12.02.2019
Unstrukturierte Daten auswerten
1. Teil: „Intelligente Datenanalyse in der Praxis“
Intelligente Datenanalyse in der Praxis
Autor: Andreas Fischer



Itzchaz / Shutterstock.com
Von der Medizin bis zum Finanzamt: Big-Data-Analysen etablieren sich branchenübergreifend und ermöglichen innovative Geschäftsmodelle.
Alle reden über Big Data, aber wie bei jedem Hype darf man sich fragen, wo wirklich Bedarf ist und wer die intelligenten Datenanalysen überhaupt schon benötigt und einsetzt? Genügen vielen Unternehmen nicht immer noch vergleichsweise gewöhnliche Datenbankanfragen per SQL (Structured Query Language) oder gar der ausführliche Blick in Excel-Tabellen?
Nicht mehr in jedem Fall. So ist zum Beispiel nach Ansicht von Alexandra Kautzky-Willer Big Data „unheimlich hilfreich“ für eine personalisierte Medizin. Sie ist Fachärztin für Innere Medizin und Professorin für Gendermedizin an der Medizinischen Universität Wien.
In einem Interview hat sie beschrieben, wie sich mit Big Data auch große Gruppen „detailreich analysieren und interessante Zusammenhänge feststellen lassen“. So habe man mit Hilfe der neuen Technologie die Krankheit Diabetes ausführlicher untersuchen können und dabei herausgefunden, dass es bei ihrer Verbreitung drei Peaks gab, die jeweils mit Hungersnöten zusammenhingen. Eine mangelhafte Ernährung der Mutter habe dann zu einem erhöhten Diabetes-Risiko für ihre Kinder geführt.
Überhaupt werden gerade in der Medizin zunehmend größere Datenmengen erhoben, die auf ihre umfangreiche Auswertung warten. Und viele gesunde Menschen überwachen mit großem Eifer ihre diversen sportlichen Aktivitäten, ihren Puls, ihren Schlaf sowie ihre Essgewohnheiten. Dazu verwenden sie ihre Smartphones und immer häufiger die intelligenteren Smartwatches. Die dabei erfassten Daten werden schon lange nicht mehr nur lokal gespeichert, sondern wandern meist direkt in die Cloud, wo sie – zu adretten Grafiken und Statistiken aufbereitet, weiterverarbeitet und mit den Ergebnissen anderer Teilnehmer verglichen werden können.
Aber auch bei bereits Erkrankten fallen zahlreiche Daten an. Sie gehen zum Arzt, lassen sich untersuchen, es wird Blut abgenommen und in Labors geschickt, wo es analysiert wird. Die Ärzte stellen Rezepte aus und schreiben Krankmeldungen.
-
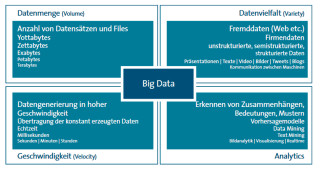
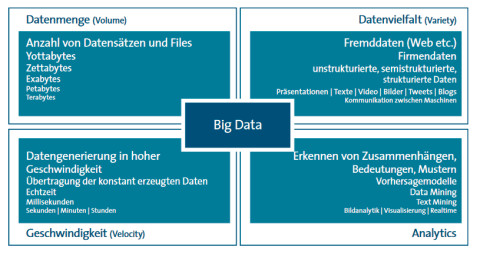
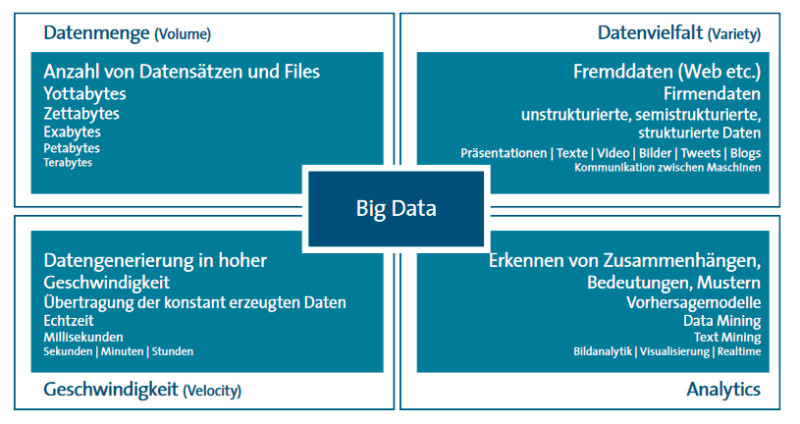
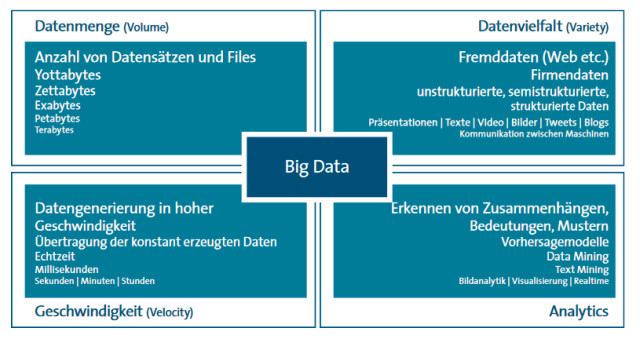 Merkmale: Big Data in der Praxis wird durch die zu verarbeitenden Datenmengen, die Vielfalt der Daten, die Geschwindigkeit der Verarbeitung und das Erkennen von Zusammenhängen bestimmt.Quelle:Bitkom
