21.12.2018
KI verstehen
1. Teil: „Deep Learning - Königsdisziplin der Künstlichen Intelligenz“
Deep Learning - Königsdisziplin der Künstlichen Intelligenz
Autor: Klaus Manhart



Bild: Shutterstock / Connect world
Das maschinelle Lernverfahren erreicht Ergebnisse, die bisher unmöglich waren. Die Einsatzmöglichkeiten sind dabei ebenso vielfältig wie individuell.
-
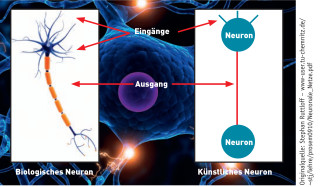
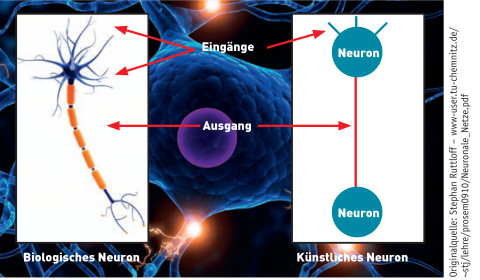
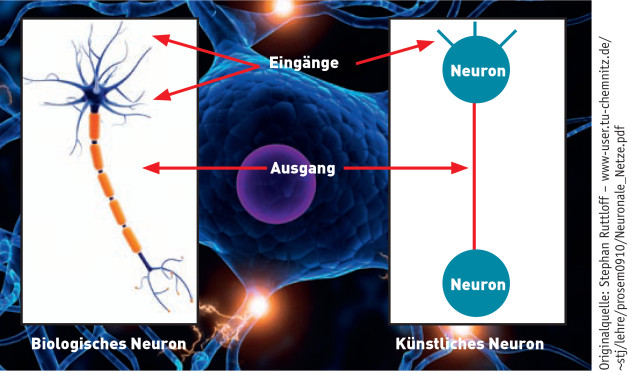
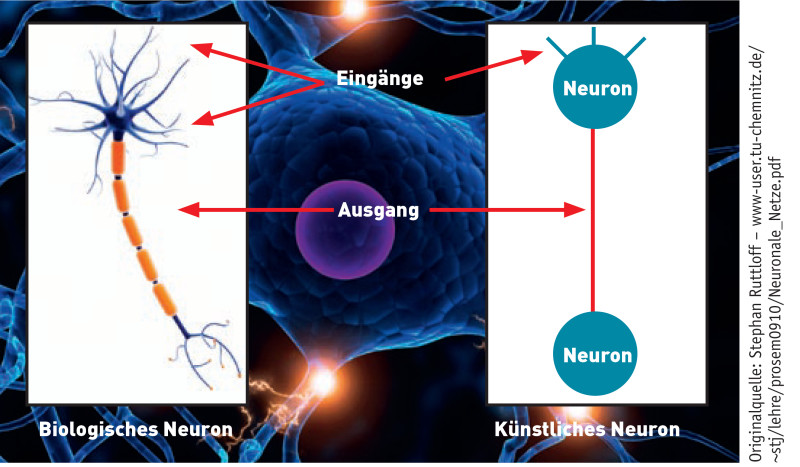
Neuronennetze: Künstliche Netze ahmen Grundprinzipien ihrer biologischen Vorbilder nach. Quelle:Stephan Ruttloff (TU Chemnitz)
Das Potenzial von Deep Learning zeigt sich in zahlreichen Anwendungen: In fahrerlosen Autos sorgt Deep-Learning-Technik dafür, dass Stoppschilder erkannt und ein Fußgänger von Straßenlaternen unterschieden werden kann. Sie ist auch der Schlüssel zur Sprachsteuerung von Geräten wie Smartphones, Tablets und Fernsehern und steckt damit auch hinter dem Spracherkennungsmodul von Siri, dem digitalen Assistenten auf dem iPhone.
Extrem erfolgreich sind Deep-Learning-Netze zudem darin, Bildinhalte zu erfassen. Zum Beispiel kann Deep Learning Millionen von Bildern analysieren und sie nach Ähnlichkeiten gruppieren: Katzen in einen Ordner, Kinderfotos in einen anderen und in einen dritten alle Fotos der Großmutter. Dies ist die Grundlage für Smart-Foto-Alben - also das, was mit den Fotosammlungen auf dem Smartphone schon passiert.
