14.01.2020
Hintergrund
1. Teil: „Der Weg der KI führt über neue Prozessoren“
Der Weg der KI führt über neue Prozessoren
Autor: Klaus Manhart



Connect World / shutterstock.com
Spezial-Chips machen KI-Anwendungen leistungsfähiger - in Rechenzentren und Endgeräten. Aber ob cloudbasiert oder On-Premise: Beides hat seine Vor- und Nachteile.
-


 Vorbild Gehirn: Neuromorphe Chips (im Bild ein Intel-Modell) brechen komplett mit der herkömmlichen CPU-Architektur.Quelle:Intel
Vorbild Gehirn: Neuromorphe Chips (im Bild ein Intel-Modell) brechen komplett mit der herkömmlichen CPU-Architektur.Quelle:Intel

KI als Service hat den Vorteil, dass die großen Cloud-Provider zahlreiche innovative Technologien entwickelt haben, von denen Anwender sofort profitieren. Der Einstieg ist nicht allzu schwierig und es stehen zahlreiche Tools und Services zur Verfügung. Kosten-, Effizienz- und Compliance-Gründe können allerdings dafür sprechen, KI-Anwendungen im eigenen Haus zu entwickeln.
Weil für KI Unmengen von Daten an die Cloud-Dienstleister übertragen werden müssen, können die oft schmalen Netzwerkbandbreiten und hohe Latenzen die Ausführungseffizienz blockieren. Dies zeigt sich schon beim Inferencing, besonders aber beim Trainieren von Modellen (siehe Kasten auf Seite 96). Viele Firmen wollen oder dürfen zudem die für KI-Modelle notwendigen und oft sensiblen Trainingsdaten nicht nach draußen geben. „Gerade hinsichtlich Cyberrisiken bestehen bei deutschen Unternehmen Bedenken, etwa was den Diebstahl sensibler Daten oder Algorithmen anbelangt“, betont Ralf Esser, Leiter TMT Insights Deutschland bei Deloitte. Als gravierendste Herausforderungen bei KI-Initiativen nannten die für eine Deloitte-Studie befragten deutschen Firmen an erster Stelle datenbezogene Probleme wie Datenschutz.
Die Rolle von GPUs
Es gibt also einige Gründe, eine eigene KI-Infrastruktur aufzubauen. Doch auch hier warten große Herausforderungen. Das Training der Modelle beim Machine Learning ist äußerst rechenintensiv. Server-, Storage- und Netzwerk-Infrastrukturen müssen die riesigen dafür notwendigen Datenmengen und die anspruchsvollen Machine-Learning-Verfahren bewältigen können. Ein Training auf gängiger serieller Hardware kann sehr lange dauern oder überhaupt nicht mehr in akzeptabler Zeit durchführbar sein. Werden die Berechnungen verteilt und gleichzeitig ausgeführt, reduziert sich der zeitliche Aufwand immens. Hier kommen Graphic Processing Units (GPUs) ins Spiel.
Wie sich in den letzten Jahren herausstellte, eignen sich die GPUs nicht nur für Grafikaufgaben, sondern auch für die beschleunigte Berechnung neuronaler Netze. Benötigt ein kleiner Datensatz auf einer klassischen CPU eine Trainingszeit von drei bis vier Minuten, so braucht er bei Verwendung einer GPU nur einige Sekunden. Bei Deep Learning, wo der Trainingsaufwand besonders hoch ist, können sich Trainingszeiten mit großen Datensätzen von mehreren Wochen auf wenige Tage verringern. Grafikprozessoren nehmen deshalb heute bei KI eine zentrale Rolle ein. Der Markt bietet inzwischen auch speziell für KI optimierte Grafikkarten an. Dabei können Hunderte von Recheneinheiten parallel Berechnungen durchführen und bringen es so auf eine Rechenleistung von weit über 100 TeraFLOPS. Die führenden Server-Hersteller nutzen heute oft Tesla- oder Volta-GPUs von Nvidia, um Systeme für KI- und analytische Anwendungen zu optimieren. Viele Hersteller bauen etwa in ihre x86-Server Volta-GPUs als „KI-Beschleuniger“ ein - mit nativer GPU-Unterstützung über eine direkte Verbindung zum Mainboard.
