15.11.2017
Grundlagen
1. Teil: „So funktioniert die Blockchain“
So funktioniert die Blockchain
Autor: Patrick Schidler



Zapp2Photo / Shutterstock.com
Ist die Blockchain ein reiner Hype oder eine technologische Revolution? Patrick Schidler von Microsoft Deutschland zeigt, was hinter der dezentralen Datenbank steckt.
Dieser Artikel wurde von Patrick Schidler verfasst, Product Manager Blockchain & Data Platform, Cloud & Enterprise Group bei Microsoft Deutschland.
Um zu verstehen, was Blockchains sind, welche Eigenschaften sie haben und was sie so besonders macht, schauen wir uns zunächst an, welche Probleme mit ihnen gelöst werden sollen.
Heute speichern Unternehmen ihre Daten in der Regel in Datenbanken, die durch verschiedene Sicherheitsmechanismen vor unbefugtem Zugriff geschützt sind. So wird zum Beispiel durch Benutzername und Kennwort sichergestellt, dass nur die Personen Zugriff auf die Datenbasis haben, die auch tatsächlich dazu berechtigt sind. Außerdem wird der Datenbank-Server geschützt, das gesamte Netzwerk, in dem sich der Datenbank-Server befindet, und so weiter.
Die Datenbank wird also innerhalb von vertrauenswürdigen Grenzen gehalten und eine Überschreitung dieser Grenzen durch Externe ist nicht ohne Weiteres möglich. Für viele rein interne Anwendungsfälle ist das meist auch ausreichend, kompliziert wird es jedoch, wenn mit Externen zusammengearbeitet werden soll.
Köln und/oder München?
Nehmen wir als Beispiel zwei Verkehrsbetriebe, einen in Köln und einen in München: Beide bieten grundsätzlich den gleichen Dienst an, nämlich die Personenbeförderung mit Bussen und Bahnen. Wenn ich als Kunde eine Monatskarte für die Busbeförderung habe, dann gilt diese meistens regional begrenzt, zum Beispiel nur in Köln.
-


 Beispiel Trambahn: Zwei Verkehrsverbünde zu verbinden ist höchst komplex. Die Blockchain könnte ein Lösung sein.Quelle:Siemens
Beispiel Trambahn: Zwei Verkehrsverbünde zu verbinden ist höchst komplex. Die Blockchain könnte ein Lösung sein.Quelle:Siemens

Der Verkehrsbetrieb in Köln hat alle Informationen über mich, die er braucht, um den monatlich fälligen Betrag von meinem Konto einzuziehen. Der Verkehrsbetrieb in München muss nur die von mir getätigten Fahrten melden und könnte dann anteilig an dem von mir entrichteten Monatsbeitrag beteiligt werden.
Da jeder Verkehrsbetrieb nun aber seine eigene Datenbank innerhalb der gezogenen Vertrauensgrenzen betreibt, ist der Datenaustausch zwischen den beiden gar nicht so einfach. Wenn ich zum Beispiel meine Fahrt in München antrete und meine Monatskarte präsentiere, müsste in der Datenbank in Köln nachgeschlagen werden, ob ich überhaupt berechtigt bin. Vielleicht habe ich ja meinen Monatsbeitrag nicht bezahlt oder mein Vertrag ist ausgelaufen. Hinterher müsste gemeldet werden, wie weit ich gefahren bin, damit der Verkehrsbetrieb den richtigen Anteil an meinem Monatsbeitrag erhält. Hier müsste sichergestellt sein, dass auch wirklich die richtige Strecke gewählt wird, und nicht etwa eine, die etwas länger ist und den Verkehrsbetrieb in München begünstigt. Außerdem muss sichergestellt sein, dass nicht mehr Fahrten gemeldet werden, als tatsächlich durchgeführt wurden.
2. Teil: „Clearingstelle als Mittelsmann …“
Clearingstelle als Mittelsmann …
Bereits die anfängliche Überprüfung meiner Fahrberechtigung würde erfordern, dass man aus München auf den Datenbestand in Köln zugreifen kann. Und da natürlich jemand mit einer Monatskarte in München auch in Köln fahren möchte, muss das auch andersherum möglich sein. Außerdem möchte man vielleicht nicht nur in München oder Köln fahren, sondern auch in Hamburg, Berlin und so weiter. Kurzum: Immer nur einen bidirektionalen Datenzugriff zwischen zwei Verkehrsbetrieben einzurichten sprengt den Rahmen des Machbaren.
