11.01.2019
Schneller reagieren
1. Teil: „Echtzeit-Analyse dank Data Stream Processing“
Echtzeit-Analyse dank Data Stream Processing
Autor: Konstantin Pfliegl



Kapralcev / shutterstock.com
Das unmittelbare Auswerten von Daten wird für den Unternehmenserfolg immer wichtiger. Entscheidungen können damit lokal und schnellstmöglich getroffen werden.
-


 Quelle: Seagate / IDC
Quelle: Seagate / IDC

Vor allem die Unternehmen selbst sorgen für diese Explosion: Während 2015 noch rund 30 Prozent der weltweiten Datenmenge von Unternehmen generiert wurden, sollen es 2025 bereits 60 Prozent sein. Die Unternehmen sehen sich mit einer immer größeren Datenmenge konfrontiert, die es auszuwerten gilt und worauf zu reagieren ist. Und allein schon wegen der schieren Menge wird es in den kommenden Jahren immer schwieriger, sämtliche anfallenden Daten zu speichern und zu bearbeiten.
Datenverarbeitung in Echtzeit
Auf die Unternehmen kommen also in Sachen Datenanalyse ganz neue Aufgaben zu. „Die primäre Herausforderung ist, festzulegen, welche Datenströme überhaupt verarbeitet werden“, so die Erfahrung von Björn Bartheidel, Director IoT & Manufacturing beim IT-Dienstleister Freudenberg IT. Die diesbezüglichen Schwierigkeiten bestätigt auch Shawn Rogers, Senior Director of Analytic Strategy bei Tibco, einem Anbieter von Analyse-Software. Es werde für alle Unternehmen wichtig, zu entscheiden, an welcher Stelle Daten analysiert werden sollen – „sie benötigen die Flexibilität, Analysen an der Datenquelle durchführen und die Daten mit anderen Quellen kombinieren zu können, um den Mehrwert der Erkenntnisse zu steigern.“
Das sogenannte Data Stream Processing oder Data Streaming gewinnt daher in der Big-Data-Welt stark an Bedeutung. Anstatt wie beim herkömmlichen Vorgehen die Daten in einer Datenbank abzulegen und erst bei Bedarf abzufragen und zu analysieren, werden beim Data Stream Processing die Daten bereits dann in Echtzeit verarbeitet und analysiert, wenn sie anfallen.
Ein prominentes Beispiel ist die chinesische E-Commerce-Plattform Alibaba. Sie erzielte am letzten Singles’ Day binnen 24 Stunden einen Umsatz in Höhe von 30,8 Milliarden Dollar. Der Singles’ Day ist ein jährliches Event im November und zugleich der umsatzstärkste Online-Shopping-Tag des Jahres. Damit eine IT-Infrastruktur einen solchen Shopping-Ansturm bewältigen kann, ist die unmittelbare Verarbeitung und Analyse großer Datenmengen unabdingbar. So wurden zum Beispiel die Such- und Produktempfehlungen auf den Shop-Seiten den Aktivitäten der Käufer entsprechend in Echtzeit angepasst. Mit einer Stream-Processing-Plattform konnte Alibaba alle Daten innerhalb von Millisekunden nach der Generierung berechnen.
Den Trend zur Echtzeitverarbeitung bestätigen die Wachstumsraten: Dem Marktforschungsunternehmen Markets and Markets zufolge soll der weltweite Markt für Streaming-Analytik von rund 3,1 Milliarden Dollar 2016 auf satte 13,7 Milliarden Dollar im Jahr 2021 wachsen.
Björn Bartheidel von Freudenberg IT kennt aus seiner täglichen Praxis den Druck der Unternehmen, Daten möglichst zeitnah zu verarbeiten: „Speed is Key“, so Bartheidel. Analysen müssten im Grunde direkt verfügbar sein – zeitlicher Verzug könne in diesem Bereich schnell zu einem echten Problem werden. „Heutzutage geht es längst nicht mehr um Tage oder Stunden, sondern um wesentlich kleinere Zeitfenster. Hier hilft das Stream Processing, denn Daten werden damit unmittelbar – im System – verarbeitet.“
Die Echtzeitdatenverarbeitung beim Data Streaming bedeutet aber nicht, dass immer alle Daten sofort und ohne Verzug verarbeitet werden müssen. Während zum Beispiel bei einem selbstfahrenden Auto nur Reaktionszeiten von wenigen Millisekunden tolerierbar sind, dürfen bei der Auswertung eines Sensors, der etwa den Ölstand einer Maschine misst, durchaus einige Sekunden vergehen. Die Verarbeitung der Datenströme muss also je nach Einsatzzweck nicht wirklich in Echtzeit, sondern in der jeweils ausreichenden Schnelligkeit erfolgen.