2. Teil: „KI am Edge“
KI am Edge
-
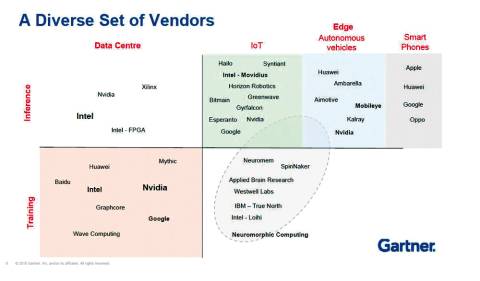
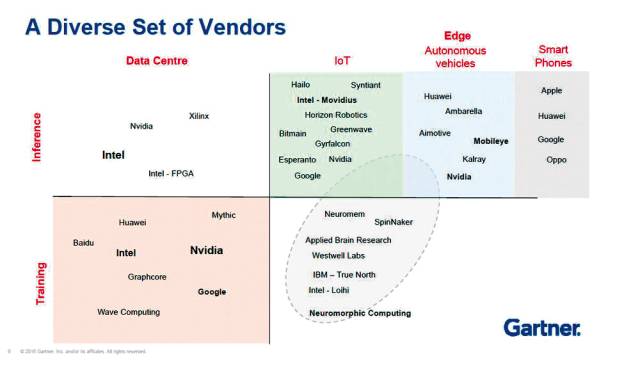
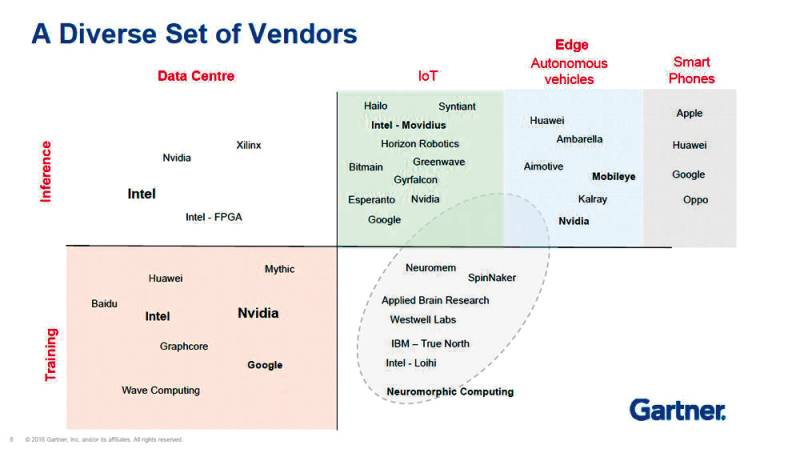
Ordnung nach Zweck: Gartner ordnet die Hersteller von KI-Prozessoren in die Bereiche „Training“ und „Inference“ ein. Besonders spannend: der Teilbereich „Neuromorphic Computing“. Quelle:Gartner
Das belastet nicht nur die Rechenzentren mit hohem Energieverbrauch und steigenden Kosten. Die stromfressenden GPUs behindern vor allem auch die Verlagerung von KI-Anwendungen an den Edge direkt in die Geräte. Das Problem: Edge-Devices wie Kameras, IoT-Geräte wie Sensoren, Medizin-Equipment und andere autonome Geräte sind oft auf Batterien angewiesen, deren Betriebsdauer durch rechenintensive KI-Module stark limitiert würde.
Dass die KI lokal verfügbar ist, ist aus mehreren Gründen notwendig. So müssen IoT- und Edge-Devices oft sofort reagieren - was schmale oder fehlende Cloud-Bandbreiten und Latenzen verhindern. Beispiel autonomes Fahren: Würden in einer Gefahrensituation die Sensordaten erst in die Cloud übertragen, dort interpretiert und dann eine Anweisung zurückgeschickt, wäre ein Unfall wahrscheinlich längst passiert. Die Entscheidung, ob gebremst werden soll, wenn ein Kind auf die Fahrbahn rennt, lässt sich nicht in die Cloud auslagern.
