29.12.2015
Big Data
1. Teil: „Kostengünstige Datenanalyse für Fachbereiche“
Kostengünstige Datenanalyse für Fachbereiche
Autor: Oliver Ehm
shutterstock / is am are
Hadoop und NoSQL speichern und verarbeiten die Daten auf Standard-Hardware.
Bislang setzten Unternehmen auf Data-Warehouse-Techniken, um aus ihren IT-Systemen wichtige Erkenntnisse über ihr aktuelles Geschäft zu ziehen. In jüngster Zeit ist dieser Ansatz von der Realität überholt worden. Während des normalen Geschäftsbetriebs eines Unternehmens fallen heute Tag für Tag riesige Mengen an Daten an – sei es aus der Produktion, der Online-Präsenz oder den Sensordaten von Mobilgeräten und Maschinen.
-
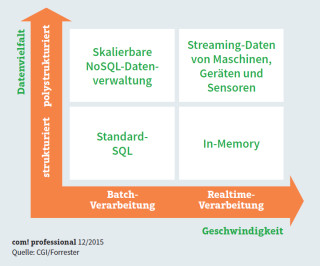
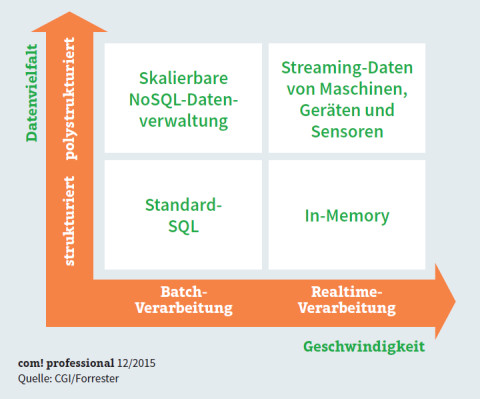
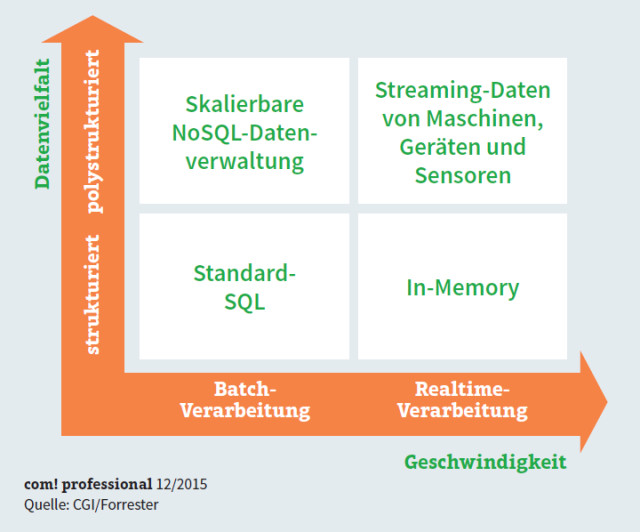 Das richtige Big-Data-Tool: Die Auswahl der passenden Tools orientiert sich an den Kriterien Datenvielfalt und Geschwindigkeit, mit der die Ergebnisse zur Verfügung stehen sollen.
Das richtige Big-Data-Tool: Die Auswahl der passenden Tools orientiert sich an den Kriterien Datenvielfalt und Geschwindigkeit, mit der die Ergebnisse zur Verfügung stehen sollen.
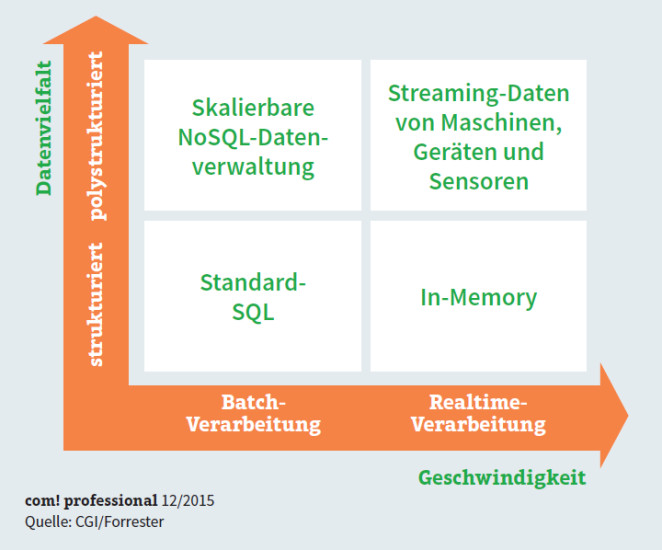
Neue Big-Data-Ansätze versprechen, den veränderten Anforderungen gerecht zu werden. Darunter finden sich Werkzeuge wie NoSQL und Hadoop, mit denen sich das klassische Data-Warehouse-Konzept erweitern und modernisieren lässt.
