19.11.2018
IT-Development und IT-Infrastruktur
1. Teil: „Die IT steckt im permanenten Umbruch“
Die IT steckt im permanenten Umbruch
Autor: Johann Baumeister



LeoWolfert / shutterstock.com
IT-Trends gehen von Microservices bis DevOps, Serverless Computing bis zu Composable Infrastructure. Hierbei ist ein hohes Maß an Dynamik feststellbar.
Der Wechsel in der IT ist beständig. Kaum hat sich eine Technologie etabliert, stehen schon wieder Änderungen ins Haus. Manchmal handelt es sich um gravierende Umwälzungen, oft aber nur um Kleinigkeiten, die durch Marketinggetöse großgemacht werden. Dies gilt auch für viele der derzeit angesagten Innovationen.
Der folgende Beitrag beschränkt sich auf die wichtigsten der aktuellen Entwicklungen: Microservices, DevOps, Serverless Computing, OpenStack, Composable Infrastructure, ferner SoC (System on a Chip) und der Dauerbrenner IoT.
Alle folgen dem seit Jahren ungebrochenen Trend der IT: Die Implementierungen werden immer kleiner und schneller. Dank dieser beständigen Weiterentwicklungen steigen Leistungsfähigkeit und Kapazitäten in allen Bereichen. Die Entwicklung resultiert in schnelleren Netzen, mehr Speicher, mehr Daten, komplexeren Applikationen, größeren Bildschirmen und gänzlich neuen Einsatzgebieten – wie beim Wearable Computing. Um das fortwährende Mehr zu bewältigen, werden die Verarbeitungsmodelle laufend angepasst. Um die aktuellen Innovationen in diesen Kontext einzuordnen, soll zunächst die historische Entwicklung skizziert werden.
Die ersten Rechnersysteme sind zentrale Großrechner. Sie werden vor allem für die Massenverarbeitung von Daten genutzt. Die nachfolgenden Minicomputer erweitern den Einsatzzweck in Richtung Prozessverarbeitung. Ende der 1970er-Jahre baut Intel seine erste CPU und legt den Grundstein für die PCs. Dies führt zum Masseneinsatz der Computertechnik auf jedem Schreibtisch und später auch zu Hause.
Die ersten PCs sind eigenständige Geräte, ohne Netzwerk und zentrale Dienste und haben daher auch nur lokale Anwendungen. In den folgenden Jahren werden die meist separat betriebenen PCs in Netzwerken verbunden und zentrale Server werden etabliert. Diese sind meist aber nur Drehscheiben für Daten oder Programme.
In den Jahren nach 1990 werden die eigenständigen PC-Anwendungen durch Client-Server-Verarbeitung abgelöst. Damit erfolgt eine erste Trennung der Verarbeitungslogik in einen Anteil für den Server und den Client. Um die Jahrtausendwende erscheinen Thin Clients. Sie sind reine Anzeige-Endgeräte für grafische Anwendungen. Die gesamte Rechenleistung läuft auf dem Server-Backend. Thin Clients führen wiederum eine serverbasierte Verarbeitung ein (wie zu Beginn bei den Großrechnern), nun aber grafisch. Geräte werden abermals kleiner und kompakter. Die Notebooks erhalten einen Touchscreen: Tablets sind geboren und eröffnen neue Einsatzfelder. Oft werden sie nur als reine Anzeigegeräte für den Internetzugang genutzt (durch den Browser).
Etwa ab der Jahrtausendwende tritt auch die Virtualisierung ihren Siegeszug an. Sie ermöglicht die parallele Verarbeitung mehrerer Applikationen auf einem System. Man könnte es als Renaissance der Multiuser-Umgebungen betrachten, die Unix bereits seit Urzeiten beherrscht. Virtualisierung geht aber natürlich viel weiter. 2007 erhält mit dem iPhone dann das Telefon einen Grafikbildschirm, Apps bringen viele Anwendungen für Smartphones, wobei die Verarbeitungsmodelle vergleichbar sind mit Client-Server-Anwendungen. Der Client-Anteil läuft als App auf dem Smartphone, der Rest im Web.
Cloud-Computing verlagert dann traditionelle Server-Funktionen ins Netz. Technisch gesehen ist es mit den früheren Servern der 1990er-Jahre vergleichbar. Nur stehen nun die Server nicht mehr im eigenen Rechenzentrum, sondern bei zentralen Cloud-Providern. Geräte werden noch kleiner und schneller: Wearable Computing und IoT bringen Computertechnik auf jedes denkbare Utensil. Edge-Computing bringt Server-Anteile aus dem Web zurück zum Nutzer.