2. Teil: „So funktioniert’s“
So funktioniert’s
Herkömmliche Datenanalysen setzen auf eine Batch-orientierte Dateninfrastruktur, eine Stapelverarbeitung. Sie arbeiten nach der Regel „Data at rest“ - die Daten werden zunächst meist in einem Data Warehouse abgelegt und zu einem späteren Zeitpunkt verarbeitet. „Bei klassischen Reporting-Anwendungen vergehen oft Tage oder Wochen, bis die Ergebnisse von Analysen in Handlungen resultieren“, so Frank Waldenburger, Director Sales Consulting Central Europe bei Informatica, einem Unternehmen, das Datenintegrations-Software anbietet. Beim Data Stream Processing wird hingegen alles gleich analysiert und nur die Daten, die für spätere Analysen wertvoll sein könnten, gelangen ins Data Warehouse.
Das Prinzip des Data Streamings ist dabei eigentlich recht einfach: Ein Sender, etwa ein Sensor, erzeugt einen permanenten Datenstrom in einem wiederkehrenden Format, ein Empfänger, etwa ein Cloud-Server, verarbeitet diese Daten und stellt sie zum Beispiel grafisch dar oder führt je nach Datenlage eine bestimmte Aktion aus.
Beim Data Stream Processing kommen Technologien zum Einsatz, um Daten „in Bewegung“ zu analysieren, also noch während des Transports. Ziel dabei ist es, Modelle anzuwenden und/oder Muster oder sonstige Auffälligkeiten zu finden, um in Echtzeit festzustellen, ob eine Handlung oder Intervention nötig ist, und diese gegebenenfalls zeitnah auszulösen. „Dabei werden Live-Daten beispielsweise unter Anwendung von Machine Learning oder anderen Techniken gegen Ergebnisse und Modelle gespiegelt, die häufig aus Batch-Verarbeitungen stammen“, wie Frank Waldenburger von Informatica das Data Stream Processing erläutert. „Die Stream-Verarbeitung analysiert die Daten, während sie das System durchlaufen, wobei die betroffenen Datenmengen und die Anforderungen an die Verarbeitungszeit es nicht zulassen, dass die Daten zuerst in einen Data Store oder eine Datenbank geschrieben werden“, ergänzt Rob Jones, Product Manager Apama bei der Software AG.
Beim Data Streaming ist zudem entscheidend, dass möglichst viele Daten dort analysiert werden, wo sie entstehen: in der Edge. „So kann das Grundrauschen gleich zu Anfang der Datenverarbeitungsstrecke von den wirklich relevanten Daten unterschieden werden - also von denen, die potenziell auf eine Störung oder eine Anomalie hinweisen“, betont Cornelius Kimmer, Senior Solution Architect DACH beim Business-Intelligence-Anbieter SAS.
Die Daten in den Datenströmen haben eine zeitliche Reihenfolge und es gibt praktisch keine Volumengrenze. Es ist aber nur ein fortlaufender Zugriff auf den Datenstrom möglich – im Gegensatz zur herkömmlichen Analyse von Daten etwa in einem Data Warehouse, bei der ein sogenannter wahlfreier Zugriff auf alle Daten möglich ist. Mittels spezieller Algorithmen lassen sich jedoch beim Data Streaming einzelne Datensätze aufgrund ihres Inhalts auswählen und etwa zu einem neuen Datenstrom zusammenfassen, der dann für weitere Analysen zur Verfügung steht.
Dennoch lässt sich nur beschränkt in die Vergangenheit analysieren: „Während Analysen traditionell auf langen historischen Zeitreihen beruhten, um daraus Trends oder Muster abzuleiten, ist das Stream Processing Event-basiert“, wie Stephan Reimann zusammenfasst. Reimann ist Senior IT Specialist Big Data und Analytics bei IBM. Es werden also hauptsächlich aktuelle Meldungen ausgewertet.