Dabei dürfte künftig nicht nur das Inferencing am Edge betrieben werden. Auch KI-Trainingsdurchläufe können sich im Edge-Computing etablieren. Die neu gewonnenen Daten lassen sich so in schlanker Form an die Cloud übermitteln. Dort wird dann das zentrale Modell mit den neuen Daten von Millionen von IoT-Geräten im Einsatz aktualisiert.
Intelligente Smartphones
Man kommt also nicht umhin, KI auch lokal einzusetzen. Es liegt deshalb nahe, spezielle KI-Chips zu entwickeln, die nur die notwendigen Funktionen beherrschen und besonders energiesparsam sind bei gleichzeitig hoher Leistungsfähigkeit. So könnte ein Großteil der Daten direkt vor Ort ressourcenschonend und in Echtzeit verarbeitet werden.
Der Bedarf an KI-optimierten Chips kommt aber auch noch aus einer anderen Ecke - von den Smartphone-Herstellern. Viele KI-gestützte Anwendungen auf Smartphones wie digitale Assistenten sind auf die Rechenzentren ihrer Anbieter angewiesen. Sie erfordern eine Internetverbindung und der notwendige Up- und Download der Daten kostet Zeit, was viele Anwendungsbereiche ausschließt. Smartphone-Hersteller gehen deshalb ebenfalls dazu über, KI-optimierte Prozessoren in ihre Geräte zu stecken. Als Erster hat Huawei mit dem Mate ein Smartphone herausgebracht, dessen Prozessor Kirin 970 mit einer Neural Processing Unit (NPU), einer speziellen Recheneinheit für KI, ausgestattet ist. Die NPU soll rechenintensive Aufgaben wie Bild- und Spracherkennung bis zu 20-mal schneller erledigen als herkömmliche CPUs. Auch Apple hat den neuesten iPhones eine KI-Einheit spendiert. Sie wird für Face ID gebraucht und erkennt nach einer kurzen Lernzeit das Gesicht des Nutzers. Andere Hersteller wie Google und Samsung setzen in ihren Smartphones ebenfalls auf KI-optimierte Chips.
Für viele Aufgaben und Assistenzfunktionen müssen die Endgeräte allerdings weiter auf die Cloud zugreifen, denn die Fähigkeiten der lokalen KI-Einheiten sind bislang eher rudimentär. Mit steigender Rechenleistung und Speicherkapazität soll in den kommenden Jahren aber immer mehr direkt auf den Geräten ausgeführt werden.
3. Teil: „Höhenflug am Chip-Markt“
Höhenflug am Chip-Markt
Die Anforderungen an KI-optimierte Chips sind damit sehr vielfältig. Sie sollen zum einen in den Rechenzentren das Training effizienter, schneller und energiesparender machen. Zum anderen sollen sie die KI-Rechenleistung raus aus den zentralen Data-Centern rein in die smarten Geräte transformieren. Dabei soll sowohl das Inferencing als auch das Training unterstützt werden. Wegen dieser Diversität der Einsatzszenarien gibt es auch nicht den einen KI-Chip, sondern verschiedene Designs und Ansätze.
Das Konglomerat unterschiedlicher Anforderungen spiegelt sich derzeit am Markt für KI-Chips wider - mit positiven Konsequenzen für die Chip-Branche. Laut der aktuellen PwC-Studie „Opportunities for the global semiconductor market“ sorgt KI für einen kräftigen Aufschwung in der Halbleiterindustrie. Der Studie zufolge ist vor allem der Automobilsektor ein Wachstumstreiber für Halbleiter mit KI-Unterstützung.