Der kurze Streifzug zeigt eines: Mal ist zentrale Verarbeitung angesagt, dann wieder schwenkt das Pendel zur dezentralen Verarbeitung. Diese Wechsel finden alle unter einer beständigen Weiterentwicklung der Strukturen statt, die im Kern aber geblieben sind. Dies zeigt sich abermals bei den derzeitigen Trends der Computertechnik.
2. Teil: „Microservices“
Microservices
Microservices sind ein Mittel zur Modularisierung von Applikationen. Dabei wird eine Anwendung in mehrere kleinere Einheiten zerlegt. Man spricht auch von Service-Set und meint eine Gruppe zusammengehörender Dienste. Ein Service kann unabhängig entwickelt, getestet und genutzt werden. Ferner müssen die einzelnen Dienste nicht auf der gleichen Technologie und Infrastruktur beruhen. Durch die Zerlegung eines größeren Dienstes in mehrere unabhängige kleinere Module wird die gesamte Anwendung flexibler. Dies steht im Gegensatz zu monolithischen Applikationen, in denen alle Module im selben Kontext und auf derselben Basisinfrastruktur laufen.
Microservices machen Anwendungen zweifelsfrei flexibler. Doch ganz neu ist die Modularisierung von Anwendungen nicht. Im Gegenteil: Der Trend, Anwendungen immer feiner aufzuteilen, ist eigentlich uralt. Waren es bei Mainframe-Applikationen relativ monolithische Anwendungen, so wurden diese bereits in der Client-Server-Welt in einen Server- und einen Client-Anteil zerlegt. Im Anschluss an die Client-Server-Anwendungen etablierten sich in den 90er-Jahren Multi-Tier-Anwendungen. Dabei wurde eine Applikation weiter in mehrere Schichten zerlegt. Dies gilt im Prinzip bis heute, wenngleich der Begriff etwas in den Hintergrund gerückt ist. Aber eine moderne Anwendung, die via Internet zugänglich ist, ist immer eine Multi-Tier-Anwendung. Die Frontends bilden bekanntlich die Smartphone-Apps oder Browser-Anwendungen. Sie laufen meist auf den zugehörigen Endgeräten, dem Smartphone oder Browser. Dahinter befindet sich der Applikationscode, der oftmals bereits mehrere Ebenen umfasst. Und dann ist da noch die Schicht zur Datenbank. Meist wird auch ein Transaktionssystem benötigt.
Auch die Betriebssysteme bestehen seit jeher aus mehreren Schichten. Sie haben einen Kern (Kernel) und eine Reihe umgebender Module wie das Prozess-Handling, ein Benutzerinterface (Shell oder grafisch) oder Ein-/Ausgabesystem, ferner das Dateisystem oder Transaktionssystem. Entwicklungssysteme liefern immer Basisbibliotheken, die wie Microservices grundlegende Dienste offerieren.
Dennoch: Microservices führen diese Aufteilung von Anwendungen in kleinere Einheiten nun konsequent fort. Eines der grundlegenden Prinzipien dabei ist, dass die einzelnen Dienste eben auf unterschiedlichen Umgebungen eingesetzt werden können. Damit wird das gesamte Software-System flexibler. Dies vereinfacht auch die Skalierung eines Dienstes.
Das war etwa bei monolithischen Systemen nicht so einfach. Microservices haben durch ihre feinere Granularität eine Reihe Vorteile gegenüber den umfangreicheren, komplexeren monolithischen Anwendungspaketen. Die einzelnen Module lassen sich nach Bedarf einfacher entwickeln und können auf unterschiedlichen Plattformen zum Einsatz kommen.
Die Migration hin zu Microservices kann schrittweise erfolgen. Wenn etwa ein Dienst bisher durch eine eigene Anwendung im Unternehmen erbracht wurde, lässt sich dieser mit überschaubarem Aufwand zu einem Cloud-Dienst auslagern. Ein Beispiel dafür wäre eine einfache Berechnung. Wird aufgrund einer Gesetzesänderung ein neuer Berechnungslauf notwendig, kann diese Neucodierung ausgelagert werden. Damit müssen natürlich die Verweise auf den neuen Dienst, der nun im Web ist, angepasst werden.