Skaleneffekte durch NoSQL
Relationale Datenbanken – wie sie bei Data Warehouses eingesetzt werden – können unter Last Schwierigkeiten mit der Performance bekommen. Typische Beispiele dafür sind Streaming-Media-Applikationen oder Webseiten mit hohem Lastaufkommen. Der Grund: Der bei SQL-Systemen erforderliche Verwaltungsmehraufwand bei der Skalierung führt ab einem bestimmten Punkt dazu, dass sich die Vorteile von SQL ins Negative kehren und die Performance deutlich sinkt. Dies gilt umso mehr, je größer der Skalierungsbedarf wird.
-
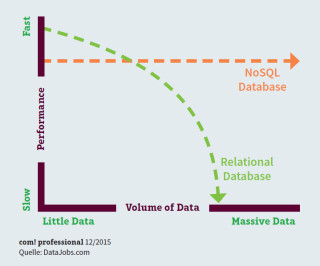
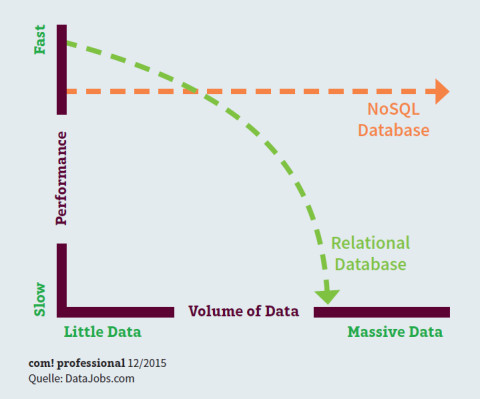
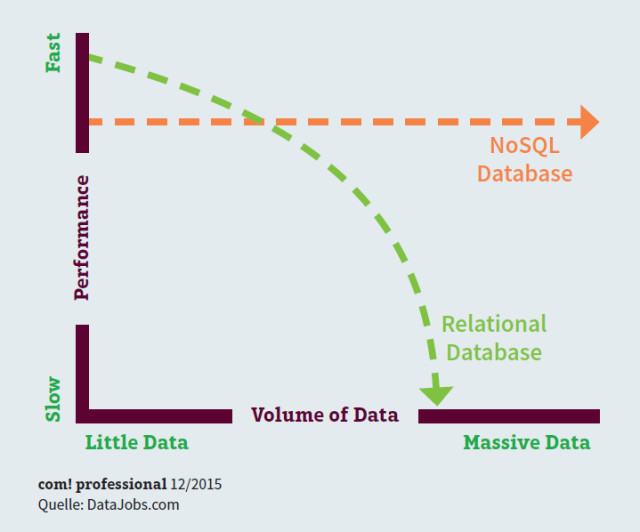 Skalierbarkeit von Datenbanken: Bei hohem Datenaufkommen sinkt die Leistung von traditionellen SQL-Datenbanken deutlich, während sie bei NoSQL-Datenbanken nahezu gleich bleibt.
Skalierbarkeit von Datenbanken: Bei hohem Datenaufkommen sinkt die Leistung von traditionellen SQL-Datenbanken deutlich, während sie bei NoSQL-Datenbanken nahezu gleich bleibt.
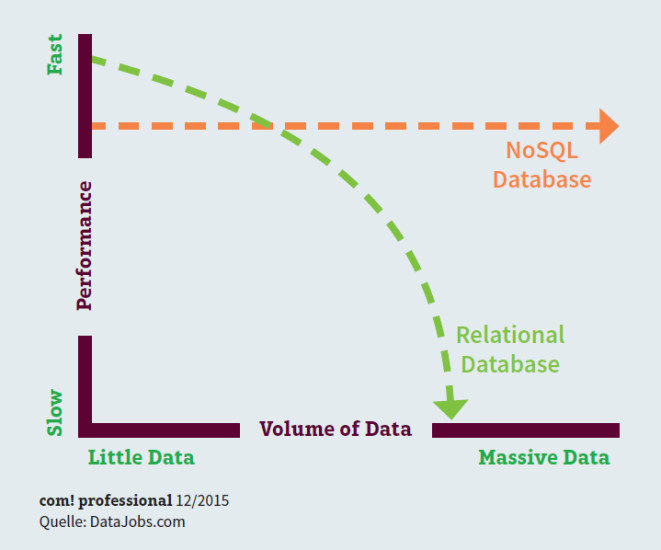
Durch ihre Skalierbarkeit und Flexibilität passen NoSQL-Systeme optimal zu den Anforderungen von Big Data.