3. Teil: „Anwendungsgebiete“
Anwendungsgebiete
-
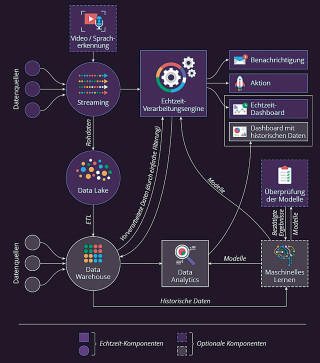
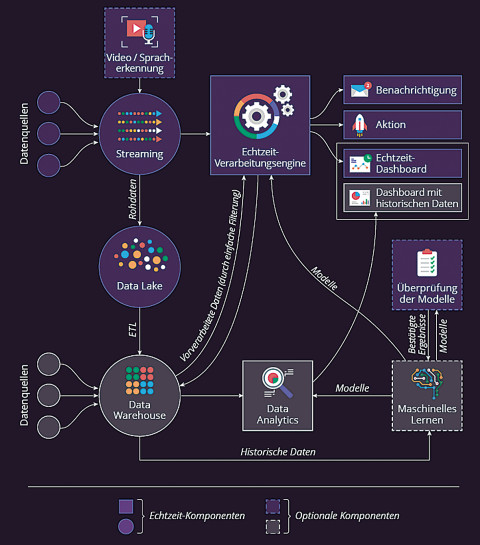
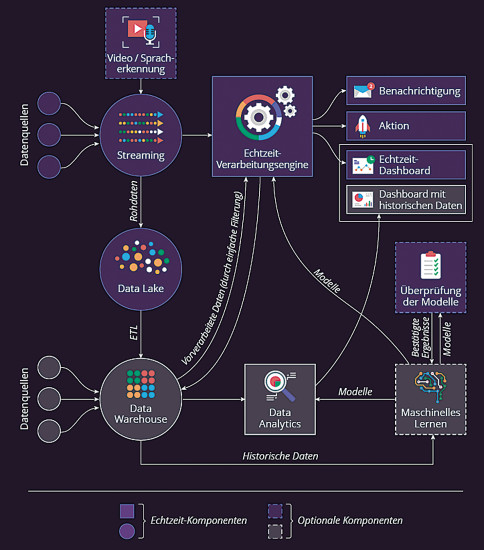
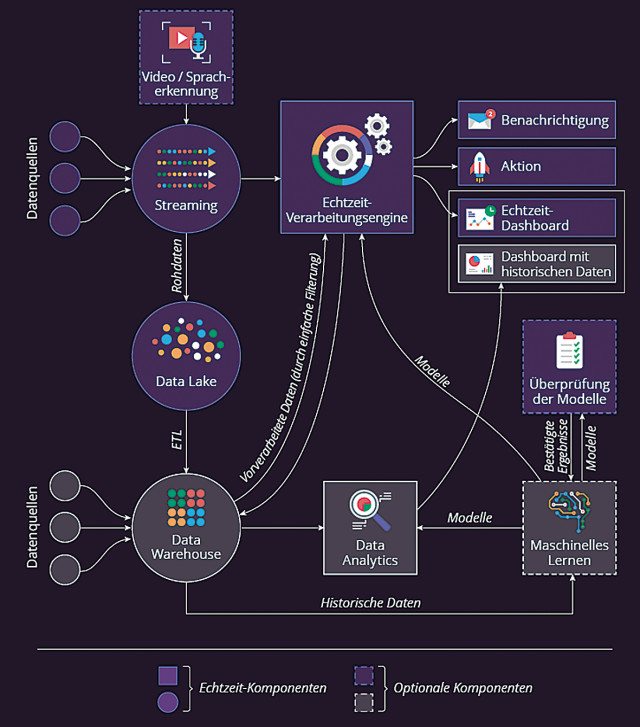 Beispiel-Architektur für das Data Stream Processing: So sieht eine typische Architektur für Big-Data-Analytics in Echtzeit aus.Quelle:ScienceSoft
Beispiel-Architektur für das Data Stream Processing: So sieht eine typische Architektur für Big-Data-Analytics in Echtzeit aus.Quelle:ScienceSoft
Frank Waldenburger von Informatica nennt als weitere Beispiele unter anderem den Telekommunikationsbereich, wo heute schon versucht werde, die Abwanderung von Kunden durch Echtzeitangebote zu verringern. Kundenzentriert arbeitet laut Waldenburger auch der Einzelhandel, indem Unternehmen vernetzte Geschäfte aufbauen, um Kunden besser zu betreuen und zeitnahe und relevante Angebote zu liefern, während sie sich durch den Laden bewegen.
Stephan Reimann von IBM weist noch auf einen Sonderfall hin, der sich ebenfalls für den Einsatz von Stream Processing eignet: In Unternehmen fielen viele Streaming-Daten an, die keine direkte Aktion erforderten, deren Speicherung und spätere Verarbeitung aber entweder technisch oder wirtschaftlich nicht möglich oder sinnvoll sei. Hier sei es angebracht, die Daten sofort zu analysieren und lediglich die Analyseergebnisse zu speichern.