3. Teil: „Serverless Computing“
Serverless Computing
-
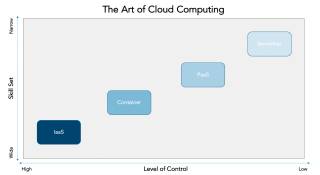
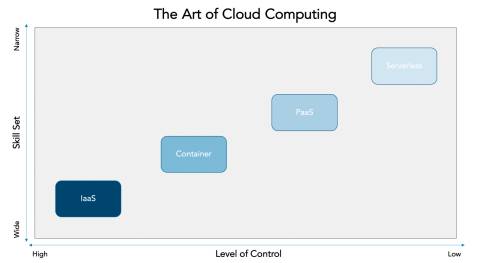
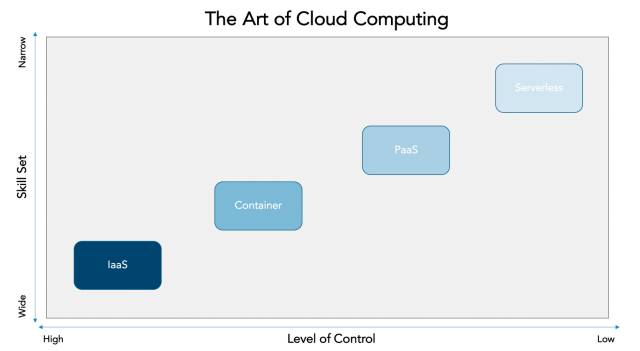
Serverless Computing: Dieses IT-Infrastrukturkonzept ist eine Fortführung von Cloud-Techniken. Quelle:Crisp Resaerch
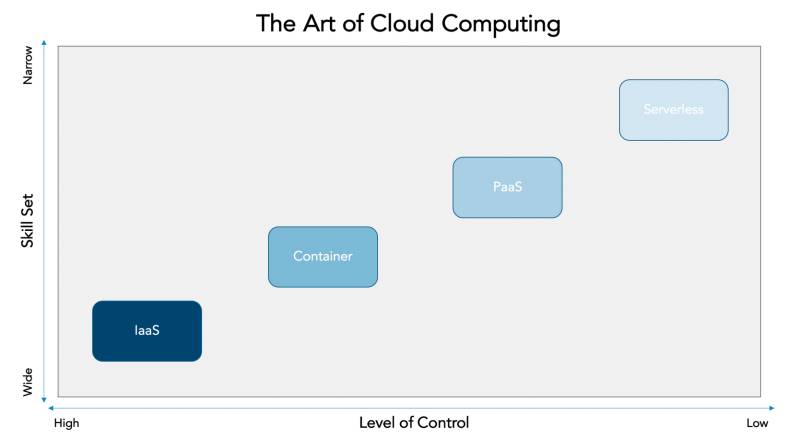
Wenn aber die abgeforderte Leistung plötzlich binnen Minuten extrem ansteigt und dann wieder abfallen kann, so wäre es wenig sinnvoll, permanent Server dafür bereitzustellen (On-Premise). Stattdessen werden die benötigten Dienste kurzerhand meist in Form von virtuellen Umgebungen bereitgestellt. Dafür benötigt man ausgefeilte Deployment-Techniken. Diese sind in der Lage, eine Applikation innerhalb von Minuten in einem abgeschlossenen Bereich, zum Beispiel einem Software-Container, bereitzustellen.
Diese laufen oft auch in der Cloud und werden dann als Platform as a Service (PaaS) bezeichnet. Dabei wird die gesamte Ausführumgebung (die Plattform) vom Service-Provider zur Verfügung gestellt. Mitunter wird auch von Serverless Computing gesprochen. Natürlich braucht man auch dafür Server. Aus der Sicht des Unternehmens, das den Dienst bucht, werden aber eben keine eigenen Server benötigt.
Eine besondere Rolle bei diesen Diensten spielen die Skalierbarkeit und das schnelle Deployment. Letzteres kann wie erwähnt dank der mittlerweile ausgereiften Techniken zur Virtualisierung innerhalb kurzer Zeit erfolgen. Die Skalierbarkeit muss bereits im Design der Applikation berücksichtigt werden und verlangt nicht selten eine Anpassung der Programme an die neuen Anforderungen.