Merkmale: Big Data in der Praxis wird durch die zu verarbeitenden Datenmengen, die Vielfalt der Daten, die Geschwindigkeit der Verarbeitung und das Erkennen von Zusammenhängen bestimmt.Quelle:Bitkom
Auch Tweets beim Blogging-Dienst Twitter lassen sich analysieren: Wenn dort bestimmte Worte wie „Husten“ häufiger auftauchen, dann können auch entsprechende Krankheitswellen prognostiziert werden.
„Wir ordnen Patienten in Kategorien ein, statt sie individuell zu betrachten“, sagte Marc Dewey laut dem Magazin „Wired“. Er ist Professor für Radiologie an der Berliner Universitätsklinik Charité. Die Medizin klammere sich noch immer an jahrzehntealte, pauschalisierte Verfahren, um Menschen zu untersuchen. Stattdessen sollte sie ihren Blick auf jeden Einzelnen richten. Dewey will mit einer neuen App zur Analyse von Herzerkrankungen für schnellere und vor allem bessere Diagnosen sorgen. Die App stellte er auf einem
„Accelerator Day“ des Berliner Instituts für Gesundheitsforschung vor. Die Basis für diese App sollen die Daten von mehreren Tausend anderen Patienten sein, die Ärzten dabei helfen, „Schritt für Schritt zur wahrscheinlichsten Erklärung für die Beschwerden“ zu kommen.
„Accelerator Day“ des Berliner Instituts für Gesundheitsforschung vor. Die Basis für diese App sollen die Daten von mehreren Tausend anderen Patienten sein, die Ärzten dabei helfen, „Schritt für Schritt zur wahrscheinlichsten Erklärung für die Beschwerden“ zu kommen.
2. Teil: „Abrüsten beim Datenschutz“
Abrüsten beim Datenschutz
Die umfassende Digitalisierung der Wirtschaft und des Alltags vieler Menschen hat dafür gesorgt, dass eine Flut von medizinischen Daten entstanden ist, die nach Ansicht von Dorothee Bär mit traditionellen Methoden nicht mehr kontrolliert werden kann beziehungsweise auch nicht mehr sollte. Dorothee Bär ist Staatsministerin im Bundeskanzleramt und Beauftragte der Bundesregierung für Digitalisierung.
In einem Interview mit der „Bild“-Zeitung und der „Welt am Sonntag“ verlangte Bär eine „smarte Datenkultur“. In Deutschland existiert ihrer Ansicht nach noch ein „Datenschutz wie im 18. Jahrhundert“. Bär: „Das blockiert viele Entwicklungen im Gesundheitswesen, deshalb müssen wir da auch an der einen oder anderen Stelle abrüsten, einige Regeln streichen und andere lockern.“
Aussagen wie diese stoßen allerdings nicht immer auf Begeisterung. „Die Menschen müssen sicher sein, dass Informationen über ihre Krankheit und Therapie nicht ungeschützt für jedermann zugänglich sind“, zitierte die Deutsche Presse Agentur den Vorstand der Deutschen Stiftung für Patientenschutz, Eugen Brysch.
