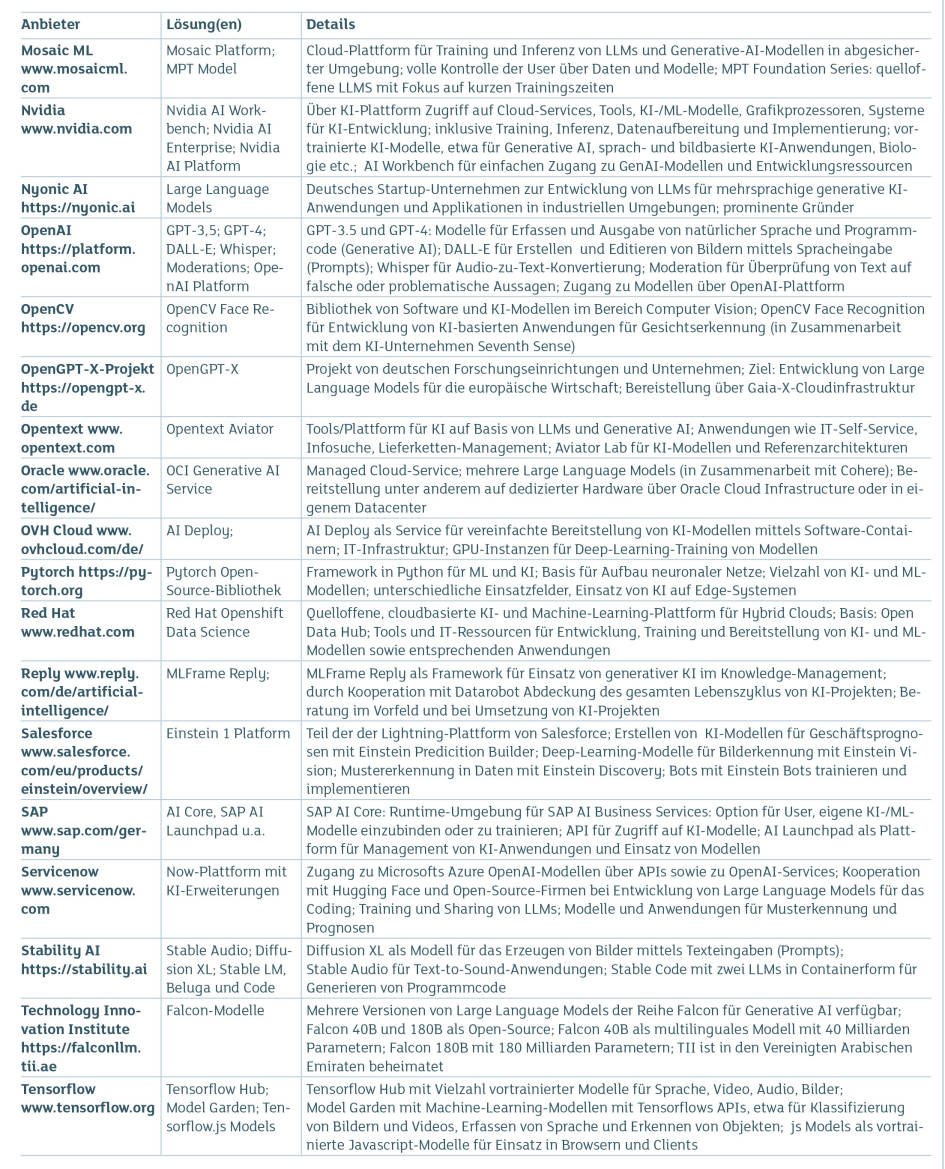
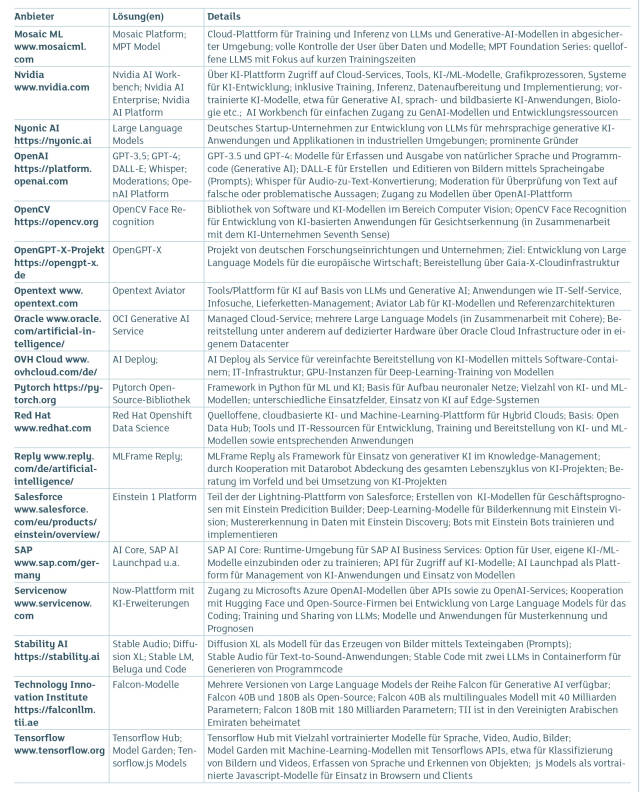 KI-Modelle und Plattformen Teil 2Quelle:com! professional
KI-Modelle und Plattformen Teil 2Quelle:com! professional
Expansion
Also steigt bei Westcoast ein
Zwei Schwergewichte der europäischen Distributionslandschaft tun sich zusammen: Also und Westcoast. Der Deal umfasst die Aktivitäten des Unternehmens im Vereinigten Königreich, Irland und Frankreich – Deutschland ist nicht betroffen.
>>
Neue LLMs
KI-Modelle größer, schneller
Neue Large Language Models (LLM) zeigen, mit welcher Geschwindigkeit die Entwicklung der Künstlichen Intelligenz auch weiterhin voranschreitet.
>>
Verdoppelung
Immer mehr Unternehmen nutzen Künstliche Intelligenz
Die deutsche Wirtschaft setzt stärker auf Künstliche Intelligenz (KI). Gegenwärtig nutzen 27 Prozent der Unternehmen KI. Im Vorjahr waren es noch 13,3 Prozent. Das ergab eine Befragung des Ifo Instituts.
>>
Umfrage
Globale Entwicklerpopulation wächst auf 27 Millionen: KI-Adoption nimmt zu
Trotz wirtschaftlicher Herausforderungen und geopolitischer Konflikte verzeichnet die weltweite Entwicklergemeinschaft ein robustes Wachstum. Eine neue Studie zeigt, dass insbesondere die KI-Nutzung unter Entwicklern stark zunimmt.
>>