-
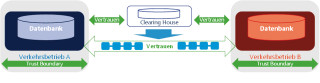

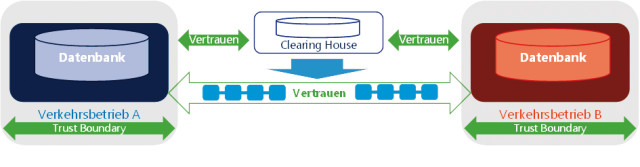 Transparenz: Sind alle Transaktionen für die Beteiligten transparent, kann die Clearingstelle als Mittelsmann entfallen.
Transparenz: Sind alle Transaktionen für die Beteiligten transparent, kann die Clearingstelle als Mittelsmann entfallen.
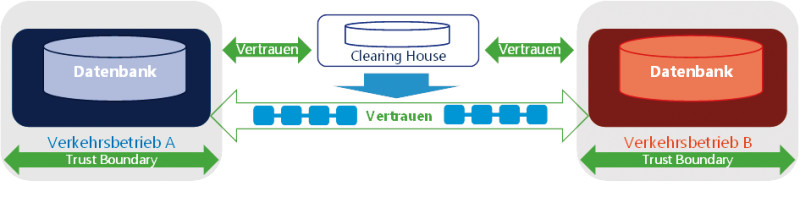
Wenn nun ein neuer Verkehrsbetrieb seine Dienste anbieten möchte, dann muss er nicht mehr die Schnittstellen mit allen anderen Unternehmen austauschen, sondern sich nur der Clearingstelle anschließen. Diese Clearingstelle genießt dabei das Vertrauen aller beteiligten Unternehmen, das heißt, sie stellt sicher, dass die dort verwalteten Daten auch korrekt sind, also zum Beispiel kein Abrechnungsbetrug möglich ist. Dazu führt sie eine Kopie der Daten, die für Abrechnung und Koordination benötigt werden. Solche Datenkopien haben natürlich den Nachteil, dass dezentral gespeicherte Daten konsistent gehalten werden müssen, die Datenbanken auch wieder abzusichern sind, separate Verfahren zur Einhaltung des Datenschutzes umgesetzt werden müssen und so fort.
… oder zentrale Datenbasis
Ein Ansatz, diese Komplexität in den Griff zu bekommen, wäre es, wenn alle Verkehrsbetriebe nicht mehr verschiedene Datenbanken nutzen würden, sondern alle auf eine zentrale Datenbasis zugreifen würden. Selbstverständlich könnte man den gesamten Datenbestand unterteilen, sodass meine persönlichen Kontodaten beispielsweise nur bei meinem Verkehrsbetrieb liegen und alle Fahrberechtigungen und getätigten Fahrten pseudonymisiert in einer gemeinsamen, großen Datenbank abgelegt werden. Statt also viele einzelne Datenbanken mit unterschiedlichen Datenständen zu haben, nutzen immer alle die gemeinsame Datenbank.
-

 Quelle: Statista 2017
Quelle: Statista 2017
Wenn nun alle die gleiche Datenbasis besitzen, kein Datenaustausch mehr nötig ist und das Vertrauen dadurch entsteht, dass jeder jederzeit alle Transaktionen auf Korrektheit prüfen kann, dann kann man sich die Frage stellen, wozu man überhaupt noch die Clearingstelle als Mittelsmann braucht. Die intuitive Antwort darauf lautet: Irgendwer muss ja auch diese zentrale Datenbank betreiben und koordinieren. Die Antwort könnte aber auch lauten: Die Clearingstelle braucht man gar nicht mehr, wenn die zentrale Datenbank eine Peer-to-Peer-Datenbank wäre, bei der keinem die Datenbank allein gehört, sondern jeder Teilnehmer zu jeder Zeit eine vollständige, konsistente Kopie der Daten hat.
3. Teil: „Wie ein Distributed Ledger hilft“
Wie ein Distributed Ledger hilft
Genau das ist die Idee hinter der sogenannten Distributed-Ledger-Technologie (DLT), also einem verteilten Transaktionsprotokoll. Da diese Peer-to-Peer-Datenbank so lange weiterexistiert, wie noch eine einzige Instanz aktiv ist, sie also keinem Einzelnen gehört, der die Kontrolle über den Lebenszyklus hat, spricht man manchmal auch von Shared Distributed Ledger, also einem gemeinsamen, verteilten Transaktionsprotokoll.
