28.12.2015
Software-defined Storage
1. Teil: „Unstrukturierte Daten effizient speichern“
Unstrukturierte Daten effizient speichern
Autor: Gerald Sternagl



Pavel Ignatov / Shutterstock.com
Klassische Storage-Methoden können das explosionsartige Datenwachstum kaum mehr bewältigen. Abhilfe gegen den Datenwust aus Bildern, E-Mails oder Dokumenten schafft SDS.
Wollen Unternehmen die drastisch ansteigende Datenmenge in den Griff bekommen, müssen sie effiziente Methoden zur Verwaltung einsetzen. Software-defined Storage, kurz SDS, ermöglicht den Aufbau hochskalierbarer, flexibler Architekturen, mit denen sich eine breite Vielfalt von Daten verwalten lässt.
In einer solchen Umgebung werden Daten (Blöcke, Files oder Objekte) hardwareunabhängig in einer verteilten Architektur auf einer großen Zahl von Standard-Servern als einheitlicher, gemeinsam zu nutzender Speicher-Pool abgelegt.
2. Teil: „Die unterschiedlichen SDS-Ansätze“
Die unterschiedlichen SDS-Ansätze
-


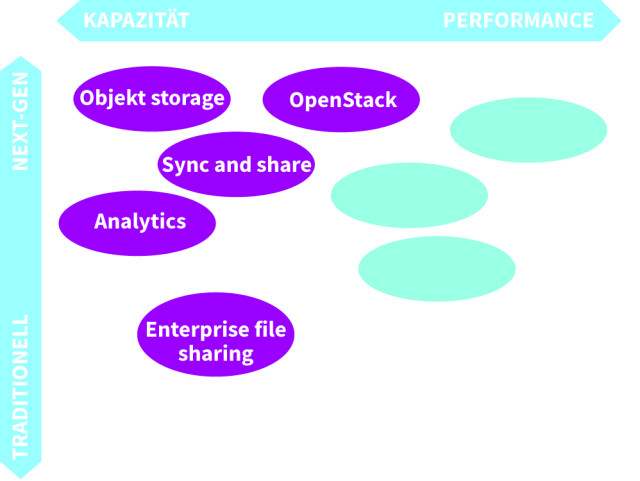 Verschiedene Storage-Arten: Die Speichertechnologien unterscheiden sich in Kapazität und Performance.Quelle:Quelle: Red Hat
Verschiedene Storage-Arten: Die Speichertechnologien unterscheiden sich in Kapazität und Performance.Quelle:Quelle: Red Hat
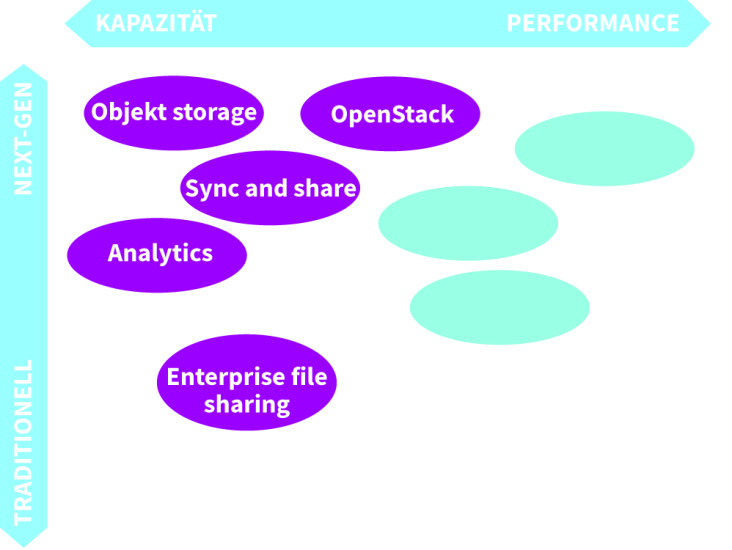
Herkömmliche File-Systeme: Diese sind aufgrund ihrer hierarchischen Struktur nur begrenzt skalierbar. Blockbasierte Speicher, wie ihn Storage Area Networks verwenden, verwalten die Daten als Blöcke mit Sektoren und Tracks. Im Cloud-Bereich ist das OpenStack-Projekt Cinder ein weitverbreiteter Blockspeicher.
Objektorientierte Speichersysteme: Sind historisch als Alternative zu den datei- und blockbasierten Systemen entstanden und enthalten zusätzlich zu den eigentlichen Informationen auch Metadaten, die sich einfacher indizieren lassen als unstrukturierte Daten. Sie nutzen die Representational-State-Transfer-Architektur (REST) zur Abstraktion der Daten von der Applikation. Das OpenStack-Projekt Swift ist ein typischer Vertreter eines objektorientierten Speichersystems.
Shared-File-/Objektspeicher-Lösungen: Sie verwenden die Stärken der weitverbreiteten dateibasierten Applikationen. Gleichzeitig machen sie die Daten auch für objektbasierte Applikationen zugänglich, nutzen dazu REST-basierte Methoden und bieten so eine hohe Flexibilität.