Prinzipiell ist Stream Processing also immer dort interessant, wo beispielsweise Sensordaten im Spiel sind und eine schnelle Reaktion gefragt ist. „Stream Processing ermöglicht dem analytischen System, potenzielle Probleme schon im Vorfeld zu erkennen und abzuwenden, indem eine Maschine heruntergefahren, ein Alert ausgegeben oder eine andere Maßnahme in die Wege geleitet wird“, wie Cornelius Kimmer von SAS berichtet. Eine solche unmittelbare, automatisierte Reaktion sei nicht möglich, wenn Daten erst im Backend abgespeichert werden müssen, bevor sie ausgewertet werden.
4. Teil: „Veränderungen in der IT“
Veränderungen in der IT
-
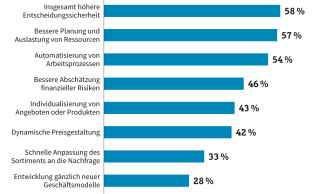
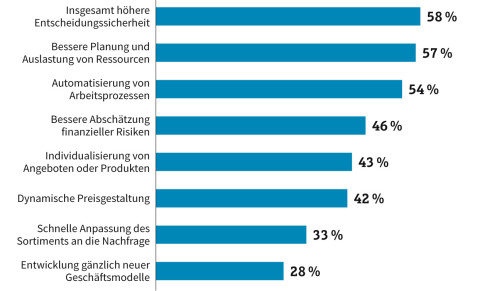
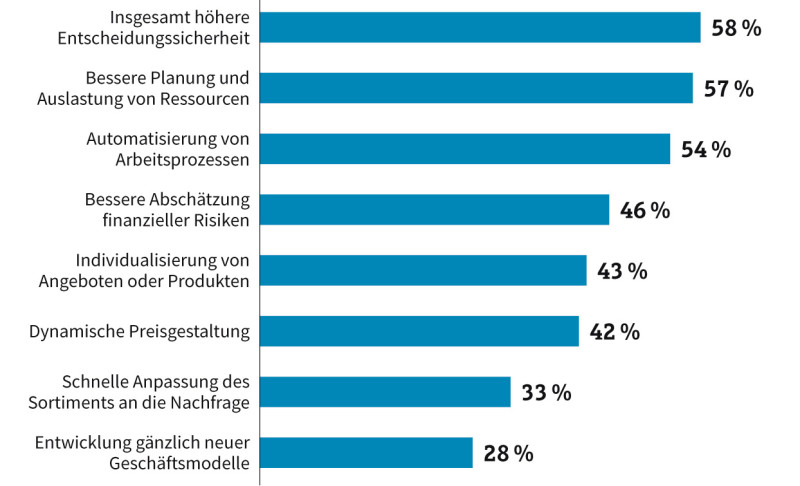
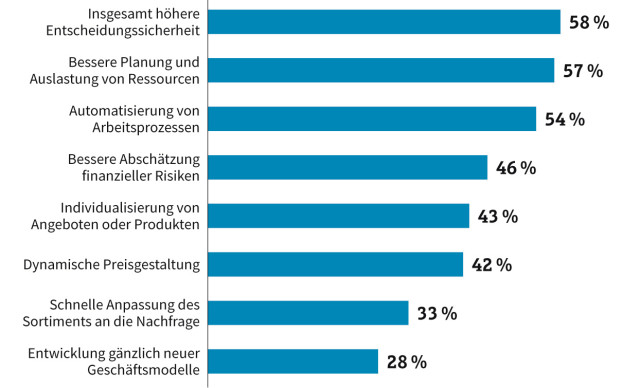 Welche Vorteile ergeben sich aus der Nutzung digitaler Daten? Für die meisten Unternehmen ist das vor allem eine höhere Entscheidungssicherheit.Quelle:Commerzbank-Studie "Der Rohstoff des 21. Jahrhunderts: Big Data, Smart Data - Lost Data?" (Mehrfachnennungen), n = 244
Welche Vorteile ergeben sich aus der Nutzung digitaler Daten? Für die meisten Unternehmen ist das vor allem eine höhere Entscheidungssicherheit.Quelle:Commerzbank-Studie "Der Rohstoff des 21. Jahrhunderts: Big Data, Smart Data - Lost Data?" (Mehrfachnennungen), n = 244
Der Data-Streaming-Spezialist Data Artisans hebt für die Echtzeitdatenverarbeitung die folgenden Aspekte hervor:
Die Art und Weise, wie man im Unternehmen mit Daten umgeht, wird sich verändern: In monolithischen Systemen ruhen die Daten, während sie bei der Verarbeitung von Ereignisströmen laufend in Bewegung sind, um nutzbare Ergebnisse zu gewinnen.