4. Teil: „Composable Infrastructure“
Composable Infrastructure
-
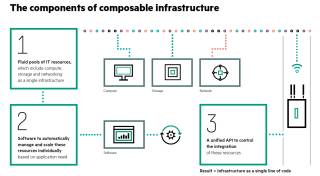
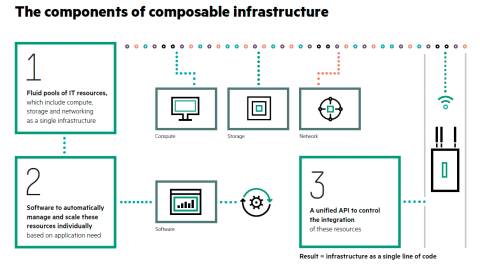
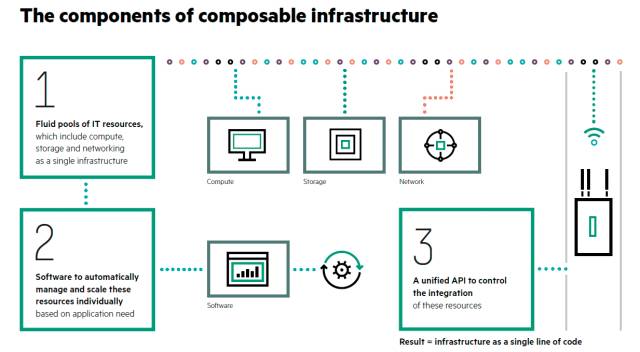 Komponenten: Auf dieser Illustration skizziert HPE seine Vorstellungen von den Bausteinen einer Composable Infrastructure.
Komponenten: Auf dieser Illustration skizziert HPE seine Vorstellungen von den Bausteinen einer Composable Infrastructure.
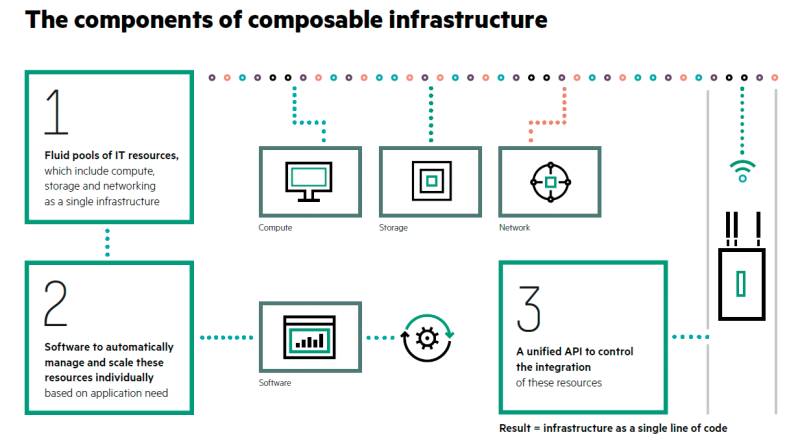
Der gesamte Prozess der Bereitstellung von Infrastruktur gehe dabei über das „einfache Konvergieren oder Hyperkonvergieren von Hardware, Rechenleistung und Speicher zu einer integrierten Gesamteinheit hinaus“. Diese Aussage ist im Kern zwar richtig, aber nicht unbedingt klärend.
Etwas klarer werden die Aussagen, wenn man sie auf die tatsächlichen Aufgaben und die Situation der IT-Verwaltung zurechtrückt. Wie erwähnt werden IT-Dienste heute (und sicher auch in Zukunft) automatisiert bereitgestellt. Ob das nun virtualisiert im eigenen Rechenzentrum, on demand oder wie beim Serverless Computing auf fremder Hardware erfolgt, ist für diese Betrachtung nebensächlich. Das Ziel ist immer eine schnellstmögliche und automatisierte Bereitstellung der Dienste, etwa einer Webseite, die Anfragen annehmen kann, oder eines nachgeschalteten Systems für Bestellungen.
Eine vorbereitete virtuelle Maschine auf eine ebenfalls vorbereitete Hardware zu kopieren und dort zu starten, ist eine Sache von wenigen Minuten. Die Herausforderung liegt in der Konfiguration der virtuellen Maschine beziehungsweise der Hardware. Die neue Instanz des Dienstes muss die Verbindung zum Netzwerk, zum Speicher, der Datenbank und dem Nutzer erhalten. Und dann ist zu klären, wie viel Leistung all diese Subsysteme bekommen sollen. Welchen Durchsatz sollte die Netzanbindung aufweisen? Wie viele Benutzer muss der Webshop betreuen können oder welchen Umfang erhält die virtuelle Maschine in Sachen Arbeitsspeicher?
Es versteht sich von selbst, dass es kaum sinnvoll sein kann, ein automatisiertes Deployment von Anwendungen und Diensten zu verlangen und dann bei Bedarf Speicherbausteine nachzurüsten, oder etwa das Netzwerk zu patchen, damit die passenden Kapazitäten bereitstehen. Dies alles muss durch Konfiguration erfolgen.