Das Thema Big Data stellt die Informationssicherheit und den Datenschutz auch nach Ansicht des Digitalverbands Bitkom vor ganz neue Herausforderungen. In seinem Leitfaden „Big Data im Praxiseinsatz – Szenarien, Beispiele, Effekte“ schreibt der Branchenverband, dass zu den ersten Maßnahmen vor der Umsetzung von Big Data der Aufbau einer Data Governance gehöre, die sämtliche Prozesse und Verantwortlichkeiten festlege und die Compliance-Richtlinien definiere.
Was ist eigentlich Big Data?
Big Data ist auf jeden Fall mehr als nur die Ansammlung gigantischer Datenmengen. Schließlich ist ihre Verarbeitung kein neues Phänomen. Bei Big Data geht es immer auch um die Analyse und die Nutzung dieser Daten. Dabei handelt es sich um eine Weiterentwicklung konventioneller Verfahren aus dem Bereich Business Intelligence (BI). Mit Hilfe von Algorithmen werden die anfallenden Datenberge nach Mustern und Zusammenhängen durchforstet. Anders als früher wird dabei nicht mehr die einzelne Nadel im Heuhaufen gesucht, sondern dessen bislang verborgene Struktur. Manche sprechen deswegen statt von Big Data mittlerweile bereits von Smart Data.
Ursachen auf den Grund gehen
Um beim Beispiel der Medizin zu bleiben, geht es hier also darum, zu verstehen, warum eine Erkrankung überhaupt entsteht. Welche Zusammenhänge wurden bisher übersehen? Warum reagieren verschiedene Menschen unterschiedlich auf bestimmte Krankheiten?
-
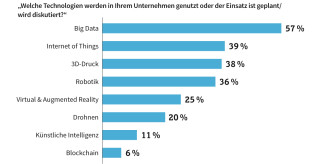
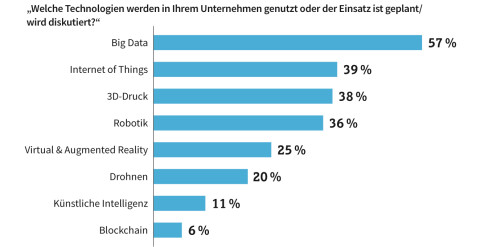
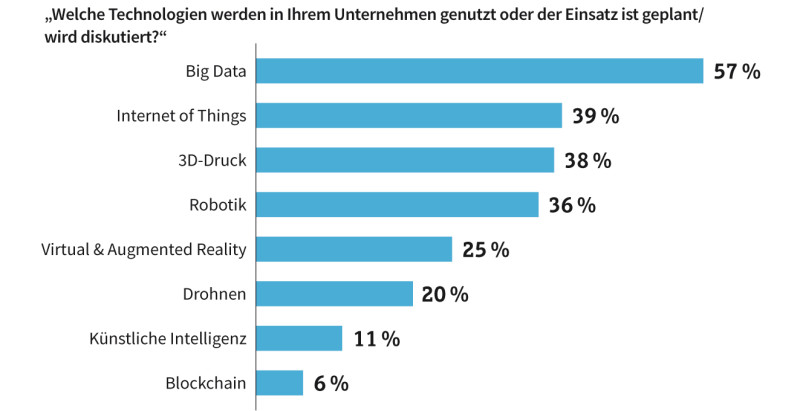
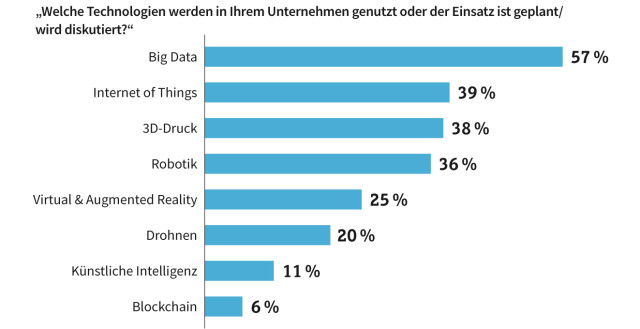 Big Data an erster Stelle: Bei sechs von zehn deutschen Unternehmen stand 2018 Big Data weit oben.Quelle:com! professional
Big Data an erster Stelle: Bei sechs von zehn deutschen Unternehmen stand 2018 Big Data weit oben.Quelle:com! professional
3. Teil: „Sensible Daten“
Sensible Daten
Gleichzeitig rückt allerdings auch der Schutz sensibler Patientendaten wieder stärker in den Vordergrund – nicht nur seit die Datenschutz-Grundverordnung (DSGVO) der Europäischen Union seit Mai vergangenen Jahres von allen Unternehmen umzusetzen ist, die personenbezogene Daten von EU-Bürgern speichern oder verarbeiten. Beispielsweise dürfen bestimmte Diagnosen nicht in die Hände Dritter fallen, etwa in die neugieriger Arbeitgeber oder Versicherungsanbieter.