Ein großer Nachteil von NoSQL liegt jedoch in der Abfrage der gespeicherten Daten. Anders als bei relationalen Datenbanken, wo es die einheitliche und sehr mächtige Abfragesprache SQL gibt, existiert bei NoSQL bislang kein einheitlicher Standard über die Datenbanken hinweg. Für Funktionen wie Ad-hoc-Reporting, Dashboards und OLAP-Analysen spielt daher SQL aktuell immer noch eine tragende Rolle. NoSQL-Systeme lassen sich jedoch auch mit Data-Warehouse-Technik kombinieren, um von beiden Ansätzen zu profitieren, was besonders für Fachbereiche interessant ist.
2. Teil: „Grenzen überwinden mit dem Hadoop-Framework“
Grenzen überwinden mit dem Hadoop-Framework
Hadoop ist ein Open-Source-Framework vor allem für die Speicherung, Aufbereitung und Analyse von polystrukturierten großen Datenmengen. Die Anwendungsgebiete reichen vom rein technischen Einsatz als Staging Area, um die relevanten Daten vor der Transformierung eins zu eins aus den Vorsystemen zu sammeln, über ressourcenintensive Simulationen im Sandboxing-Bereich bis zu Clickstream-Analysen.
HDFS untergliedert die Datensätze in Blöcke einer festen Größe und speichert sie redundant auf den in einem Cluster organisierten Server-Knoten. Durch die Redundanz ist es möglich, dass bei Ausfall eines Knotens die Verarbeitung der Datensätze an anderer Stelle wiederholt oder fortgesetzt werden kann.
Der Algorithmus MapReduce ist für die Berechnung der Daten zuständig. Dazu teilt MapReduce die gesamte zu untersuchende Datenmenge, die auf HDFS gespeichert wurde, ebenfalls in kleine Einheiten auf. Diese Einheiten werden dann in einer ersten Phase parallel und unabhängig voneinander auf den Datenknoten (DataNodes) bearbeitet, untersucht und als Zwischenergebnisse gespeichert. So werden zeitintensive Datentransfers über das Netzwerk minimiert, der Cluster skaliert sehr gut und insgesamt erhöht sich die Geschwindigkeit der Datenverarbeitung. Dann folgen, ebenfalls parallel, weitere Auswertungen und schließlich die Präsentation der Ergebnisse.
Hadoop wird vor allem dort eingesetzt, wo es darum geht, eine 360-Grad-Sicht auf Kunden zu haben, Weblogs, Maschinendaten aus der Fertigung oder Sensordaten auszuwerten. Mit Hilfe von Hadoop können die Fachbereiche – ohne IT-Abteilung – diese nur wenig strukturierten Daten selbst verarbeiten und analysieren.
3. Teil: „Hadoop-Cluster erfordern wenig Spezialwissen“
Hadoop-Cluster erfordern wenig Spezialwissen
Im Prinzip lassen sich alle Aufgaben, die berechenbar sind, durch den Einsatz von Hadoop-Clustern meistern. Eine der Möglichkeiten dabei ist, den dazu geeigneten Java-Programmcode zu erstellen. Manchmal ist das entsprechende Know-how in den Fachbereichen vorhanden. Ansonsten bieten IT-Dienstleister, beispielsweise CGI, Accenture, adesso, Capgemini oder msg Systems, die notwendige Unterstützung.