Die Prioritäten zwischen Daten und Aktionen ändern sich: Die Dateninfrastruktur wechselt von einer Fokussierung auf die Aufbewahrung von Daten hin zu einer Reaktion auf Ereignisströme. Der Fokus richtet sich dabei auf den kontinuierlichen Fluss der Stream-Verarbeitung und die Priorisierung des Handelns aufgrund von Ereignissen.
Die Datenquelle wird angepasst: Die Datenstrategie wird sich auf die Datenautorität im Unternehmen auswirken. Von dem Datenspeicher in einer monolithischen Dateninfrastruktur verschiebt sich die Datenautorität hin zum Ereignisprotokoll als Datenquelle.
Die Rolle der Dateninfrastruktur im Unternehmen ändert sich: Mit der Umstellung auf Stream Processing verändert sich die Wahrnehmung der IT- und Datensysteme innerhalb des Unternehmens wesentlich. Die Dateninfrastruktur wird zum zentralen Nervensystem, das es einem Unternehmen ermöglicht, auf Ereignisse in Echtzeit zu reagieren und Entscheidungen zu treffen, genau zu dem Zeitpunkt, zu dem die Daten generiert werden und somit dann, wenn sie am wertvollsten sind.
Die Echtzeitverarbeitung von Daten erfordert in vielen Fällen auch eine grundlegende Veränderung in der IT-Architektur. Wenn man die Analyse nicht auf einen externen Dienstleister wie einen Cloud-Dienst auslagert, dann müssen die eigenen Datenspeicher in der Lage sein, eine sehr große Menge an gleichzeitig anfallenden Daten in sehr kurzer Zeit zu speichern. „Da es sich bei vielen Streaming-Daten um sehr kleine Datenblöcke handelt, die massiv parallel auf das Speichersystem schreiben, sind traditionelle Speichersysteme wie NAS oder Direct-Attached Storage nur bedingt dafür geeignet“, berichtet Markus Grau, Principal System Engineering beim Speicheranbieter Pure Storage. Das sei insbesondere dann der Fall, wenn die Daten auch auf dem gleichen System weiterverarbeitet werden sollen, ohne sie zuvor von einem Datensilo in ein anderes zu kopieren.
Dadurch dass beim Data Stream Processing enorme Mengen von Datenpunkten anfallen, die in kürzester Zeit analysiert werden sollen, setzt man vermehrt Systeme mit flottem Flash-Speicher ein, um diesen erhöhten Anforderungen gerecht zu werden. Hinzu kommt, dass die Datenmengen wie erwähnt stetig zunehmen. Speichersysteme müssen daher in der Lage sein, linear mit dem Volumen der Daten zu wachsen - sei es bei der Performance oder der Kapazität. Zusätzlich dazu sollten die Speichersysteme mit überschaubarem Aufwand verwaltbar bleiben und auch hohe Anforderungen an Verfügbarkeit und Performance erfüllen - möglichst auch im Fehlerfall.
„‚Time to Result‘ ist das neue Messkriterium und dies ist nicht mit traditionellen Architekturen wie Direct-Attached-Storage-Silos oder Data Lakes zu bewältigen“, so Markus Grau. Diese würden schlicht und einfach nicht für das Stream Processing entwickelt.
Grau geht davon aus, dass immer mehr Bereiche in einem Unternehmen einen größeren Anteil ihrer Daten zu Analysezwecken nutzen. Die sogenannten kalten Daten werden daher immer weniger und gleichzeitig steigt der Bedarf an hoch performanten, skalierbaren Speichersystemen zur Analyse der nun „heißen“ Daten.
5. Teil: „Streaming-Lösungen“
Streaming-Lösungen
-


 Quelle: Markets and Markets
Quelle: Markets and Markets

Apache Spark ist momentan eines der beliebtesten Projekte im Data-Streaming-Bereich. Es wurde ursprünglich als Alternative zu MapReduce entwickelt – einem von Google entwickelten Framework, mit dem sich große strukturierte oder unstrukturierte Datenmengen mit hoher Geschwindigkeit verarbeiten lassen. Spark, für die klassische Batch-Verarbeitung konzipiert, wurde im Lauf der Zeit um eine Unterstützung für Streaming-Daten erweitert. Hierfür teilt Spark die Datenströme in kleine sogenannte Micro-Batches auf. Laut Alexander Lemm von der Software AG ist das Open-Source-Tool Spark zwar skalierbar, arbeitet aber mit kleinen Datenmengen und ist daher häufig nicht für Echtzeitanwendungen geeignet, bei denen Entscheidungen sehr schnell getroffen werden müssen. Spark eigne sich gut für die Bearbeitung von Streams als Ganzes, „jedoch nicht unbedingt für die Identifizierung von Mustern innerhalb einzelner Messages in Streams“.