Das Berliner Start-up Statice hat deswegen ein System entwickelt, mit dem sich „synthetische Daten“ erstellen lassen, die keine Rückschlüsse auf einzelne Patienten mehr erlauben sollen. Nach Aussage von Statice-Mitgründer und CEO Sebastian Weyer ist es damit möglich, vollständig anonymisierte Daten DSGVO-konform zu generieren und zu verbreiten. Aus ihnen sollen sich dann keine Bezüge zu Einzelpersonen mehr herstellen lassen.
Recommendation Engines
Aber das ist noch nicht alles. Big Data ist in immer mehr konkreten Nutzungsfällen anzutreffen. So wird die Technologie zum Beispiel im E-Commerce zunehmend genutzt, um den Kunden in einem Online-Shop immer neue Kaufimpulse zu vermitteln. Big-Data-Systeme und Empfehlungs-Analysen sollen den Händlern dabei helfen, den Besuchern ihrer Webseiten ein personalisiertes Einkaufserlebnis zu bieten.
Im Fachjargon werden diese Techniken Recommendation Engines genannt. Sie stecken beispielsweise hinter den Buchempfehlungen bei Amazon, den Filmvorschlägen auf Netflix und den Kontaktvorschlägen bei LinkedIn.
Diese „Empfehlungsmaschinen“ nutzen dazu etwa Daten aus vergangenen Einkäufen, um Vorhersagen über künftige Interessen treffen zu können. Aber auch andere Informationen wie Kaufinteressen, mobile Daten und das Klickverhalten werden für die Einschätzungen miteinbezogen.
Dabei kommt es zu einer Win-win-Situation: Der Kunde profitiert von persönlichen Empfehlungen, die sein Einkaufserlebnis individueller machen. Der Händler kann zugleich mit einer Empfehlungsanalyse seine Raten im Up- und Cross-Selling steigern sowie die Kundenloyalität verbessern.
Nach Erkenntnissen der Berater von McKinsey stammen bereits heute 35 Prozent dessen, was Kunden beim Online-Riesen Amazon kaufen, und 75 Prozent dessen, was Videofans beim Streaming-Dienst Netflix anschauen, von diesen Recommendation Engines.
4. Teil: „Schutz von Kindern“
Schutz von Kindern
In einem ganz anderen Umfeld setzen die Analytics- und Software-Spezialisten SAS und Mindshare Technology auf Big Data, um Kinder besser vor Misshandlungen und Verwahrlosung zu schützen. Die von beiden Unternehmen gemeinsam entwickelte Technologie soll Sozialarbeiter dabei unterstützen, „nahezu in Echtzeit zu erkennen, wie hoch das Risiko beziehungsweise die aktuelle Gefährdung für Minderjährige ist“.
Die Lösung soll die Streetworker automatisch auf drohende Gefahren für Kinder hinweisen, sodass sie – in dringenden Fällen – deutlich schneller aktiv werden können. Dazu werte man unter anderem Polizeiberichte beziehungsweise Datenbanken des Gesundheitswesens aus.