-
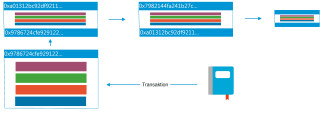
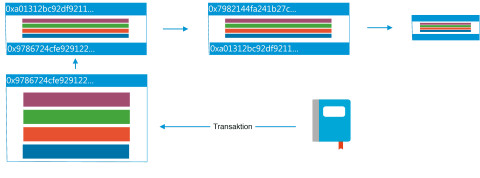
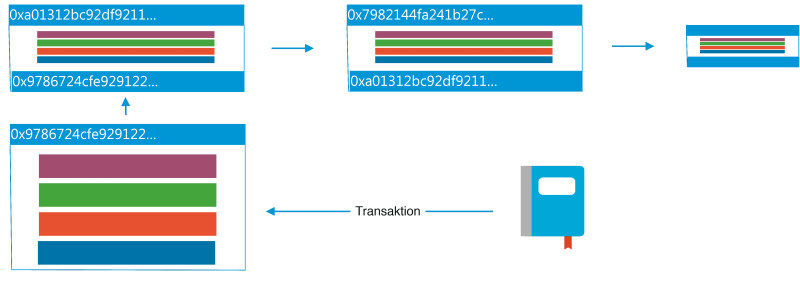
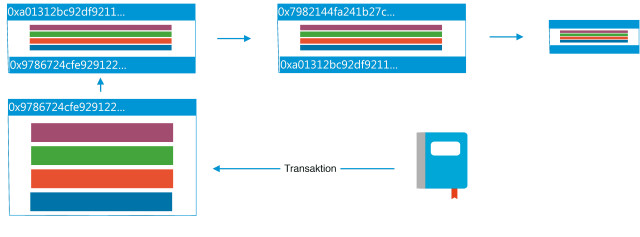 Herzstück der Blockchain-Technologie: Alle anfallenden Transaktionen werden in Blöcken zusammmengefasst und in einer dezentralen Datenbank erfasst.
Herzstück der Blockchain-Technologie: Alle anfallenden Transaktionen werden in Blöcken zusammmengefasst und in einer dezentralen Datenbank erfasst.
Man kann mathematisch zeigen, dass in einem dezentralen System eine Einigung über die Korrektheit von Transaktionen nur unter bestimmten Bedingungen erfolgen kann (wird oft als „Problem der byzantinischen Generäle“ bezeichnet). Die Aufgabe der DLT ist nun, sicherzustellen, dass fehlerhafte Transaktionen erkannt werden und nicht den Weg in das Transaktionsprotokoll finden.
Der Konsens
Üblicherweise ist eine weitere Eigenschaft der DLT, dass das Transaktionsprotokoll unveränderlich ist, das heißt, einmal erfasste Transaktionen können nicht mehr gelöscht werden. Es muss, vergleichbar mit der ordentlichen Buchhaltung, immer eine dokumentierte „Gegenbuchung“ erfolgen, um eine Transaktion rückgängig zu machen.
Für unser Beispiel bedeutet das, dass jeder Verkehrsbetrieb eine Kopie aller Daten besitzt und neue Fahrten aber erst als gültig und abrechenbar akzeptiert werden, wenn es einen Konsens unter den Beteiligten gibt, dass diese auch gültig sind. Dieses Verfahren wird als Consensus bezeichnet.
Damit jetzt nur Verkehrsbetriebe auf die Datenbank zugreifen können und nicht etwa unbeteiligte Dritte, wird diese Datenbank wieder abgesichert. So wird zum Beispiel über übliche Methoden wie etwa Authentifizierung oder Verschlüsselung sichergestellt, dass nur berechtigte Parteien an dem Peer-to-Peer-Protokoll teilnehmen können. In einem solchen Fall spricht man häufig auch von einem „Enterprise Consortium Network“, das heißt einem Netzwerk, das ausdrücklich den Mitgliedern eines Konsortiums vorbehalten ist. Rund um das Thema DLT haben sich in den vergangenen Jahren und Monaten eine Menge solcher Konsortien gebildet, unter anderem das B3i-Konsortium verschiedener großer Versicherungen oder R3, in dem sich neben diversen Banken auch Unternehmen wie Toyota und Microsoft wiederfinden.