Bereits vor mehreren Jahren gewann eine Software des Schweizer KI-Forschungsinstituts in Lugano den deutschen Wettbewerb für Verkehrszeichenerkennung. Der Algorithmus erkannte zehntausend Verkehrsschilder korrekt, auch wenn sie verdreht, halb verdeckt, im Dunkeln oder im Gegenlicht aufgenommen waren. Mit einer Fehlerrate von nur 0,54 Prozent war der Computer mehr als doppelt so gut wie eine menschliche Vergleichsgruppe.
Neue Anwendungen
Inzwischen wird Deep Learning auch für viele wissenschaftliche Aufgaben herangezogen. US-Forscher haben die KI-Technik anhand von Gewebebildern die Überlebensrate von Krebspatienten vorhersagen lassen. Die Algorithmen lernten anhand verdächtiger Merkmale Krebszellen von gesunden Zellen zu unterscheiden. Zur Verblüffung der Wissenschaftler entdeckte Deep Learning am Ende mehr solcher Merkmale als in der medizinischen Literatur bekannt waren.
Ähnliche Erfolge wie bei der Bilderkennung erzielt Deep Learning in der Sprachsteuerung und Spracherkennung. So basiert die Sprachsteuerung von Amazon Alexa, Google Home und Facebook Deep Text auf Deep Learning. Hier eröffnen sich gerade auch Unternehmen vielfältige Anwendungsmöglichkeiten, etwa im Service, im Callcenter oder zu Predictive-Maintenance-Zwecken in der Produktion.
Deep Learning kann beispielsweise Rohtexte wie E-Mails oder News bündeln. E-Mails mit Beschwerden können in einem Ordner gesammelt werden, während die Mails zufriedener Kunden in einem anderen Bereich abgelegt werden. Dies kann als Grundlage für verschiedene Messaging-Filter dienen und im Customer Relationship Management genutzt werden.
Im Callcenter können mit Deep Learning Anrufe automatisch bewertet werden, was ein umfassendes Audio-Scoring und damit ein Verbesserung der Lead-Qualifizierung ermöglicht. Und selbst vor menschlichen Gefühlen macht der Lernalgorithmus nicht halt. Inzwischen erkennen Deep-Learning-Netze Gefühle präziser und schneller als die meisten Menschen. Ein Programm der US-Firma Affectiva konnte sogar ein echtes von einem falschen Lächeln unterscheiden.
Was aber ist das Erfolgsgeheimnis von Deep Learning? Das Lernverfahren führt dazu, dass der Computer eine Fähigkeit erlangt, die Menschen von Natur aus haben: aus Beispielen zu lernen. Bei Deep Learning lernt ein Computermodell, aus Bildern, Texten oder akustischen Daten Objekte richtig zu erkennen - ähnlich wie ein Mensch. Nur schneller und genauer.