Den KI-bedingten Höhenflug erleben nicht nur die großen Chip-Hersteller wie Intel oder Nvidia. Auch viele kleine Start-ups engagieren sich in diesem Umfeld. Sie alle hoffen auf eine goldene Zukunft, wenn es ihnen gelingt, ihre Ideen erfolgreich in Produkte für wichtige Marktsegmente umzusetzen. Besonders aktiv sind chinesische Start-ups sowie dort etablierte Hersteller wie Huawei. Weiterhin treten Big Player wie Tesla, Facebook oder Amazon auf, die angekündigt haben, für ihre spezifischen Belange eigene KI-Chips zu entwickeln. Elektroauto-Pionier Tesla will zum Beispiel die Prozessoren für die Selbstfahrfunktionen seiner Autos künftig in Eigenregie produzieren, wie Tesla-Chef Elon Musk kürzlich mitteilte.
Der Ansatz, spezielle Prozessoren für KI-Anwendungen zu entwickeln, ist nicht ganz neu. Die erste Generation von KI-Prozessoren, zu denen Googles erste Tensor Processing Unit (TPU) und Nvidias Kepler-GPUs zählen, verfügten über parallel arbeitende Rechenwerke, wobei die theoretisch mögliche Maximalleistung praktisch kaum erreicht wurde. Der Flaschenhals war die Speicheranbindung. Die zweite Chip-Generation - etwa Googles TPU v2, Nvidias Volta-GPUs und Microsofts Brainwave-Chip - hatte große und schnelle Speicherchips.
Ordnung im Chip-Chaos
Derzeit rufen Konzerne wie Google, Amazon und Alibaba, aber auch Prozessor-Spezialisten wie Intel, ARM und Nvidia die dritte Generation von KI-Chips aus. Sie heißen Tensor Processing Unit, Neural Network Prozessor, neuromorpher Prozessor oder Visual Processing Unit und sollen die KI auf die nächste Stufe heben. Gartner hat den aktuellen Wildwuchs an KI-Prozessoren etwas geordnet und klassifiziert die KI-Chips in Einheiten für Training und Inferencing in der einen Dimension und Rechenzentrums- und Edge-, IoT- und Smartphone-Prozessoren in der anderen.
Im Data-Center-Segment sind vor allem Intel, Nvidia und Google die Big Player. Intels Nervana-NNP-Chips konkurrieren hier mit Googles Tensor-Prozessoren, Nvidias NVDLA und Amazons AWS-Inferentia-Chips. Intel konzentriert sich mit Nervana NNP-T und Nervana NNP-I auf Aufgaben im Bereich Machine Learning im Data-Center. Der Nervana NNP-T übernimmt das Training eines KI-Modells mittels Big Data. Für das Implementieren der Trainingsdaten in den KI-Workflow ist dann der NNP-I zuständig. Die beiden Chips ergänzen sich und sollen komplementär zum Einsatz kommen. (siehe nebenstehendes Interview). Huawei hat mit dem Ascend 910 ebenfalls einen Spezialprozessor für Data-Center zum Trainieren von KI-Modellen entwickelt. Der Ascend 910 wird als großer Cluster im Server eingesetzt. Laut Hersteller ist er der weltweit leistungsfähigste KI-Prozessor, der auf Machine Learning ausgerichtet ist, und schlägt die weitverbreitete Nvidia-GPU Tesla V100 - eine Art Referenz für KI-Prozessoren - um Längen. Das Gegenstück, der Ascend 310, ist Spezialist für das Inferencing und soll das Erlernte in die Tat umsetzen.
4. Teil: „Neuromorphe Hardware“
Neuromorphe Hardware
Inferencing im Edge- und IoT-Segment - ist der Spielplatz vieler Start-ups. Zwei Beispiele: Esperanto Technologies aus Barcelona etwa hat den leistungsfähigen KI-Chip ET-Maxion und den kleineren, energiesparsamen ET-Minion entwickelt. Das französische GreenWaves Technologies will IoT-Prozessoren schaffen, die mit Batterien auskommen, also keine eigene Stromzuführung benötigen. Daneben mischen auch hier die Großen mit. Die Google Edge TPU etwa ist kleiner als eine 1-Cent-Münze und kann in Edge-Szenarien eingesetzt werden. Der kleine Ableger der größeren Cloud-Variante beschleunigt als Edge-TPU das Inferencing, also das Anwenden der Modelle. Intels Movidius Myriad 2 Visual Processing Unit (VPU) ist ebenfalls optimiert für Devices mit geringer elektrischer Leistung wie Kameras oder Drohnen und übernimmt das Inferencing im Deep Learning Network.