Wenn man also über DLT spricht, dann spricht man nicht über eine konkrete Implementierung einer dezentralen Datenbank, sondern eher von dem Konzept der Kombination aus Peer-to-Peer-Netzwerken, dem Consensus-Verfahren, der Unveränderlichkeit des Transaktionsprotokolls und der Tatsache, dass die Datenbank von keinem einzelnen Unternehmen kontrolliert oder betrieben wird, sondern gleichermaßen (und in der Regel gleichberechtigt) von allen Mitgliedern eines bestimmten Kreises.
Die Implementierung erfolgt dann üblicherweise nicht auf Anwendungsebene, zum Beispiel für die Speicherung eines Monatstickets, sondern eher auf einer Protokollebene zum Austausch beliebiger Transaktionen. So kann die Datenbank auch für beliebige zukünftige Anwendungsfälle genutzt werden. Dies ist sicherlich ein großer Unterschied zu heutigen vergleichbaren Umsetzungen, wo bei der Zusammenarbeit von zwei oder mehr Unternehmen zum Beispiel konkrete Webschnittstellen für die Abwicklung bestimmter Geschäftsvorfälle definiert werden.
4. Teil: „Von DLT zu Blockchain“
Von DLT zu Blockchain
Der Aufbau eines Distributed Ledgers innerhalb eines Konsortiums erscheint nun nicht so kompliziert, denn die Vereinbarung von Protokollen zum Datenaustausch und die Sicherung des Zugangs können zwischen den Mitgliedern abgestimmt werden. Man kennt sich, es können Verträge geschlossen werden und man vertraut sich bis zu einem gewissen Grad auch; immerhin möchte man gemeinsame Geschäfte abwickeln. Das Revolutionäre entsteht eigentlich, wenn man sich Szenarien vorstellt, bei denen Geschäftsprozesse abgewickelt werden können, bei denen sich die Beteiligten weder kennen noch vertrauen.
-
 Blockchain-Konsortium R3: Zu den bekanntesten Mitgliedern zählen neben diversen Banken Toyota und Microsoft.
Blockchain-Konsortium R3: Zu den bekanntesten Mitgliedern zählen neben diversen Banken Toyota und Microsoft.
Was wäre nun, wenn ich wie im Beispiel mit den Verkehrsunternehmen versuchen möchte, diesen zentralen Zwischenhändler herauszunehmen? Wie stellen wir dann sicher, dass der Musiker und ich ein sicheres Geschäft abwickeln können, ohne dass wir einander kennen oder vertrauen können? Mit einer Blockchain ist so etwas möglich, und die Krypto-Währung Bitcoin (ursprünglich konzipiert von Satoshi Nakamoto, von dem bis heute keiner weiß, wer das eigentlich ist) ist ein gutes Beispiel dafür: Hier können Teilnehmer, die sich nicht kennen oder vertrauen, relativ einfach weltweit Geld transferieren, ohne dass es dazu einer Bank oder eines anderen Mittelsmanns bedarf.
Etwas Kryptografie
Um zu verstehen, wie das bei Bitcoin (und vielen anderen Blockchains) umgesetzt wird, müssen wir etwas tiefer in die Kryptografie einsteigen. Fangen wir dazu mit einer einfachen Bitcoin-Transaktion an, bei der wir einen bestimmten Betrag, gemessen in Bitcoin (BTC) und Satoshi, an eine andere Person überweisen (ein Satoshi entspricht dabei 10– 8 BTC, das heißt 0,00000001 BTC). Alles, was ich dafür kennen muss, ist die Adresse meiner sogenannten Wallet auf der Blockchain, das heißt des Portemonnaies, in dem ich meine Bitcoins aufbewahre, und die Adresse der Wallet, die die Bitcoins empfangen soll. Ich kann dabei nur dann Bitcoins aus meiner Wallet versenden, wenn ich vorher welche empfangen habe und ich über einen geheimen Schlüssel verfüge, mit dem ich die Entnahme autorisieren kann. Diesen Private Key muss ich also ebenfalls kennen, und die Bezeichnung suggeriert schon, dass hinter Bitcoin asymmetrische Kryptografie steckt.