Storm ist ein weiteres Framework für das Data Stream Processing, das unter dem Dach der Apache Foundation weiterentwickelt wird. Es war eines der ersten Open-Source-Frameworks für das Data Streaming. Ein weiteres Apache-Projekt für die Echtzeitdatenverarbeitung ist Kafka.
Das neueste Apache-Projekt für die Echtzeitdatenverarbeitung heißt Flink. Im Unterschied etwa zu Spark oder Kafka wurde Apache Flink von Anfang an für die Datenstromverarbeitung konzipiert. Es entstand an der TU Berlin und bietet mehrere Möglichkeiten der Datenverarbeitung – unter anderem Batch-Streaming oder Machine Learning. Das Projekt hat in letzter Zeit einen deutlichen Schub erhalten, nicht zuletzt aufgrund der besseren Performance im Vergleich zu Spark und wegen seines Fokus auf das Data Streaming. Mehr zu den Unterschieden zwischen Spark und Flink lesen Sie im Interview mit Robert Metzger, Co-Founder und Software Engineer bei Data Artisans, dem Unternehmen hinter Apache Flink, auf Seite 82.
Kommerzielle Lösungen für das Data Streaming gibt es mittlerweile von fast jedem Anbieter von Big-Data- und Business-Intelligence-Tools. Hinzu kommen die Tools der einschlägigen Cloud-Anbieter wie Amazon mit AWS Kinesis, Google mit Cloud Dataflow oder Microsoft mit Azure Stream Analytics.
Wichtige Kriterien bei der Wahl einer Lösung sind Offenheit, Flexibilität und Skalierbarkeit. Eine integrierte analytische Plattform sollte unstrukturierte ebenso wie strukturierte Daten aus unterschiedlichsten Quellen zusammenführen und auswerten können. Schnittstellen sind notwendig, um Daten aus externen Systemen mit einzubinden. Skalierbarkeit ist insofern erforderlich, als die Anforderungen an Datenvolumen ganz unterschiedlich sind: Hin und wieder fallen Datensätze an, die nur einige Byte groß sind,
dafür aber in Abständen von wenigen Millisekunden einfließen. Ein anderes Mal findet in der Edge lediglich die Vorverarbeitung der Daten statt, die im Anschluss auf einen großen Server übertragen und dort ausgewertet werden.
dafür aber in Abständen von wenigen Millisekunden einfließen. Ein anderes Mal findet in der Edge lediglich die Vorverarbeitung der Daten statt, die im Anschluss auf einen großen Server übertragen und dort ausgewertet werden.
Doch auch bei den kommerziellen Angeboten - die teilweise ebenfalls auf Open-Source-Anwendungen zurückgreifen - ist die Wahl einer Lösung nicht unbedingt einfach, wie ein Beispiel zeigt: „Im Fall von Internet of Things hat aktuell kein Anbieter eine komplette End-to-End-Lösung von Sensoren über Gateway-Hardware, Enterprise-Message-Bus-Optionen, Data Lake, CEP (Complex Event Processing) oder Stream Processing Engines“, berichtet Frank Waldenburger von Informatica.
Für Unternehmen stellt sich daher die Frage, ob genügend Zeit und Fachwissen vorhanden sind, um aus den verfügbaren Open-Source-Bausteinen eine eigene Lösung zu entwickeln, oder ob man besser auf ein proprietäres kommerzielles Produkt oder einen Cloud-Dienst setzt.
Wie sollte man als Unternehmen also vorgehen? Cornelius Kimmer von SAS empfiehlt: „Besser als in Tools sollten Unternehmen – grundsätzlich und gerade beim Stream Processing – in Plattformen denken.“
Etwas Ähnliches rät Björn Bartheidel vom IT-Dienstleister Freudenberg IT: „Unternehmen sollten sich nicht zu früh mit konkreten Tools – oder deren Auswahl – beschäftigen, sondern zunächst klare Nutzungskonzepte sowie entsprechende Zielsetzungen und Nutzenerwartungen entwickeln. Die Umsetzung sollte dann Schritt für Schritt erfolgen – immer einhergehend mit der Frage, welche Themen man in den ‚eigenen vier Wänden‘ stemmen kann und an welcher Stelle eine frühe Zusammenarbeit mit den richtigen Partnern sinnvoll sein könnte.“
Letztlich entscheiden laut Stephan Reimann von IBM die Anforderungen des jeweiligen Anwendungsfalles, welche Technologie am besten geeignet ist. Dabei gebe es häufig mehrere gute Lösungen, auch wenn diese teilweise sehr unterschiedlich seien. Sein Tipp: „Anstatt sich auf ein Tool festzulegen, empfiehlt sich die Nutzung einer flexiblen Streaming-Analyse-Plattform, die ausreichend Flexibilität für eine Vielzahl von Anwendungen bereitstellt.“
6. Teil: „Fazit“
Fazit
Die Echtzeitanalyse von Daten gleich wenn sie anfallen wird für viele Unternehmen an Relevanz gewinnen. „Im gleichen Zuge, wie das Internet of Things und Sensordaten immer wichtiger werden, und zwar sowohl für Verbraucher als auch im Businessbereich, wird auch Stream Processing als Methode zur Auswertung der Daten, die dabei entstehen, noch weiter an Bedeutung zunehmen“, so das Resümee von Cornelius Kimmer von SAS. Mehr Rechenleistung, mehr Daten und die erforderlichen Algorithmen zu ihrer Auswertung seien bereits vorhanden - und damit die Voraussetzungen für den Einsatz weiterer moderner Technologien wie Künstlicher Intelligenz (KI) gegeben.