Mit am interessantesten in der Gartner-Klassifikation sind im Segment rechts unten die neuromorphen Prozessoren. Diese Chips wenden sich komplett von der klassischen CPU-Architektur ab: Wie im menschlichen Gehirn Neuronen über Synapsen verknüpft sind, werden bei ihnen viele gleiche Einheiten miteinander verbunden, die kollektiv zusammenarbeiten. „Neuromorphe Hardware bezeichnet Computer oder Komponenten, die aus hochgradig vernetzten parallelen synthetischen Neuronen und Synapsen dem Gehirn nachempfundene neurologische oder künstliche neuronale Netze nachbilden“, heißt es bei Fraunhofer. Im True North von IBM und im Loihi von Intel ist dieser neuromorphe Ansatz realisiert. Diese Chips verfügen über ein eigenes Netz aus künstlichen Neuronen und Synapsen. Sie sind selbstlernend, ohne extra trainiert werden zu müssen. Gartner-Analyst Alan Priestley sieht in den Neuromorphic-Prozessoren die Zukunft des KI-Processings. Allerdings stehe es in den Sternen, ob dieses neue Computing-Paradigma überhaupt imstande sei, dem maschinellen Lernen durchgreifend voranzuhelfen. „Die Erwartungen an die Technologie können sich durchaus als zu hoch erweisen“, warnt Priestley.
5. Teil: „Im Gespräch mit Marcus Gloger und Tanjeff Schadt von PwC“
Im Gespräch mit Marcus Gloger und Tanjeff Schadt von PwC
-
 Tanjeff Schadt: Director bei PwC Strategy &Quelle:PwC Strategy &
Tanjeff Schadt: Director bei PwC Strategy &Quelle:PwC Strategy &
com! professional: Laut Ihrer Studie wird das Segment der KI-Prozessoren immer bedeutsamer. Wozu braucht es KI-Chips?
Tanjeff Schadt: Die KI-Workloads sind sehr heterogen. Um sie mit optimaler Performance, Power und möglichst geringen Kosten bedienen zu können, sind spezifische Architekturen notwendig. Neben klassischen Architekturen auf CPU-Basis entstehen neuartige Designs wie sie die Neuromorphic Chips von Intel oder Graphcore sowie die TPUs von Google mitbringen.
Diese Prozessoren können spezielle KI-Tasks effizienter abbilden als andere Architekturen und kommen gerade auf den Markt.
com! professional: Solche anwendungsspezifischen Chips waren bislang aber doch eher rar gesät?
Marcus Gloger: Ja, aber der Trend bei Herstellern wie Intel oder AMD geht zu anwendungsspezifischen Prozessoren. Dieses Rechnerarchitektur-Design ist, wenn man so möchte, eine Fortsetzung von Moore’s Law. Sie können damit den Stromverbrauch um einen Faktor 10 reduzieren und zugleich die Performance deutlich steigern.
com! professional: Also profitieren nicht nur KI-Anwendungen, sondern auch die Infrastruktur?
Schadt: Genau, das nützt auch dem Rechenzentrum und den Servern, in denen der Stromverbrauch zunehmend wichtig wird. In der Server-Welt lassen sich die traditionell monolithischen CPUs dann um
hochperformantes Memory ergänzen, so entsteht ein Chiplet für Künstliche Intelligenz. Wobei wir überzeugt sind, dass diese chipbasierten KI-Funktionalitäten mittelfristig Standard und in den klassischen CPU-Kern integriert werden.
