28.02.2019
Größter Datensatz menschlicher Stimmen
Mozilla erweitert Common-Voice-Datenbank
Autor: Stefan Bordel



VectorKnight / Shutterstock.com
Mozilla hat sein Common-Voice-Projekt um zusätzliche Datensätze erweitert. Das aktuelle Release umfasst über 1.300 Stunden aufgezeichneter Sprachdaten von mehr als 42.000 Mitwirkenden.
Seit Juli 2017 sammelt Mozilla Sprach-Samples von freiwilligen Teilnehmern für sein Open-Source-Projekt Common Voice zum Aufbau einer frei verfügbaren Sprachdatenbank. Jetzt haben die Entwickler Common Voice um weitere Datensätze ausgebaut. Damit umfasst das Projekt nunmehr 1.361 Stunden aufgezeichneter Samples aus 18 verschiedenen Sprachen, die von mehr als 42.000 Mitwirkenden beigetragen wurden. Laut eigenen Angaben ist Common Voice damit der größte frei verfügbare Datensatz menschlicher Stimmen.
-
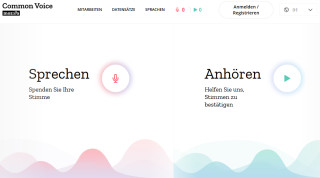
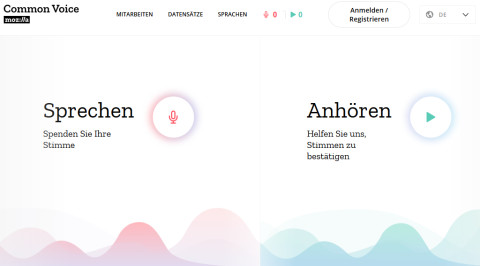
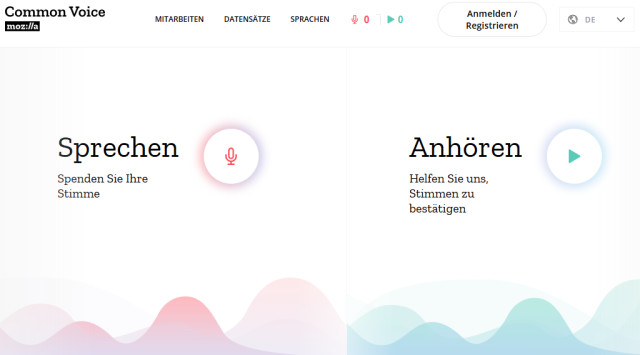 Auf der Common-Voice-Webseite können Freiwillige zum Projekt beitragen.Quelle:Screenshot / com! professional
Auf der Common-Voice-Webseite können Freiwillige zum Projekt beitragen.Quelle:Screenshot / com! professional
Das Ziel von Common Voice liegt bei der Demokratisierung von sprachbasierten Technologien. Bislang wird diese Technik vorrangig von wenigen Tech-Großkonzernen wie Amazon, Apple, Google und Co. genutzt. Das erschwert unabhängigen Entwicklern jedoch das Arbeiten mit der Technologie, da schlichtweg die Datenbasis nicht erreichbar ist. Hier setzt Common Voice an, um innovative Lösungen wie Echtzeit-Übersetzer oder alternative Sprachassistenten fernab der Mainstream-Hersteller zu ermöglichen. Für eine bessere Zugänglichkeit von sprachbasierten Technologien betreibt Mozilla außerdem die freie Spracherkennungs-Engine DeepSpeech.
Bessere Webseite soll mehr Daten generieren
Um neue Freiwillige für eine Beteiligung bei Common Voice zu begeistern, hat Mozilla die Internetseite des Projekts sukzessive weiterentwickelt. Dort stellt der Firefox-Entwickler auch die Tools zur Aufzeichnung der Sprach-Samples bereit. Teilnehmer am Programm können in der aktuellen Version etwa detailliert nachvollziehen, wie sich die Aufnahme und die Validierung jeder einzelnen Sprache entwickeln. Außerdem ist es nun möglich, ein Konto für das Projekt anzulegen, um Fortschritte und Metriken in mehreren Sprachen zu verfolgen. Im Account lassen sich auch demografische Profilinformationen hinterlegen, wodurch der freie Datensatz um wertvolle Metainformationen ergänzt wird.
Trotz der Vielzahl an bereits gewonnenen Daten und Erkenntnisse befinden sich sowohl Common Voice als auch DeepSpeech noch in der Entwicklungsphase. Dennoch geht Mozilla davon aus, dass die Programme bereits in naher Zukunft in konkrete Lösungen einfließen werden. Bereits jetzt wird etwa die DeepSpeech-Engine von den Open-Source-Sprachassistenten Mycroft und Leon genutzt. Zukünftig soll DeepSpeech aber auch in kleineren Geräten wie Smartphones und In-Car-Systemen eingesetzt werden und so Produktinnovationen innerhalb und außerhalb von Mozilla vorantreiben.
Glasfasernetz
GlobalConnect stellt B2C-Geschäft in Deutschland ein
Der Glasfaseranbieter GlobalConnect will sich in Deutschland künftig auf das B2B- und das Carrier-Geschäft konzentrieren und stoppt die Gewinnung von Privatkunden mit Internet- und Telefonanschlüssen.
>>
Untersuchung
Amerikaner sehen KI als Risiko für Wahlen
Die Unterscheidung zwischen echten Infos und KI-Inhalten fällt vielen politisch interessierten US-Amerikanern schwer, wie eine Studie des Polarization Research Lab zeigt.
>>
Studie
KI-gestützte Videosysteme im Handel gefragt
Eine Umfrage bei Unternehmen zeigt, dass vor allem der Handel eine Chance sieht, mit Hilfe KI-gestützter Videosysteme den Umsatz zu steigern.
>>
In-Ear-Kopfhörer
Fairphone bringt nächste Generation der Fairbuds
Die neuen kabellosen In-Ear-Kopfhörer von Fairphone sollen dank austauschbarer Komponenten besonders langlebig sein und Premium-Sound bieten.
>>