2. Teil: „Alles dreht sich um Neuronen“
Alles dreht sich um Neuronen
-
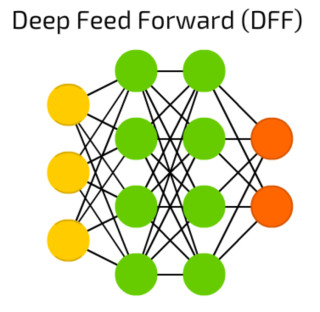
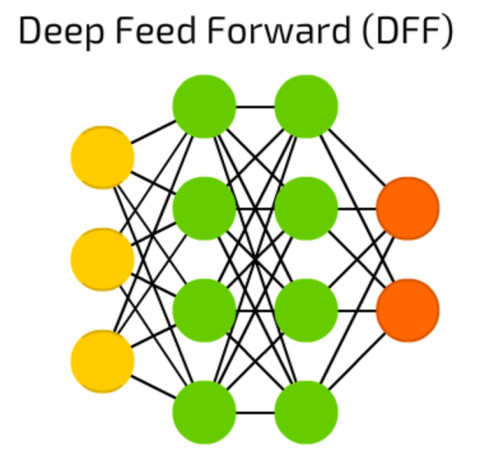
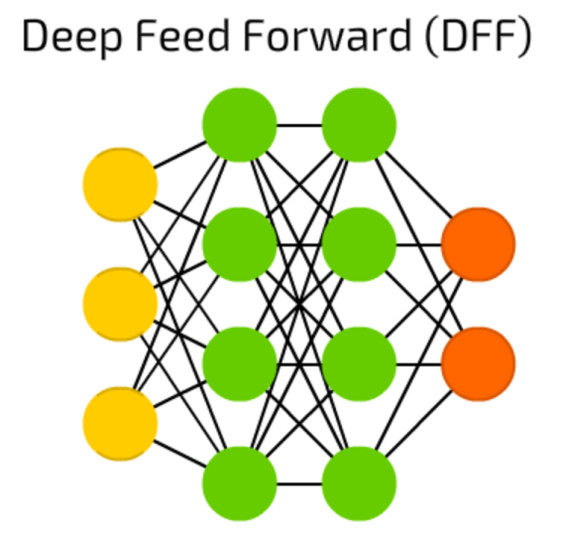
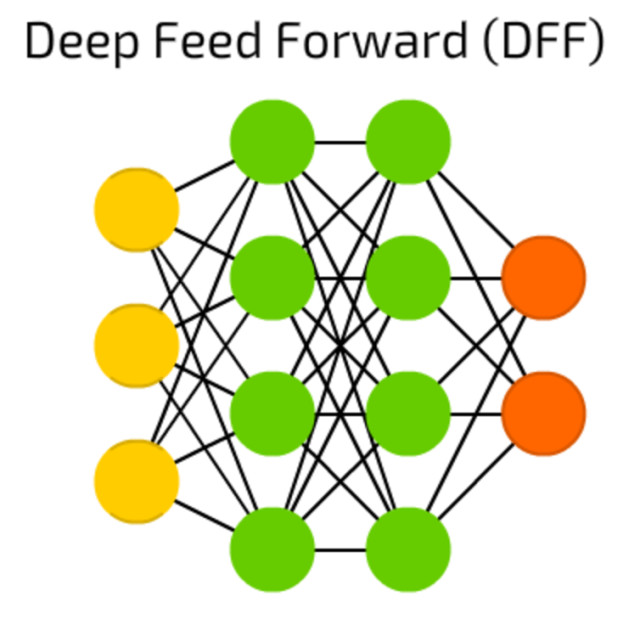 Feed-Forward-Netze: Diese Form eines neuronalen Netzes besteht aus einer Input-Schicht, einem oder mehreren Hidden Layern und einer Output-Schicht.Quelle:Towardsdatascience.com
Feed-Forward-Netze: Diese Form eines neuronalen Netzes besteht aus einer Input-Schicht, einem oder mehreren Hidden Layern und einer Output-Schicht.Quelle:Towardsdatascience.com
Um neuronale Netze und Deep Learning ansatzweise zu verstehen, braucht man einiges an Hintergrundwissen. Die elementaren Bausteine und Knotenpunkte in einem neuronalen Netzwerk - natürlich wie künstlich - bilden Neuronen. An jedem einzelnen Neuron treffen ein oder mehrere Eingangssignale zusammen. Diese Eingangssignale sind numerische Daten und werden von jedem Neuron aufgenommen (Input), verarbeitet und in Form neuer Signale an die nächste Gruppe von Neuronen weitergegeben (Output). Die Signale, die ein Neuron empfängt, stammen - je nachdem an welcher Stelle sich das Neuron im Netzwerk befindet - entweder von vorhergehenden Neuronen oder direkt von den eingehenden Daten.
Jedes Neuron errechnet aus den Inputs der Neuronen oder der Eingangsdaten eine sogenannte Aktivierungsfunktion. Sie legt fest, ob das Neuron im nächsten Zeitschritt aktiv oder nicht aktiv ist. Ist es aktiv, „feuert“ das Neuron und gibt Signale weiter; ist es nicht aktiv, gibt es keine Information weiter. Die Verbindungen zwischen den künstlichen Neuronen können dabei wie im menschlichen Gehirn stärker oder schwächer sein und werden durch Gewichte ausgedrückt.
Diese Neuronen-Verknüpfungen sind der entscheidende Faktor in einem neuronalen Netz. Je stärker die Verbindung und je größer damit das Gewicht ist, desto größer ist auch der Einfluss eines Neurons auf ein anderes. Ein positives Gewicht übt auf ein anderes Neuron also einen erregenden, verstärkenden Einfluss auf, ein negatives einen hemmenden.