-

 Quelle: World Economic Forum
Quelle: World Economic Forum
Eine einfache Transaktion, die wir nun unveränderlich in unserem Transaktionsprotokoll ablegen wollen, besteht im einfachsten Fall aus Quelladresse, Zieladresse und Betrag. Ich muss nun die Transaktion noch mit meinem privaten Schlüssel signieren und kann diese dann an alle Knoten im Netzwerk senden. Da jeder Knoten alle Transaktionen und Wallets kennt, kann jetzt jeder Knoten sehr einfach prüfen, ob sich in meiner Wallet noch ein ausreichend hoher Betrag befindet und ob die Signatur darauf schließen lässt, dass die Transaktion auch wirklich von dem Besitzer der Wallet autorisiert wurde. Wenn beides stimmt, kann die Transaktion als gültig in das Transaktionsprotokoll aufgenommen werden und das Geld wurde übertragen.
Dadurch, dass die Transaktion dauerhaft und unveränderlich in der Blockchain erfasst wurde, wird ein grundlegendes Problem gelöst, nämlich das sogenannte Double-Spending-Problem. Anders als bei Geldscheinen, die sich nicht mehr in meinem Besitz befinden, wenn ich damit bezahle, kann ich Daten grundsätzlich weitergeben und dabei trotzdem eine Kopie davon behalten. Bezogen auf eine digitale Währung hieße das, dass ich mit einer digitalen Münze bezahle und zur gleichen Zeit diese digitale Münze auch an jemand Zweites geben könnte. Wenn das möglich wäre, könnte sich jeder Teilnehmer beliebig viel Geld erzeugen und die Währung hätte sehr schnell keinen Wert mehr.
5. Teil: „Organisation in Blöcken“
Organisation in Blöcken
Wie aber wird gewährleistet, dass einmal gespeicherte Transaktionen nicht mehr verändert werden können? Dazu muss man sich die Art und Weise anschauen, wie Bitcoin die Transaktionen speichert und die der Blockchain auch ihren Namen gibt: Im Bitcoin-Netzwerk gibt es spezielle Knoten, sogenannte Mining Nodes, die Transaktionen in Blöcken zusammenfassen. Aufgrund der Verteilung der Knoten nimmt dabei nicht jeder Knoten die gleichen Transaktionen auf, wichtig ist nur, dass die Reihenfolge der Transaktionen ihren entsprechenden Zeitstempeln entspricht. Nur Transaktionen in abgeschlossenen Blöcken werden als unveränderlich angesehen. Solange sich eine Transaktion also nicht in einem solchen Block befindet, gilt sie nicht als ausgeführt.
-
 Azure Marketplace: Auf Microsofts Cloud-Plattform finden sich rund 40 Blockchain-Implementierungen und -Werkzeuge.
Azure Marketplace: Auf Microsofts Cloud-Plattform finden sich rund 40 Blockchain-Implementierungen und -Werkzeuge.
Dieser Prozess wird im Allgemeinen als Proof of Work bezeichnet und bei Bitcoin und anderen Krypto-Währungen auch als Mining. Der allgemeine Name rührt daher, dass mit dem Ergebnis nachgewiesen wird, dass man einen bestimmten Anteil an Rechenleistung erbracht hat, um das Rätsel zu lösen. Warum ist das so wichtig? Das Erzeugen gültiger Blöcke soll so teuer sein (etwa in Form von Stromverbrauch), dass es sich nicht lohnt, Blöcke mit gefälschten Transaktionen zu erzeugen. Stattdessen wird man für das Erzeugen gültiger Blöcke belohnt, indem man einen Anteil an Bitcoins für die eigene Arbeit erhält. Dazu darf man eine eigene Transaktion in den neuen Block aufnehmen, die „aus dem Nichts“ einen vorher definierten Betrag in die eigene Wallet überträgt. Außerdem darf man bei Bitcoin Transaktionsgebühren einbehalten.