-
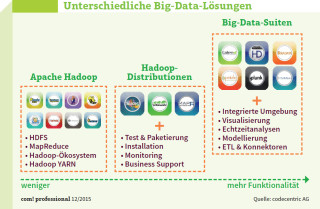
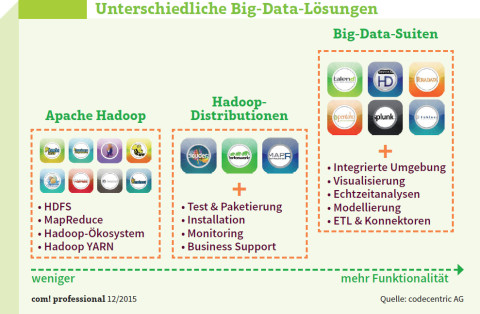
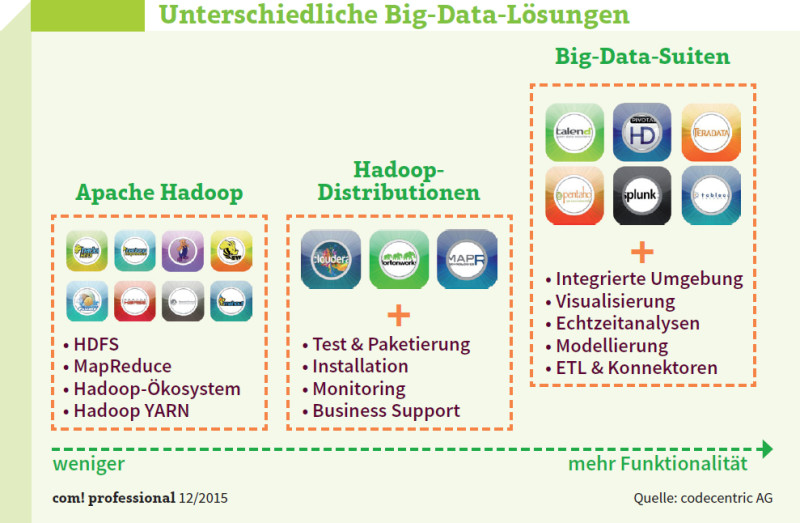
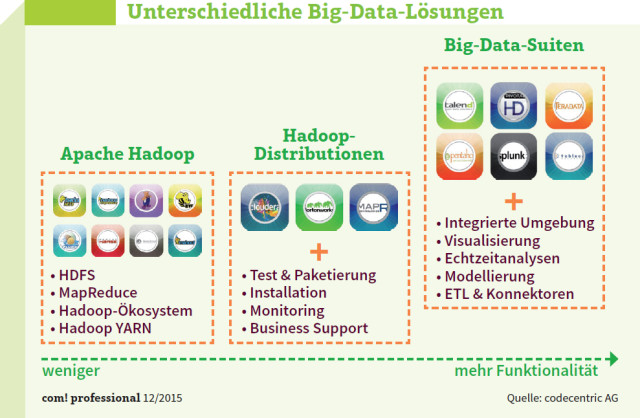 Unterschiedliche Big-Data-Lösungen: Hadoop unterteilt sich in Projekte, Distributionen und Big-Data-Suiten. Unterschiede gibt es bei Support, Funktionsumfang und Bedienkomfort.
Unterschiedliche Big-Data-Lösungen: Hadoop unterteilt sich in Projekte, Distributionen und Big-Data-Suiten. Unterschiede gibt es bei Support, Funktionsumfang und Bedienkomfort.
Latin-Framework dann in MapReduce-Jobs überführt.
Noch eine Option bietet Oracle Big Data SQL. Mit einer einzelnen Abfrage ist es damit möglich, auf Daten in relationalen Databases, in NoSQL-Datenbanken und in Hadoop zuzugreifen.
Hadoop-Einsatzbeispiele
Hadoop ist kein Ersatz für eine Data-Warehouse-Umgebung, wie sie von der IT-Abteilung betrieben, gepflegt und weiterentwickelt wird. Vielmehr ergänzt Hadoop die Data Warehouses. Während diese den strikten Regeln und Vorgaben einer unternehmensweiten IT-Governance folgen müssen, bietet eine Hadoop-Implementierung in einem Fachbereich mehr Spielräume in einer abgegrenzten Laborumgebung. Hier geht es traditionell um Exploration und interaktives Lernen.