Entscheidend ist: In der Veränderung der Gewichte ist der Lernfortschritt begründet. Die Gewichte werden im Verlauf des Trainings so angepasst, dass der Fehler, den das neuronale Netz während des Trainings macht, immer kleiner wird. Dafür wird berechnet, wie sehr die Schätzung des Netzwerks von den tatsächlich beobachteten Datenpunkten abweicht. Nach der Ermittlung des Gesamtfehlers werden die Gewichte des Netzes rekursiv upgedatet. Dabei wird so aktualisiert, dass der Fehler im nächsten Durchlauf kleiner wird. Man kann sagen: Das Wissen eines neuronalen Netzes ist in den Gewichten gespeichert.
Mehrere Ebenen
Auf diesen Grundprinzipien basieren Deep-Learning-Netze. Sie können als spezielle neuronale Netze verstanden werden, die besonders „tief“ sind. Frühere Versionen neuronaler Netze bestanden lediglich aus einer Eingangs- und einer Ausgangsschicht und höchstens einer Neuronenschicht dazwischen, sie waren „flach“. Heute werden neuronale Netze mit zahlreichen Zwischenschichten zwischen Eingangs- und Ausgangsschicht modelliert - das können durchaus 150 und 200 Schichten sein. Diese Schichten werden als Hidden Layer bezeichnet „Hidden“, weil sie von außen quasi unsichtbar sind. Durch diese Hidden -Layer fließen die Daten in einem mehrstufigen Prozess der Mustererkennung.
Das Spezielle an Deep Learning ist nun, dass die Neuronen in sehr viele solcher Schichten eingeteilt werden. Diese zahlreichen Hidden Layer verleihen Deep-Learning-Netzen eine komplexe innere Struktur - was sie zur Lösung anspruchsvoller Aufgaben prädestiniert: Je mehr Schichten und je mehr Knotenpunkte ein künstliches neuronales Netz enthält, desto komplexere Aufgaben können von ihm gelöst werden.
Jede Schicht erledigt beim Training des Netzes bestimmte Aufgaben und identifiziert Merkmale, die auf dem Output der vorherigen Schicht basieren. In jeder Neuronenschicht werden neue Informationen generiert, die anhand der Daten der vorherigen Schicht gewonnen werden. Das bedeutet: Je weiter man in das neuronale Netz vordringt, desto komplexer werden die Merkmale, die die Neuronen erkennen können, da sie Eigenschaften aus der vorherigen Schicht aggregieren und rekombinieren. Das Endergebnis wird im sichtbaren Output Layer, der letzten Schicht, ausgegeben.
Ein Beispiel veranschaulicht das Prinzip: Soll Deep Learning ein Bild erkennen, registrieren die Einheiten der ersten Schicht nur die Helligkeitswerte einzelner Pixel. Die nächste Ebene erkennt, dass einige Pixel miteinander zu Kanten verbunden sind. Die dritte unterscheidet zwischen horizontalen und vertikalen Linien und so weiter, bis in den hinteren Ebenen die Neuronen Augen auseinanderhalten und das System weiß, dass in einem Gesicht typischerweise zwei davon auftauchen. Diese aufsteigende Hierarchie mit zunehmender Komplexität und Abstraktion von Merkmalen heißt Feature-Hierarchie. Sie versetzt Deep-Learning-Netzwerke in die Lage, sehr große, hochdimensionale Datensätze mit Milliarden von Parametern zu verarbeiten.
3. Teil: „Architektur von Deep Learning“
Architektur von Deep Learning
-


 Quelle: McKinsey Global Institut
Quelle: McKinsey Global Institut

Eine oft genutzte einfache Architektur sind Feed-Forward-Netze: Sie bestehen aus einer Input-Schicht, einem oder mehreren Hidden Layern und einer Output-Schicht. Die Hidden Layer bilden voll vernetzte Neuronen mit Gewichtungen zu allen Neuronen der vorherigen und folgenden Schicht. Deutlich komplexer sind Convolutional Neural Networks (CNNs), zu Deutsch: neuronale Faltungsnetzwerke. Sie haben maßgeblich zum Aufschwung bei der Bilderkennung beigetragen.
CNNs verdanken ihren Namen dem dahinterliegenden Konzept aus sich überlappenden Neuronen und werden vor allem in der Mustererkennung eingesetzt. Sie bestehen meist aus fünf bis 20 Neuronenschichten, mit denen sie die entsprechende Fähigkeit erlernen. Dabei werden zwei spezielle Schichten verwendet, die Convolutional und die Pooling Layer, mit denen der Input aus verschiedenen Perspektiven untersucht wird. Jedes einzelne Neuron im Convolutional Layer überprüft einen bestimmten Bereich des Input-Feldes mit Hilfe eines Filters, dem Kernel.