-


 Marcus Gloger: Partner bei PwC Strategy &Quelle:PwC Strategy &
Marcus Gloger: Partner bei PwC Strategy &Quelle:PwC Strategy &

com! professional: Die Funktionalitäten der spezialisierten KI-Chips werden in normale Prozessoren integriert?
Gloger: Wir gehen davon aus, dass in nicht allzu ferner Zukunft 60 bis 80 Prozent der Rechenleistung tatsächlich KI-Rechenleistung sein wird.
Standard-KI-Tasks, also breit angewendete KI-Aufgaben, werden daher zunehmend in den regulären CPU-Kern hineinwandern. Ich rechne hier mit einer Zeitspanne von fünf bis zehn Jahren. Das ist der Zyklus, den wir in der Vergangenheit beobachten konnten, etwa bei der Integration von numerischen Co-Prozessoren in CPUs. Man sieht ja auch bereits erste Tendenzen, wie das funktionieren kann.
com! professional: Welche Tendenzen meinen Sie?
Gloger: Apple hat in seinen A13-Chip im iPhone eine Neural Engine, beispielsweise für die Gesichtserkennung, eingefügt. Die Engine ist inzwischen in den Chip integriert. Die Frage ist, ob diese dann zukünftig sogar in das gleiche Silizium eingebettet wird wie der eigentliche Kern, sogenannte Embedded KI.
com! professional: Gilt das für alle KI-Funktionalitäten?
Schadt: Nein. Es wird weiterhin sehr spezielle KI-Anwendungen geben, für die die dedizierten KI-Chips sinnvoll sind. Neuromorphe Prozessoren für Deep Learning wären solche Spezial-Chips. Diese lassen sich schwer in eine normale CPU integrieren, weil ihre Architektur der Funktionsweise des menschlichen Gehirns nachempfunden ist und sich damit fundamental vom traditionellen sequenziellen Processing eines Von-Neumann-Chips unterscheidet.
6. Teil: „Im Gesrpäch mit Stephan Gillich von Intel“
Im Gesrpäch mit Stephan Gillich von Intel
-
 Stephan Gillich: Director of Artificial Intelligence and Technical Computing der Intel EMEA Datacenter GroupQuelle:Intel
Stephan Gillich: Director of Artificial Intelligence and Technical Computing der Intel EMEA Datacenter GroupQuelle:Intel
com! professional: Für KI-Aufgaben optimierte Chips scheinen die neuen Sterne am Prozessorhimmel zu sein. Wie sehen Sie die Rolle von KI-Prozessoren bei KI-Workloads?
Stephan Gillich: Ich muss Sie gleich enttäuschen. Viele denken, dass man für KI immer besondere Akzeleratoren braucht. Das ist in der Regel nicht der Fall. Die enorme Leistungsfähigkeit von Prozessoren, des Data Storage und von Hardware allgemein sind natürlich die Grundlage dafür, dass man jetzt praktisch KI machen kann. Was aber auch damit verbunden ist, ist vor allem die Software, ohne die ja kein Chip funktionieren kann.
com! professional: Sie denken jetzt an KI-Entwicklungs-Tools?
Gillich: Ja, Frameworks und Entwicklungswerkzeuge wie TensorFlow, Caffe oder MxNet sind mindestens genauso wichtig, damit KI funktioniert. Wir haben die Software-Stacks deshalb entsprechend optimiert, sodass sie auf allgemeinen CPUs sehr gut funktionieren. Und wir bauen jetzt auch spezielle Instruktionen und spezielle Technologien in die CPUs ein.
com! professional: Was für KI-Features bauen Sie in die CPUs ein?
Gillich: Die aktuelle Intel-Xeon-Scalable-Generation hat ein Feature, das sich DL Boost nennt und das Inferencing beschleunigt. Diese CPUs decken eine große Bandbreite ab. Wir sehen ja in der Praxis, dass die Kunden ihre Rechner etwa im Data-Center-Bereich für sehr viele Zwecke einsetzen wollen - für KI vielleicht auch, aber nicht ausschließlich. Und deswegen nimmt das einen relativ breiten Raum bei unserer Entwicklung ein.
com! professional: Trotzdem gibt es Anforderungen, für die man besser auf spezialisierte Chips zurückgreift.