-
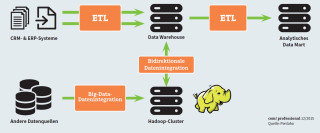
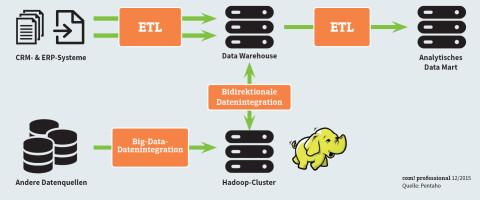
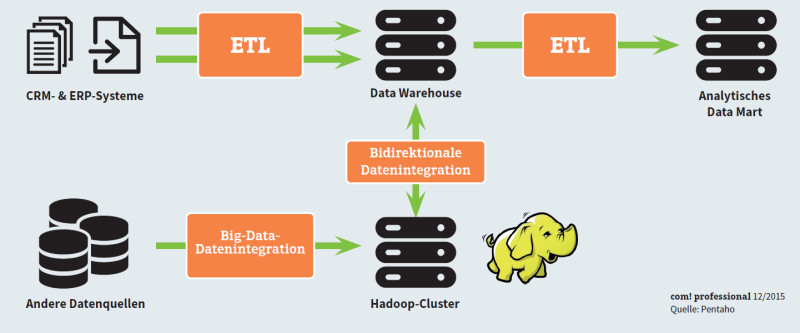
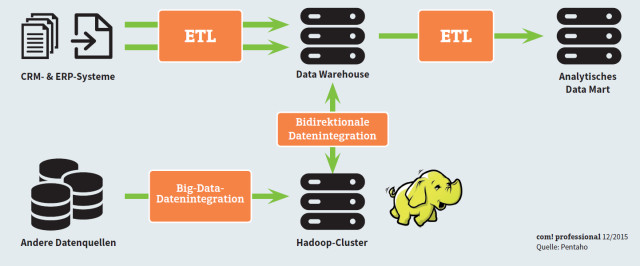 Data Warehouse mit Hadoop-Cluster: Hadoop kombiniert mit einer NoSQL-Datenbank ist kein Ersatz für die klassische Data-Warehouse-Umgebung, sondern stellt vielmehr eine sinnvolle Ergänzung und Erweiterung für die Verarbeitung großer Datenmengen dar.
Data Warehouse mit Hadoop-Cluster: Hadoop kombiniert mit einer NoSQL-Datenbank ist kein Ersatz für die klassische Data-Warehouse-Umgebung, sondern stellt vielmehr eine sinnvolle Ergänzung und Erweiterung für die Verarbeitung großer Datenmengen dar.
Im Bereich der Vertriebsförderung analysiert ein Automobilhersteller die Daten aus dem Pkw-Konfigurator im Web. Die Ergebnisse dienen als Grundlage, um gemeinsam mit Händlern die Verkaufsquote zu erhöhen. Die für Service zuständige Abteilung des Automobilherstellers wertet Daten zu Garantiefällen aus. Da es in der Vergangenheit deutliche Kritik von Kunden gab, die sich auch in verschiedenen Webforen widerspiegelte, ist es Aufgabe des Projekts, Lösungen zu finden, um die Produktqualität gezielt zu verbessern.
In all diesen Anwendungsszenarien unterstützt Hadoop die Fachbereiche dabei, das vorhandene, eher gering strukturierte Datenmaterial mit Hilfe von Hypothesen auszuwerten und Lösungsansätze zu entwickeln, die dann getestet, weiterentwickelt oder wieder verworfen werden.
Zeigt sich im Lauf der Zeit, dass sich daraus standardisierte Verfahren und Prozesse ergeben, finden sie Eingang in die IT-Governance. Dann ist die IT-Abteilung dafür zuständig.
Pilot-Features
Google Maps-Funktionen für nachhaltigeres Reisen
Google schafft zusätzliche Möglichkeiten, um umweltfreundlichere Fortbewegungsmittel zu fördern. Künftig werden auf Google Maps verstärkt ÖV- und Fußwege vorgeschlagen, wenn diese zeitlich vergleichbar mit einer Autofahrt sind.
>>
Codeerzeugung per KI
Code ist sich viel ähnlicher als erwartet
Eine Studie zeigt, dass einzelne Codezeilen zu 98,3 Prozent redundant sind, was darauf hindeutet, dass Programmiersprachen eine einfache Grammatik haben. Die Machbarkeit von KI-erzeugtem Code war also zu erwarten.
>>
JavaScript Framework
Hono werkelt im Hintergrund
Das JavaScript-Framework Hono ist klein und schnell. Ein weiterer Vorteil ist, dass Hono auf vielen Laufzeitumgebungen zum Einsatz kommen kann.
>>
Container
.NET 8 - Container bauen und veröffentlichen ganz einfach
Dockerfiles erfreuen sich großer Beliebtheit. Unter .NET 8 lassen sich Container für Konsolenanwendungen über den Befehl "dotnet publish" erzeugen.
>>