Ein Filter untersucht das Bild auf eine bestimmte Eigenschaft, etwa die Farbzusammensetzung oder die Helligkeit. Das Resultat eines Filters ist der gewichtete Input eines Bereichs und wird im Convolutional Layer gespeichert. Pooling vereinfacht die Ausgabe durch nicht lineares Downsampling und reduziert die Anzahl der Parameter, die das Netzwerk kennenlernen muss. Das Design eines CNNs orientiert sich an der Sehrinde im Gehirn. Sie enthält eine Reihe von Zellen, die dafür zuständig sind, Licht in kleinen, sich überlappenden Unterbereichen des Gesichtsfelds zu erkennen. Diese Rezeptorenfelder agieren als lokale Filter für den Eingabebereich, während komplexere Zellen größere Rezeptorenfelder haben. Die Convolutional-Schicht in einem CNN führt die gleiche Funktion aus wie die Zellen in der Sehrinde. Ein Beispiel für ein solches neuronales Faltungsnetzwerk ist GoogLeNet. Dieses CNN wird auf mehr als einer Million Bildern aus der ImageNet-Datenbank trainiert. Es besteht aus 22 Schichten und kann Bilder in 1000 Objektkategorien einteilen.
4. Teil: „Daten, Modelle und GPUs“
Daten, Modelle und GPUs
Die Architekturen deuten es an: Deep Learning ist im Vergleich zu anderen Machine-Learning-Verfahren hochkomplex. Dennoch lohnt der Aufwand - besonders im wirtschaftlichen Umfeld. „Der Einsatz dieser hochentwickelten KI-Methoden stellt Unternehmen vor erhebliche organisatorische Herausforderungen“, weiß Peter Breuer, Senior Partner bei McKinsey in Köln und deutscher Leiter von McKinsey Advanced Analytics. Aber: „Der Mehrwert, den diese Methoden generieren, übertrifft den Aufwand um ein Vielfaches.“
Wie aber geht man Deep-Learning-Projekte am besten an? Ein zentraler Erfolgsfaktor ist eine möglichst große Anzahl qualitativ hochwertiger Daten für das Training der neuronalen Netze. Im Fall der Bilderkennung sind für die automatisierte Merkmalsextraktion und das Training Tausende von Bildern notwendig: Für die Entwicklung eines fahrerlosen Autos sind Millionen Bilder und Tausende Stunden Video durchaus im Bereich des Üblichen.
Wegen der riesigen Datenmengen kann das Training eines Deep-Learning-Modells viel Zeit in Anspruch nehmen - von einigen Tagen bis zu mehreren Wochen. Dieser Zeitaufwand lässt sich durch geschicktes Vorgehen und vor allem durch parallelisierte und leistungsstarke, schnelle Hardware reduzieren. Als Hardware haben sich im Deep-Learning-Umfeld Grafikprozessoren (GPUs) etabliert.
Normalerweise wird ein Netzwerk generiert, indem man eine große Menge von Daten zu einem Problem sammelt und dann eine Architektur und ein Modell entwirft, das die gewünschten Merkmale lernen soll. Dieser Ansatz wird vor allem wegen des Zeit- und Modellierungsaufwands aber kaum angewendet. In der Praxis nutzt man heute vielfach Transfer-Learning. Beim Transfer-Learning wird ein bereits bestehendes, vortrainiertes Modell eingesetzt und verfeinert.
Generell bieten sich für die Entwicklung von Deep-Learning-Modellen und -Architekturen Frameworks und Tools wie TensorFlow oder Torch an. Da sie in der Regel Open Source sind, können interessierte Entwickler problemlos darauf zugreifen. Auch Cloud-Services werden inzwischen für Deep Learning bereitgestellt. Kommerzielle Entwicklungssysteme sind ebenfalls verfügbar. Ein Beispiel dafür ist MissingLink.ai, eine Deep-Learning-Plattform, die Dateningenieuren dabei hilft, den gesamten Deep-Learning-Zyklus von Daten, Code, Experimenten und Ressourcen zu optimieren und zu automatisieren. Die Plattform eliminiert die Routinearbeit und verkürzt die Zeit, die für die Schulung und Bereitstellung effektiver Modelle benötigt wird.