Alexander Lemm von der Software AG stimmt ihm zu: „Die Stream-Verarbeitung und das maschinelle Lernen werden sich einander annähern. Sie bilden eine leistungsfähige Kombination zur Analyse von Daten unter Berücksichtigung zeitlicher und räumlicher Ereignisse, Ereignisbeziehungen und Vorhersagemodelle.“ Insbesondere Stream-Verarbeitungs-Engines, die einen sogenannten Model Serving Service verwenden, der Machine-Learning-Modelle und Deep Neural Networks ausführen kann, hätten einen großen Vorteil. „Darüber hinaus werden wir mehr Log-getriebene Architekturen sehen, die Stream-Prozessoren von den Diensten entkoppeln, die die Quelldaten bereitstellen. Alle Datenaktualisierungen sind direkt im Protokoll verfügbar. Messaging-Plattformen bilden das Rückgrat des Protokolls“, so Lemm weiter. Eine weitere interessante Entwicklung sei die Stream-Verarbeitung für „Nicht-Codierer“, die sich in Zukunft beschleunigen werde, sodass immer mehr Menschen analytische Modelle für Streaming-Daten in Umgebungen mit keinem oder nur wenig Code erstellen und ausführen könnten.
Stephan Reimann von IBM weist auf Stream Processing Everywhere hin, also auf Edge-Computing: In Zukunft werde man die Daten vermehrt nicht nur in Rechenzentren, sondern beispielsweise direkt auf Smartphones oder in industriellen Anlagen analysieren. „Dabei geht es darum, die Abhängigkeit von Übertragungstechnik zu verringern und in jedem Fall in der Lage zu sein, eine Entscheidung lokal und schnellstmöglich zu treffen.“ Er gibt aber zu bedenken: „Wichtig ist, zu verstehen, dass Entscheidungen dann nur auf Basis lokaler Informationen getroffen werden.“ Die Analyseergebnisse von Systemen an anderen Orten lassen sich nicht einbeziehen.
7. Teil: „Im Gespräch mit Robert Metzger von Data Artisans“
Im Gespräch mit Robert Metzger von Data Artisans
-

 Robert Metzger: Co-Founder und Engineering Manager bei Data ArtisansQuelle:Data Artisans
Robert Metzger: Co-Founder und Engineering Manager bei Data ArtisansQuelle:Data Artisans
Robert Metzger, Co-Founder und Software Engineer bei Data Artisans, dem Unternehmen hinter Apache Flink, erklärt dessen Vorteile.
com! professional: Herr Metzger, worin besteht eigentlich der Unterschied zwischen herkömmlicher Datenanalyse und Stream Processing?
Robert Metzger: Anstatt Daten in einer Datenbank oder einem Data Lake zu speichern und abzufragen, um daraus Erkenntnisse zu gewinnen, werden die Daten in Echtzeit verarbeitet und analysiert. Mit Stream Processing werden die Daten sofort in die digitale Wertschöpfungskette eingebunden. Unternehmen gewinnen Erkenntnisse bereits in dem Moment, in dem die Daten produziert werden, also dann, wenn sie am wertvollsten sind, und können unmittelbar darauf reagieren.
com! professional: Das funktioniert ja zum Beispiel auch schon mit Apache Spark - warum wurde zusätzlich Flink entwickelt und was macht Flink anders?
Metzger: Spark war konzipiert als ein besserer Batch-Prozessor im Vergleich zu MapReduce, der die Stream-Verarbeitung durch Aufteilung des Streams in immer kleinere Micro-Batches durchführt. Das Ergebnis ist ein System, das auf den ersten Blick oder in der Proof-of-Concept-Phase für die meisten Stream-Verarbeitungszwecke ausreichend erscheint. In der Praxis ist jedoch oft eine übermäßige Abstimmung von Workload-, Cluster- und Spark-spezifischen Details erforderlich. Apache Flink benutzt intern keine Micro-Batches, sondern verwendet eine Echtzeit-Engine, die Daten ohne Verzögerung verarbeitet.
com! professional: Und für welche Anwendungsfälle eignet sich Flink genau?