3. Teil: „Best Practices zur SDS-Einführung“
Best Practices zur SDS-Einführung
Jedes Unternehmen muss seinen individuellen Weg bei der Implementierung von Software-defined Storage finden. Charakteristisch sind eine hohe Agilität und ein iteratives Vorgehen. Statt des ganz großen Wurfs empfiehlt sich zunächst die Konzentration auf ein Anwendungsszenario mit besonders großem Handlungsbedarf. Die folgenden fünf Best Practices unterstützen Unternehmen beim Einstieg in eine Software-defined-Storage-Lösung:
- Unternehmensbereiche mit dem größten Bedarf ermitteln
Nur ein geringer Anteil der Unternehmensdaten ist in relationalen Datenbanken abgelegt, der größte Teil besteht aus unstrukturierten Daten wie Bilder, Dokumente, Tabellen und Zeichnungen. Wichtig ist, zunächst festzustellen, an welchen Speicherorten sich die relevanten Informationen befinden und welche Kapazitäten diese benötigen – unter Beachtung von Verfügbarkeit und Reaktionsfähigkeit. - Die Anwendungsszenarien mit dem größten Handlungsdruck identifizieren
Als nächster Schritt sollte festgestellt werden, wer welche Dokumente, Medieninhalte oder Geodaten wie oft in welchen Anwendungsszenarien nutzt und welchen Stellenwert diese Daten für das Unternehmen haben. - Weniger kritische Daten und neue Applikationen zuerst migrieren
Die Migration unstrukturierter Daten auf eine neue SDS-Plattform ist ein ambitioniertes Projekt mit vielfältigen Implikationen. Um erste Erfahrungen zu sammeln, sollten Unternehmen in einem klar umgrenzten Anwendungsszenario ihre Anforderungen und die Zielerreichung testen. Auf dieser Basis können dann weitere Datenbestände migriert werden. - Festlegen, ob die Anwendungen vor Ort oder in der Cloud betrieben werden
Aus organisatorischen Gründen sollten sich die Verantwortlichen frühzeitig Gedanken darüber machen, ob die SDS-Plattform auf physischen Servern, in einer virtualisierten Umgebung oder in der Cloud laufen soll. Sollen alle drei Bereitstellungsmodelle gleichzeitig verwendet werden, ist eine flexible Lösung nötig, die dies unterstützt. - Das richtige Maß an Datensicherung und Replikation definieren
Von Anfang an müssen Backup- und Recovery-Pläne definiert und Maßnahmen implementiert werden. Dafür sollten in verschiedenen Szenarien mögliche Schadensfälle und die Kosten durchgespielt werden. Die Ergebnisse dienen als Grundlage für die benötigten Investitionen in die Datensicherung und -wiederherstellung. Unternehmenskritische Daten erfordern naturgemäß mehr Schutz. Eine moderne SDS-Lösung bietet die Möglichkeit, verschiedene Speicherklassen zu definieren und diese nach den erforderlichen Verfügbarkeits- und Wiederherstellbarkeits-Anforderungen der Daten zu priorisieren.
Die Einsatzgebiete
Zu den Einsatzgebieten von SDS zählen Archive für medizinische Daten etwa beim Gene-Sequencing, Daten aus meteorologischen Aufzeichnungen oder komplexe Medieninhalte beziehungsweise Audio- und Videodaten, wie sie von Content Delivery Networks benötigt werden. Unternehmen, die mit einem massiven Wachstum unstrukturierter Daten zu kämpfen haben, erhalten mit einer softwarebasierten Lösung die Möglichkeit, zusätzliche Kapazitäten in die Cloud zu verlagern.
Geschäftsführung
D-Link - Thomas von Baross geht
Lange Jahre war Thomas von Baross Geschäftsführer von D-Link Deutschland - nun verlässt er das Unternehmen. Seine Nachfolger kommen aus den eigenen Reihen.
>>
SIP-Trunk
Herweck und Xelion vertiefen Kooperation
Schon seit längerer Zeit vermarktet Herweck die Cloud-PBX von Xelion. Nun bietet der Distributor dazu auch seinen eigenen SIP-Trunk Calamar an.
>>
VS Code Windows und Mac
Brauchbare Alternative
Das C# Dev Kit for Visual Studio Code könnte eine Alternative für Entwickler sein, die weiterhin macOS nutzen möchten. Unser Schwesterportal dotnetpro hat es auf den Prüfstand gestellt.
>>
Google I/O 2024
Google Gemini ermöglicht mehr Funktionen und Individualität
Der große Star bei der diesjährigen Google-Entwicklerkonferenz I/O war Gemini. Die KI-Technologie hält Einzug in diverse Anwendungen und bietet neue Möglichkeiten bei der Entwicklung und Nutzung bekannter und neuer Google-Apps.
>>