In einer Composable Infrastructure muss daher die gesamte IT-Infrastruktur wie die physische Rechenleistung, der Speicher und die Netzwerkanbindung virtualisiert und als Services bereitgestellt werden. Die Konfiguration dieser virtualisierten Hardware muss zentral über ein Verwaltungssystem erfolgen. Dies muss in Echtzeit und weitgehend automatisch passieren, ohne manuelles Zutun eines Administrators. Eine Composable Infrastructure ist demnach eine Infrastruktur, die wahlfrei zusammengesetzt werden kann, wenn sie benötigt wird.
OpenStack
-
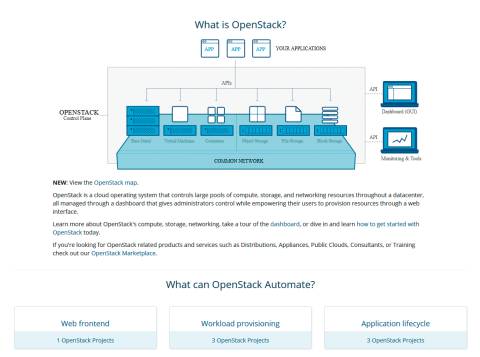
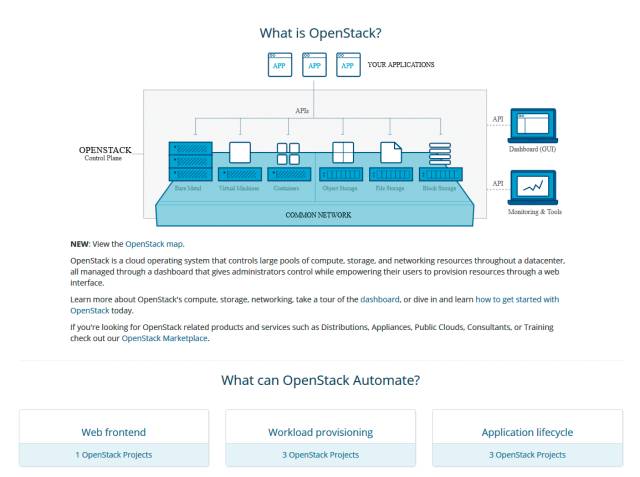 OpenStack: Das Software-Projekt liefert ein weiteres Modul einer vollständig virtualisierten Umgebung.
OpenStack: Das Software-Projekt liefert ein weiteres Modul einer vollständig virtualisierten Umgebung.
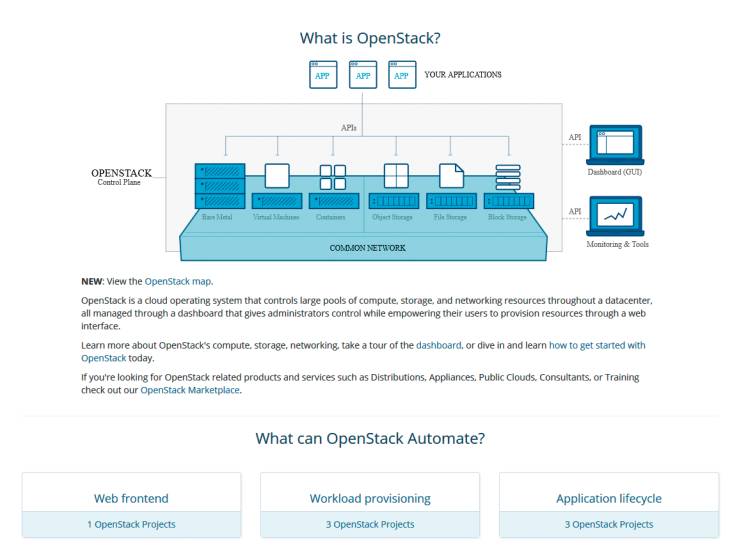
OpenStack basiert aus Standard-Hardware. Deren Orchestrierung sowie die Verwaltung der Hardware und der darauf laufenden virtuellen Maschinen und Container wird durch OpenStack übernommen. Ziel von OpenStack ist eine schnelle Inbetriebnahme von Diensten, die in virtuellen Maschinen laufen. Hierzu liefert OpenStack einen zentralen Dienst, der die Hypervisoren mit den System-Images versorgt. Die werden dann in einer bereitgestellten virtuellen Maschine ausgeführt.
OpenStack umfasst eine Vielzahl an Software-Modulen zur Verwaltung der virtuellen Dienste. Zum Kern gehören drei Software-Segmente zur Verwaltung der Rechner, des Speichers und der Netzwerke. Dies sind auch die drei zentralen Hardware-Blöcke, auf denen jegliche IT-Dienste basieren. Der Rechner oder Server als Compute-Plattform, die Anbindung an den Plattenspeicher für Daten, temporäre Auslagerungen oder allgemeine Speicherplattformen und die Netzwerke als Koppelglied dazwischen.