Metzger: Apache Flink befasst sich mit verschiedenen Anwendungsfällen, von der Echtzeitbetrugserkennung über das Kapitalrisikomanagement bis hin zu Produktempfehlungen in Echtzeit, Suche, Anomalie-Erkennung und anderen Anwendungen. Seit der Einführung von Apache Flink kommen täglich neue, vielfältige und vor allem umfangreiche Anwendungsfälle bei Unternehmen wie Netflix, Uber, Lyft, Alibaba, ING, Verizon und anderen hinzu.
com! professional: Sie haben kürzlich zusätzlich die Technologie Streaming Ledger vorgestellt. Was hat es damit auf sich?
Metzger: Dabei handelt es sich um eine Technologie für serialisierbare, verteilte ACID-Semantik (Atomicity, Consistency, Isolation, Durability) direkt auf Datenströmen. Diese Technologie öffnet die Türen der Stream-Verarbeitung für eine ganze Reihe neuer Anwendungen, die bisher auf relationale Datenbanken zurückgreifen mussten.
Mit technologischen Fortschritten wie diesem und zunehmender Akzeptanz können wir davon ausgehen, dass die Technologie wachsen, reifen und zum neuen De-facto-Standard-Framework für die Datenverarbeitung avancieren wird, da immer mehr Unternehmen softwaregesteuert und in Echtzeit arbeiten.
com! professional: Unternehmen können heute aus einer Vielzahl von Tools für ihre Analytics-Projekte auswählen - Open-Source-Frameworks wie Spark und Flink oder kommerzielle Software-Lösungen von großen Anbietern. Wie finden sie da überhaupt das für sie Richtige?
Metzger: 95 Prozent der Unternehmen nutzen bereits Open-Source-Software in ihren geschäftskritischen IT-Portfolios, unabhängig davon, ob sie es wissen oder nicht - zum Beispiel indirekt durch kommerzielle proprietäre Software unter Verwendung von Open-Source-Bibliotheken.
Open-Source-Software ermöglicht es dem Chief Information Officer, die zugrundeliegenden Fähigkeiten, Funktionen und Lösungen einer frei verfügbaren Plattform in einem ausgewogenen Ansatz mit anderen Teilnehmern zum gegenseitigen Nutzen weiterzuentwickeln.
Durch die Verkürzung der Innovationsphase für die erwartete Technologie kann sich jede IT-Abteilung auf ihre eigene Differenzierung als Wettbewerbsvorteil konzentrieren und so schneller Innovation und Markteinführung vorantreiben.
Mit der Entscheidung der CIOs für Open-Source-Software und durch Innovationen in der Community wird die Abhängigkeit von bestimmten Anbietern reduziert. Auf diese Weise werden traditionelle und innovative Anbieter dazu angeregt, an einem Ökosystem teilzunehmen, das sich auf Open-Source-Technologien konzentriert, um ihre Vision und Geschäftsstrategie zu verwirklichen.
Umweltschutz
Netcloud erhält ISO 14001 Zertifizierung für Umweltmanagement
Das Schweizer ICT-Unternehmen Netcloud hat sich erstmalig im Rahmen eines Audits nach ISO 14001 zertifizieren lassen. Die ISO-Zertifizierung erkennt an wenn Unternehmen sich nachhaltigen Geschäftspraktiken verpflichten.
>>
Cyberbedrohungen überall
IT-Sicherheit unter der Lupe
Cybersecurity ist essentiell in der IT-Planung, doch Prioritätenkonflikte und die Vielfalt der Aufgaben limitieren oft die Umsetzung. Das größte Sicherheitsrisiko bleibt der Mensch.
>>
Galaxy AI
Samsung bringt KI auf weitere Smartphones und Tablets
Einige weitere, ältere Smartphone- und Tablet-Modelle von Samsung können mit einem Systemupdate jetzt die KI-Funktionen von Galaxy AI nutzen.
>>
Pilot-Features
Google Maps-Funktionen für nachhaltigeres Reisen
Google schafft zusätzliche Möglichkeiten, um umweltfreundlichere Fortbewegungsmittel zu fördern. Künftig werden auf Google Maps verstärkt ÖV- und Fußwege vorgeschlagen, wenn diese zeitlich vergleichbar mit einer Autofahrt sind.
>>