Warum lohnt es sich dann nicht, zu betrügen? Jeder andere Knoten hat ja eine Kopie aller Transaktionen und kann sehr leicht feststellen, ob ein Block valide Transaktionen enthält. Wenn ein Knoten betrügen möchte, müsste er gefälschte Transaktionen in einem neuen Block zusammenfassen, das rechenintensive (teure) Rätsel lösen und dann den neuen Block den anderen Knoten als „abgeschlossen und gültig“ präsentieren. Diese nehmen aber einen neuen Block nur dann auf, wenn zum einen das Rätsel richtig gelöst wurde und zum anderen auch alle Transaktionen in dem Block valide sind. Das bedeutet, dass man zwar einen neuen gefälschten Block in das Netzwerk schicken kann, aber niemand wird diesen Block als gültig akzeptieren. Das bedeutet auch, dass man keine neuen Bitcoins erhält, die man nutzen könnte. Man bleibt auf den Kosten zur Lösung des Rätsels sitzen.
Organisation als Kette
Jetzt kann man argumentieren, dass die Rechenleistung immer billiger wird und es sich dann doch irgendwann lohnen könnte, das Netzwerk so lange mit gefälschten Blöcken zu fluten, bis diese akzeptiert werden. Um das zu vermeiden, gibt es einen ganz trivialen Mechanismus: Das zu lösende Rätsel wird per Protokolldefinition immer schwieriger und die Belohnung pro abgeschlossenen Block immer geringer (bei Bitcoin wird alle 210.000 Blöcke die Belohnung halbiert).
-

 Quelle: Bitkom Research
Quelle: Bitkom Research
Das bedeutet, möchte man einen alten Block manipulieren, müsste man auch alle nachfolgenden Blöcke manipulieren. Dazu müsste man wiederum für den zu fälschenden sowie für sämtliche nachfolgenden Blöcke das kostenintensive Rätsel lösen.
Je älter also ein Block, desto unveränderlicher wird er. Daher ist es auch manchmal so, dass Transaktionen nur dann als unveränderlich beziehungsweise fälschungssicher angesehen werden, wenn diese mindestens drei Blöcke „tief“ sind, das heißt, wenn es mindestens zwei nachfolgende Blöcke gibt, in denen der Hash-Wert durch die Verkettung ebenfalls eingeflossen ist. Vorher werden die Transaktionen in einem Schwebezustand gehalten. Im obigen Beispiel mit dem Kauf von Musik würde man also erst dann Zugriff auf das Musikstück erhalten, wenn die Transaktion mit der Zahlung in einem Block enthalten ist, auf den mindestens zwei weitere gültige Blöcke folgen. Da die Knoten im Blockchain-Netzwerk immer nur die längste Kette gültiger Blöcke (die längste Blockchain) als gültig ansehen, kann man auch nicht einfach eine neue Kette anfangen und im Netzwerk publizieren.
Mit Bitcoin und anderen Krypto-Währungen kann man also weltweit Geld zwischen Wallets übertragen. Im Beispiel mit den Verkehrsbetrieben könnte der eine dem anderen den jeweiligen Anteil an der Monatskarte zukommen lassen. Und beim Kauf von Musik wäre die Zahlungsabwicklung auch geregelt.
Der gesamte Prozess ist sehr stark vereinfacht dargestellt und viele wichtige Aspekte fehlen noch. Wer sich für die Details von Bitcoin interessiert, dem sei das Buch „Mastering Bitcoin“ von Andreas M. Antonopoulos ans Herz gelegt.
Studie
Firmen wissen mit Blockchain nichts anzufangen
Nicht einmal ein Prozent der Unternehmen im DACH-Raum sieht Möglichkeiten zur praktischen Anwendung der Blockchain-Technologie, wie eine Studie zeigt.
>>
Cloud-PBX
Ecotel erweitert cloud.phone-Lösung um MS Teams-Integration
Die Telefonanlage aus der Cloud von Ecotel - ein OEM-Produkt von Communi5 - cloud.phone, ist ab sofort auch mit Microsoft-Teams-Integration verfügbar.
>>
Container
.NET 8 - Container bauen und veröffentlichen ganz einfach
Dockerfiles erfreuen sich großer Beliebtheit. Unter .NET 8 lassen sich Container für Konsolenanwendungen über den Befehl "dotnet publish" erzeugen.
>>
Personalien
Komsa stellt sich im Solution-Segment neu auf
Der Distributor richtet sein UC- und Cloud-Business neu aus und stellt mit Christof Legat einen neuen Vice President UC-Solutions vor, Friedrich Wahnschaffe ist als Vice President für das MS-Cloud-Geschäft von Komsa in Deutschland verantwortlich.
>>