Cinder ist ein weiteres Modul zur Speicherverwaltung. Dabei handelt es sich um virtualisierte Speichereinheiten, die den virtuellen Maschinen als Blockspeicher zur Verfügung gestellt werden. Die Verwaltung der virtuellen Maschinen erfolgt durch OpenStack Nova. Plattenspeicher für Daten und virtuelle Maschinen wird mittels der OpenStack-Werkzeuge Swift (Object Storage) und Glance (Image Service) verwaltet. Das Modul Neutron schließlich kümmert sich um die Netzwerkanbindung. Zu diesen drei Funktionsblöcken, die die Basis jeglicher virtueller Systeme in einer OpenStack-Cloud mit Swift darstellen, kommen mittlerweile weitere und komfortablere Verwaltungsmodule. Horizon zum Beispiel umfasst ein Verwaltungssystem für die virtuelle Cloud.
OpenStack kann auf eine große Nutzerschar bauen. Die Community umfasst circa 80.000 Nutzer in nahezu 200 Ländern. OpenStack wird von einer Reihe führender Cloud-Anbieter unterstützt wie beispielsweise AT&T, Ericsson, Huawei, IBM, Intel, Rackspace, Red Hat und SUSE.
SoC - System on a Chip
Der Trend zu immer komplexeren Systemen mit mehr Leistung ist ungebrochen. Eine Folge sind SoC-Bausteine. Dabei werden komplette Systeme, die bis dato mehrere Chips umfassten, in einen einzigen Chip gegossen.
Traditionelle Rechnersysteme bestehen aus einer Gruppierung unterschiedlicher Baugruppen. Deren Aufteilung erfolgte meist anhand ihrer Eigenschaften oder Funktionen. Da waren etwa die CPU, der Hauptspeicher, die Ein-/Ausgabebausteine, Interrupt-Controller, Bus-Controller und jede Menge Sensoren und Anzeige-Interfaces. Ein vollständiges System - ob PC, Server oder auch andere computergesteuerte Baugruppen – wurde meist aus diesen Bausteinen zusammengesetzt. Die Verbindung dazwischen erfolgt über die Leiterbahnen der Platinen. Auch wenn diese dank SMD (Surface Mounted Device) über die Jahre immer kleiner wurden, waren es immer noch Millimeter oder gar Zentimeter an Wegen zwischen den Baugruppen, die die Signale zurücklegen mussten. SoC reduziert diese Verbindungen auf Nanometer.
Die Vorteile von SoC sind klar. Die Systeme werden kleiner, kompakter und schneller. Die Nachteile sind fest vergossene Systeme. Eine Änderung oder Erweiterung ist nicht so einfach machbar. Eingesetzt wird die SoC-Technik vor allem dann, wenn es auf Größe, Stromverbrauch und Geschwindigkeit ankommt. Dies gilt meist bei Massenprodukten. Die modernen Smartphones kommen ohne SoC kaum mehr aus. Gleiches gilt für viele der aufkeimenden IoT-Produkte. Es sind Massenartikel, die oft kaum Jahre überdauern. Traditionelle Computersysteme aber werden weiter mit relativ vielen diskreten Bauteilen gefertigt. Ein unschlagbarer Vorteil der traditionellen Fertigung liegt darin, dass sie auf einem nach außen zugänglichen Bus mit Erweiterungs-Slots beruhen. Wenn notwendig, lassen sich leicht andere Baugruppen in das System einbringen. Zwar beruhen SoC-Systeme im Innersten auch immer auf der Grundlage mehrerer Busse, diese sind aber immer in Silizium gegossen und somit von außen nicht zugänglich.