Deep Learning macht also enorme Fortschritte dabei, sein Potenzial auszuspielen. Ein Potenzial, das gar nicht groß genug eingeschätzt werden kann, wenn es nach Damian Borth geht, Professor für Artificial Intelligence und Machine Learning an der Universität St. Gallen: „Deep Learning wird die Unternehmenswelt so verändern wie einst das Internet.“
5. Teil: „Im Gespräch mit Yosi Taguri, Gründer von MissingLink.ai“
Im Gespräch mit Yosi Taguri, Gründer von MissingLink.ai
-

 Yosi Taguri: Gründer von MissingLink.aiQuelle:MissingLink
Yosi Taguri: Gründer von MissingLink.aiQuelle:MissingLink
Im Gespräch mit com! professional äußert sich Yosi Taguri zu den gegenwärtigen Möglichkeiten und Grenzen von Deep Learning.
com! professional: Wie beurteilen Sie das Potenzial von Deep Learning?
Yosi Taguri: In den letzten 20 Jahren haben Unternehmen eine Vielzahl von Daten erfasst. Ebenso haben wir im gleichen Zeitraum eine massive Zunahme der Rechenleistung erreicht. Mit diesen Zutaten wird die KI in den nächsten Jahren endlich wirklich intelligent. Und das Potenzial von Deep Learning ist schon jetzt groß und wächst. Die gute Nachricht ist, dass unsere Technologie beginnt, dieses Potenzial auszuschöpfen.
com! professional: Was ist für Sie ein herausragender Deep-Learning-Use-Case?
Taguri: Deep-Learning-Anwendungen können heute schon Krankheiten durch verbesserte Algorithmen schneller und genauer als der Arzt erkennen und diagnostizieren. Einer der Kunden von MissingLink.ai - Aidoc.com - hat ein Deep-Learning-Modell entwickelt, das medizinische Bilder analysiert, um Anomalien im gesamten Körper zu erkennen, Radiologen dabei zu unterstützen und lebensbedrohliche Fälle zu priorisieren.
com! professional: Welches weitere Beispiel würden Sie hervorheben wollen?
Taguri: Ein weiteres Beispiel ist das Google Deep Learning System, dem 10 Millionen Bilder aus Youtube-Videos gezeigt wurden. Das Lernsystem hat sich fast als doppelt so gut erwiesen wie alle bisherigen Verfahren zur Bilderkennung. Google hat die Technologie auch dafür genutzt, um die Fehlerquote bei der Spracherkennung in seiner neuesten mobilen Android-Software zu senken.
Und apropos Potenzial: Wussten Sie, dass in Amerika durch autonome Fahrzeuge 300.000 Menschenleben pro Jahrzehnt gerettet werden könnten?
com! professional: Welche Branchen und Anwendungen werden vom Deep Learning am meisten profitieren?
Taguri: Daten und Rechenleistung sind die beiden Dinge, die Sie benötigen, um ein Deep-Learning-Modell zu trainieren. Stand heute wird es deshalb am häufigsten in der Gesundheits- und Automobilindustrie eingesetzt. Die Gesundheitsbranche ist in der glücklichen Lage, über eine Fülle von Daten von Regierungsstellen, Krankenhäusern und Gesundheitsorganisationen zu verfügen. Es gibt Milliarden von Datensätzen, die viele Jahrzehnte zurückreichen und noch nicht vollständig analysiert wurden. Diese können für die zukünftige Prävention und Versorgung von Krankheiten genutzt werden.
Die Automobilbranche ist der zweite wichtige Pfeiler: Autokonzerne in den Vereinigten Staaten sind mit ihrer Technologie bald so weit, dass Fahrzeuge autonom von Küste zu Küste navigieren können. In den nächsten Jahren werden Autos wahrscheinlich auch durch KI-gesteuerte Sprachtechnologien in natürlicher Sprache gesteuert werden können. Und nicht zuletzt sind Cybersicherheit, E-Commerce und Kundensupport weitere Bereiche, in denen die KI in den nächsten Jahren schnell wachsen und sich verbessern wird. KI und Deep Learning werden künftig in sämtlichen Branchen genutzt– das ist nur eine Frage der Zeit.
com! professional: Wo sehen Sie die größten Barrieren bei der Einführung von Deep-Learning-Netzwerken?