Häufige Indikatoren für gravierende Probleme in einer Familie seien zum Beispiel abgesetzte Notrufe, Hinweise über die Verhaftung von Angehörigen, neue Bewohner im Haushalt, häufige Abwesenheiten in der Schule sowie strafrechtliche Ermittlungen.
Man wolle den zuständigen Stellen dabei helfen, „Daten zu durchforsten, Risikomuster in Minutenschnelle neu einzuschätzen und gefährliches Verhalten zu erkennen“, erklärt Greg Povolny, Gründer und CEO von Mindshare Technology. Das Verbindungsnetz zwischen Kindern und Erwachsenen sei oft entscheidend, wenn es um das Identifizieren von Hochrisikokindern gehe.
Man unterstütze die Sozialarbeiter mit einem eigenen Dashboard, das ihnen permanent die neuesten Informationen zu jedem ihrer Fälle anzeigt und sie sofort alarmiert, wenn das Risiko für das Wohlbefinden eines „ihrer“ Kinder sprunghaft steigt.
Schutz vor Versicherungsbetrug
Darüber hinaus eignet sich Big Data auch, um etwa Versicherungsbetrug zu erkennen. Nach Angaben von Search & Content Analytics (SCA), einer auf Enterprise-Suchen spezialisierten Tochtergesellschaft von Accenture, entsteht durch Betrug bei Entschädigungen für Arbeitnehmer jedes Jahr ein Schaden in Höhe von rund fünf Milliarden Dollar.
Auf Basis der Tools Cloudera Hadoop und Cloudera Search sowie der Suchtechnologie Query Processing Language (QPL) hat das Unternehmen im Auftrag eines nicht genannten Anbieters von Versicherungen deswegen einen „Werkzeugkasten“ für die Betrugsermittler entwickelt. Mit diesem Tool-Set sollen sich Ansprüche sowie Rechnungen analysieren und verdächtige Schlüsselmerkmale für Betrugsfälle schnell und einfach erkennen lassen. Früher habe man zu diesem Zweck lediglich statistische Stichproben verwenden können.
5. Teil: „Individuelle Kfz-Versicherungen“
Individuelle Kfz-Versicherungen
Kfz-Versicherer zeigen ebenfalls großes Interesse an den Möglichkeiten der Big-Data-Technologie. Damit wollen sie potenzielle Risiken besser erkennen und irgendwann individuelle Policen anbieten, die auf dem tatsächlichen Fahrverhalten und etwa nicht mehr nur auf einem bestimmten Fahrzeugtyp basieren.
-


 Kfz-Versicherer können mittels Big Data neue Geschäftsmodelle entwickeln.Quelle:Rawpixel.com / Shutterstock.com
Kfz-Versicherer können mittels Big Data neue Geschäftsmodelle entwickeln.Quelle:Rawpixel.com / Shutterstock.com

Tarife für Fahranfänger
Die Württembergische Versicherung nutzt eine ähnliche App seit Mitte 2017 mit Vodafone als Technologie-Partner, um Fahranfängern unter 30 Jahren einen günstigeren Tarif für ihr Fahrzeug anzubieten.
Die App der Württembergischen Versicherung ermittelt aus den Beschleunigungs- und Bremswerten sowie aus dem Kurvenverhalten einen „persönlichen Fahr-Score“ des Fahrers. Außerdem erkennt die App, ob der Fahrer sein Smartphone während der Fahrt nutzt.
Wenn der Fahr-Score einen bestimmten zuvor festgelegten Wert übersteigt, dann wird der Fahrer entsprechend neu eingestuft. Dadurch soll nicht nur das Unfallrisiko reduziert werden, der Versicherungskunde kann so auch seinen persönlichen Fahrstil beobachten und entsprechend anpassen – und bares Geld sparen.
Die Daten der einzelnen Fahrten sammelt im Beispiel der Württembergischen Versicherung das Mobilfunkunternehmen Vodafone. Das Versicherungsunternehmen erhält nach eigenen Angaben „lediglich aggregierte Informationen wie den Gesamt-Score, nicht jedoch Detailinformationen über einzelne Fahrten“.