5. Teil: „DevOps“
DevOps
-
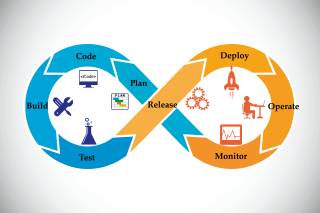
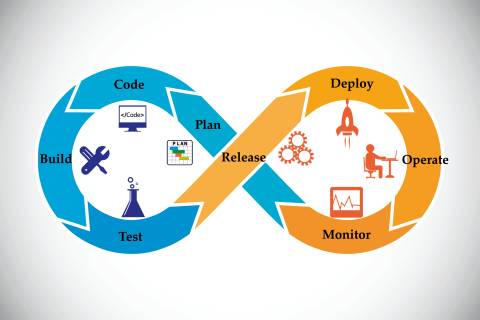
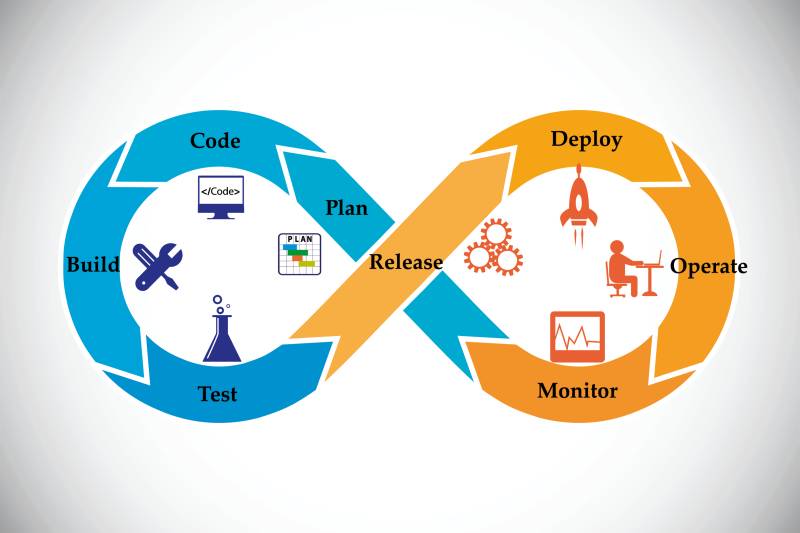
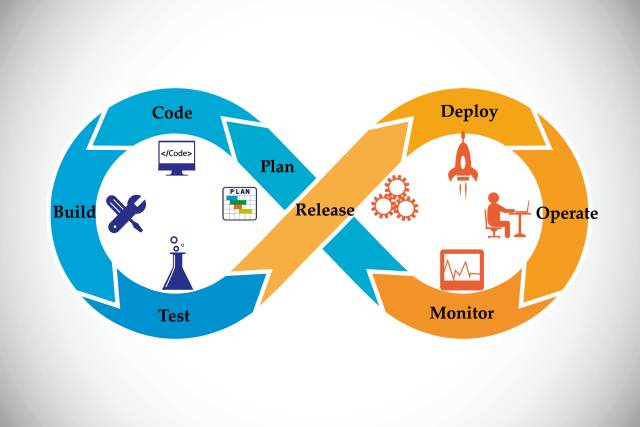 DevOps: Die Integration von Development und Operations steht im Fokus von DevOps.Quelle:Kalakruthi / shutterstock.com
DevOps: Die Integration von Development und Operations steht im Fokus von DevOps.Quelle:Kalakruthi / shutterstock.com
Wie immer man es betrachten mag – zukünftige Software-Systeme erhöhen die Taktrate der Releases erheblich. Wie schnell sich hier das Rad der Entwicklung dreht, zeigt ein kurzer Blick in die Geschichte der Software-Verteilung. Vor weniger als 20 Jahren lieferten die Unternehmen ihre Software überwiegend auf Datenträgern wie CD, DVD oder Diskette aus. Neue Releases gab es etwa im Jahrestakt oder noch seltener. Wenige Jahre später folgten periodische Updates über das Internet. Microsoft etwa begann damit, seine Systeme jeden ersten Dienstag im Monat (Microsoft Tuesday) zu patchen. Die Taktung war also auf einen Monat gesunken. Moderne Apps heute werden oft im Wochentakt erneuert. Der Code der serverseitigen Browser-Seiten kann sich laufend ändern.
Wenn aber neue Releases im Wochenzyklus erstellt werden müssen, so werden dafür agile Methoden benötigt. Während früher die Updates meist in festen Intervallen, den Wartungsfenstern, installiert wurden, ist das nun nicht mehr möglich. Infolgedessen muss das Update im laufenden Betrieb erfolgen. Das verlangt eine enge Abstimmung zwischen der Software-Entwicklung und dem IT-Betrieb.
Erreicht werden soll dies durch DevOps. Entwicklung (Development) und Betrieb (IT-Operations) sollen durch den Einsatz von DevOps schneller neue Releases bereitstellen können. Möglich machen sollen das agile Arbeitsmethoden. Eine häufig genutzte Methode für Entwickler ist Scrum.