Gillich: Die gibt es natürlich auch. Die Intel-Movidius-Myriad-2-VPU ist optimiert für Inferencing mit einem Deep Learning Network im Bereich visuelle Anwendungen - und zwar bei nur geringer elektrischer Leistung wie sie in Devices, in Kameras und in Drohnen zur Verfügung steht. Eine Organisation nutzt zum Beispiel die Unit für Bilderkennung im afrikanischen Busch. Dort müssen die Kameras sehr lange mit einer begrenzten Batterieleistung auskommen.
com! professional: Welche Prozessoren decken Realtime-Anforderungen ab?
Gillich: Da sind FPGAs gut geeignet für. FPGAs waren schon immer für Realtime-Anwendungen sehr gut geeignet wegen ihrer anpassbaren Architektur, und das gilt auch für KI-Anwendungen. Die werden etwa eingesetzt für Realtime-Anwendungen in Industriesteuerungen, aber auch in Rechenzentren.
com! professional: Neben dem Inferencing gibt es vor allem auf der Trainingsseite hohe Anforderungen.
Gillich: Die Trainingsseite wird oft überbewertet, auch wenn es natürlich Anwendungen und Firmen gibt, die in bestimmten Fällen sehr hohe Trainings-Workflows haben. Wir entwickeln dafür spezielle Architekturen wie den Intel NNP-T. Der Prozessor ist noch nicht verfügbar, aber die Entwicklung schon sehr weit fortgeschritten. Eine weitere in Entwicklung befindliche KI-Architekur ist der Intel NNP-I. Der Chip ist darauf spezialisiert, das Inferencing von Deep Learning sehr effizient durchzuführen. Das ist für Kunden interessant, die in ihrem Gesamt-Workload sehr viele Auswertungen mit KI machen wollen.
com! professional: Wie sehen Sie Zukunft dieser KI-Chips?
Gillich: Der Gesamtmarkt wird zunehmen, da wir mehr KI-Anwendungen in allen Industrie- und Forschungsfeldern sehen werden. Im Gesundheitswesen, in der Produktion, im Manufacturing bestehen vielfältige Einsatzmöglichkeiten. Entsprechend vielfältig sind auch die Anforderungen: Ob Sie Anwendungen eher im Feld haben oder auf einem Device oder im Data-Center oder irgendwo dazwischen auf einer Gateway-Architektur - es herrschen höchst unterschiedliche Anforderungen. Und mit verschiedenen Architekturen, sowohl von der CPU- als auch von der Beschleuniger-Seite her, will Intel ein breites Spektrum dieser Anforderungen abdecken.
Codeerzeugung per KI
Code ist sich viel ähnlicher als erwartet
Eine Studie zeigt, dass einzelne Codezeilen zu 98,3 Prozent redundant sind, was darauf hindeutet, dass Programmiersprachen eine einfache Grammatik haben. Die Machbarkeit von KI-erzeugtem Code war also zu erwarten.
>>
Cloud-PBX
Ecotel erweitert cloud.phone-Lösung um MS Teams-Integration
Die Telefonanlage aus der Cloud von Ecotel - ein OEM-Produkt von Communi5 - cloud.phone, ist ab sofort auch mit Microsoft-Teams-Integration verfügbar.
>>
Personalien
Komsa stellt sich im Solution-Segment neu auf
Der Distributor richtet sein UC- und Cloud-Business neu aus und stellt mit Christof Legat einen neuen Vice President UC-Solutions vor, Friedrich Wahnschaffe ist als Vice President für das MS-Cloud-Geschäft von Komsa in Deutschland verantwortlich.
>>
Untersuchung
Amerikaner sehen KI als Risiko für Wahlen
Die Unterscheidung zwischen echten Infos und KI-Inhalten fällt vielen politisch interessierten US-Amerikanern schwer, wie eine Studie des Polarization Research Lab zeigt.
>>