Nach Aussage von Franz Bergmüller, Vorstandsmitglied bei der Württembergischen Versicherung, will man in Zukunft noch tiefer in diese Thematik einsteigen und das Angebot ausbauen: „Das Internet der Dinge wird großen Einfluss auf die Produktgestaltung und -bepreisung haben.“
6. Teil: „Big Data auf dem Amt“
Big Data auf dem Amt
Nicht nur die Privatwirtschaft setzt zunehmend auf Big Data, auch staatliche Behörden wie das Finanzamt sitzen auf gewaltigen Datenbergen, die sie für ihre Zwecke einsetzen können.
Seit 2005 werden die Datenquellen, aus denen die Steuerbehörde schöpfen kann, kontinuierlich ausgebaut. Die Arbeitgeber liefern Informationen über Lohnzahlungen, bereits gezahlte Steuern und Sozialabgaben sowie über steuerfreie Leistungen. Krankenversicherungen berichten über Beiträge und ausgezahlte Prämien, über Kranken- sowie Mutterschaftsgeld. Rentenversicherer geben Daten über gesetzliche und private Renten weiter, Finanzinstitute melden steuerfreie Kapitalerträge sowie Erbschaften und Notare etwa Immobilienkäufe. Dazu kommt seit 2017 ein automatischer Informationsaustausch mit ausländischen Behörden, sodass auch Einkünfte aus anderen Ländern nicht mehr verborgen bleiben.
Was genau das Finanzamt mit diesen Daten macht und welche Algorithmen es verwendet, um sie zu analysieren, ist allerdings nicht bekannt. Es verfügt aber bereits über Software, die die Steuererklärungen automatisch prüft und bearbeitet. Nur wenn die gemachten Angaben nicht plausibel sind und größere Abweichungen zu den Vorjahren herrschen, erfolgt noch eine Überprüfung durch einen Mitarbeiter.
Im Ergebnis wird das Schummeln bei der Steuererklärung so immer schwieriger. Schon jetzt ist bekannt, dass das Finanzamt zum Beispiel gezielt nach professionellen Händlern bei Ebay fahndet, die ihre Umsätze zum Teil oder komplett verschweigen.
Fazit
Nach Schätzungen des Marktforschungsunternehmens IDC im Auftrag des Digitalverbands Bitkom wurden im vergangenen Jahr allein in Deutschland mit Hardware, Software und Services für Big-Data-Anwendungen etwa 6,4 Milliarden Euro umgesetzt. Das ist eine Steigerung um 10 Prozent im Vergleich zum Vorjahr. Bitkom-Präsident Achim Berg zeigt sich deswegen überzeugt, dass „bei immer mehr Unternehmen intelligente Datenanalysen die Grundlage für den Geschäftserfolg schaffen“. Auch in Zukunft wird sich daran vermutlich nicht viel ändern. Eher dürfte der Zug der intelligenten Speicherung und Verarbeitung von Daten weiter an Fahrt aufnehmen.
Forschung
KI macht Gebärdensprache zugänglicher
Ein KI-Tool der Universität Leiden für "Wörterbücher" erkennt Positionen und Bewegungen der Hände bei der Darstellung unterschiedlicher Gebärdensprachen.
>>
Umweltschutz
Netcloud erhält ISO 14001 Zertifizierung für Umweltmanagement
Das Schweizer ICT-Unternehmen Netcloud hat sich erstmalig im Rahmen eines Audits nach ISO 14001 zertifizieren lassen. Die ISO-Zertifizierung erkennt an wenn Unternehmen sich nachhaltigen Geschäftspraktiken verpflichten.
>>
Cyberbedrohungen überall
IT-Sicherheit unter der Lupe
Cybersecurity ist essentiell in der IT-Planung, doch Prioritätenkonflikte und die Vielfalt der Aufgaben limitieren oft die Umsetzung. Das größte Sicherheitsrisiko bleibt der Mensch.
>>
Galaxy AI
Samsung bringt KI auf weitere Smartphones und Tablets
Einige weitere, ältere Smartphone- und Tablet-Modelle von Samsung können mit einem Systemupdate jetzt die KI-Funktionen von Galaxy AI nutzen.
>>