Taguri: Es gibt aus meiner Sicht drei Haupthindernisse für die breite Akzeptanz von KI und Deep Learning. Das fängt schon beim fehlenden Datenzugriff an. Daten sind neben Rechenpower eine der Säulen für jede erfolgreiche Deep-Learning-Anwendung. Der Zugriff auf Daten, die Kennzeichnung dieser Daten und deren effektive Verwaltung ist ein Muss für einen erfolgreichen und präzisen Deep-Learning-Algorithmus. Das ist in der Praxis oft nicht gegeben.
Hinzu kommen mangelnde Standardisierung und ineffiziente Methoden. Um die Entwicklung von Deep-Learning-Modellen zu beschleunigen und die Qualität zu verbessern, brauchen wir mehr Standardisierung und effizientere Methoden.
Und schließlich sehe ich eine Qualifikationslücke. Mit das größte Hindernis für den erfolgreichen Einsatz von KI- und Deep-Learning-Tools ist der Mangel an Fachleuten. Viele Unternehmen haben Schwierigkeiten, qualifizierte Fachkräfte zu finden oder ihre Mitarbeiter mit entsprechenden Fähigkeiten und Wissen auszustatten, um das volle Potenzial von Deep Learning und KI auszuschöpfen.
com! professional: Welche Art von Tools würden Sie den Anwendern empfehlen?
Taguri: Für einen Datenwissenschaftler, der Deep-Learning-Algorithmen entwickelt, brauchen Sie drei Dinge. Erstens Experiment-Management, also Tools zur Durchführung, Verfolgung, Reproduktion, Verwaltung und Analyse von Experimenten. Zweitens Daten-Management, das heißt, der Datenwissenschaftler muss seine Daten streamen, bearbeiten, untersuchen und versionieren können. Und drittens Ressourcen-Management, da die Unternehmen Rechenleistung benötigen, um Hunderte Experimente pro Tag durchführen zu können.
Die Verwaltung der Infrastruktur hat sich als kostspielig und zeitaufwendig erwiesen. MissingLink DeepOps - eine neue Kategorie für Deep Learning plus Ops-Tools - haben geholfen, den Schmerz zu lindern und das Deep-Learning- Training zu beschleunigen.
com! professional: Welche Hardware empfehlen Sie für Deep-Learning-Apps?
Taguri: Die benötigte Hardware hängt stark von der Größe des Netzes und der Menge und dem Umfang der Daten ab. Im Allgemeinen - wenn Sie komplexe Modelle auf großen Datensätzen trainieren möchten - sollten Sie GPUs verwenden, um sowohl das Training als auch den produktiven Einsatz zu optimieren. Bei sehr großen Datensätzen sollten Sie eine stärkere Maschine verwenden. Auch mehrere GPUs beschleunigen das Training und die Auswertung.
Wir haben viele Kunden, die Maschinen lokal im Unternehmen einsetzen, um die Kosten für Schulungen zu senken. Diese „Schulungsmaschinen“ werden oft durch ein Cloud-Konto ergänzt. Das ermöglicht eine größere Flexibilität bei der Berechnung von Ressourcen, falls diese steigen.
Elektronikgeräte
EU-Parlament beschließt Recht auf Reparatur für Verbraucher
Das EU-Parlament hat nun das schon länger angekündigte neue "Recht auf Reparatur" für Verbraucher in Europa beschlossen. Die Hersteller von Haushaltsgeräten und Alltagsprodukten müssen mindestens eine Reparaturoption anbieten.
>>
Teldat-Tochter
Bintec Elmeg stellt den Betrieb ein
Auf LinkedIn teilt der Hersteller mit, dass Bintec Elmeg seine Aktivitäten in der DACH-Region einstellt. Die Sanierung sein gescheitert, so heißt es offiziell.
>>
Für 149 Euro
Epos Impact 700 – USB-Headset mit Busylight für Callcenter
Vom Headset-Spezialisten Epos kommt mit dem Impact 700 ein neues Gerät für Mitarbeiter in Callcentern. Es kostet 149 Euro und bietet unter anderem ein Busylight, um anderen Kollegen zu signalisieren, dass man gerade im Gespräch ist.
>>
Forschung
KI macht Gebärdensprache zugänglicher
Ein KI-Tool der Universität Leiden für "Wörterbücher" erkennt Positionen und Bewegungen der Hände bei der Darstellung unterschiedlicher Gebärdensprachen.
>>