Scrum basiert auf wenigen Grundannahmen. Darauf aufsetzend werden Aktivitäten, Artefakte und Rollen beschrieben, die den Kern des Systems ausmachen. Im Scrum-Framework werden die Grundregeln durch Maßgaben für die Umsetzung in konkreten Code beschrieben. Vereinfacht gesagt handelt es sich um eine methodengestützte Anleitung, um Anwendungen nach einem klar definierten Vorgehen zu erzeugen. Durch DevOps sollen diese Techniken in Zukunft für die IT-Operations zur Anwendung kommen. DevOps hilft beim Release-Management, dem Software-Configuration-Management und dem Environment-Management. Künftig soll damit die Übergabe einer Anwendung von der Entwicklung bis in die Produktion vereinfacht werden.
DevOps ist kein Werkzeug, kann aber natürlich durch Werkzeuge unterstützt sein. Die Methode basiert auf fünf Prinzipien: Culture, Automation, Lean, Measurement und Sharing. In Culture wird die Art der Zusammenarbeit bestimmt. Sie sollte auf Vertrauen und permanentem Informationsaustausch zwischen Entwicklung und IT-Operations basieren. In Automation wird festgelegt, dass die Umsetzung durch Automatismen unterstützt sein muss. Diese Anforderung ist eigentlich selbstverständlich, denn die Dynamik moderner Anwendungen in der Cloud kann nicht durch manuelle Administration erfolgen. Dies wäre schlichtweg unmöglich. Automation im Sinne von DevOps schreibt diese daher zwingend vor. Es beginnt bei einfachen Routinearbeiten und endet bei der vollständigen Automatisierung ganzer Umgebungen.
Die Anforderung Lean legt fest, dass die gesamte Umsetzung möglichst einfach und überschaubar sein soll. Zur Sicherung der Qualität muss eine laufende Überwachung (Measurement) erfolgen. Dabei muss man sowohl die laufende Entwicklung wie die nachgeschalteten Prozesse im Auge behalten. Und schließlich müssen die Projektteams ihre Arbeit aufeinander abstimmen. Dazu muss das Wissen geteilt werden und beide Seiten müssen bereit sein, voneinander zu lernen. Die zwei Gruppen müssen ihre Arbeit teilen (Share).
Die letzten beiden Anforderungen sind kaum neu, sie galten schon in früheren Projekten. Allein die Umsetzung gestaltete sich oft problematisch. Entwicklungsteams, die sich wenig um den späteren Einsatz kümmern, oder eine IT-Administration, die bei Problemen im Einsatz den Schwarzen Peter immer der Entwicklung zuschiebt, brachten noch nie Erfolge hervor.
Fazit
Die Anforderungen an Entwicklung und Einsatz von Software ändern sich beständig. Nach wie vor ist eine hohe Dynamik feststellbar. Bei allen derzeit anstehenden Änderungen zeigen sich grundlegende Trends: Software-Systeme werden noch weiter modularisiert. Die Programme der Vergangenheit werden immer weiter aufgebrochen. Ferner müssen diese kleineren Module weitaus dynamischer sein als noch ihre Vorgänger. Für ein Mehr an Dynamik sorgen auch agile Entwicklungstechniken. Software wird on-the-fly erneuert und angepasst. Das Deployment erfolgt nach Bedarf entweder in einer virtuellen Umgebung oder in der Cloud.
Umweltschutz
Netcloud erhält ISO 14001 Zertifizierung für Umweltmanagement
Das Schweizer ICT-Unternehmen Netcloud hat sich erstmalig im Rahmen eines Audits nach ISO 14001 zertifizieren lassen. Die ISO-Zertifizierung erkennt an wenn Unternehmen sich nachhaltigen Geschäftspraktiken verpflichten.
>>
Cyberbedrohungen überall
IT-Sicherheit unter der Lupe
Cybersecurity ist essentiell in der IT-Planung, doch Prioritätenkonflikte und die Vielfalt der Aufgaben limitieren oft die Umsetzung. Das größte Sicherheitsrisiko bleibt der Mensch.
>>
Glasfasernetz
GlobalConnect stellt B2C-Geschäft in Deutschland ein
Der Glasfaseranbieter GlobalConnect will sich in Deutschland künftig auf das B2B- und das Carrier-Geschäft konzentrieren und stoppt die Gewinnung von Privatkunden mit Internet- und Telefonanschlüssen.
>>
Pilot-Features
Google Maps-Funktionen für nachhaltigeres Reisen
Google schafft zusätzliche Möglichkeiten, um umweltfreundlichere Fortbewegungsmittel zu fördern. Künftig werden auf Google Maps verstärkt ÖV- und Fußwege vorgeschlagen, wenn diese zeitlich vergleichbar mit einer Autofahrt sind.
>>