18.09.2019
Anonymisierung
1. Teil: „Daten trotz DSGVO ohne Einschränkung nutzen“
Daten trotz DSGVO ohne Einschränkung nutzen
Autor: Klaus Manhart



Bild: Shutterstock / Lightspring
Anonymisierungsverfahren ermöglichen es, Daten in vollem Umfang zu verwerten, ohne dabei gegen die Vorgaben der EU-Datenschutz-Grundverordnung zu verstoßen.
Seit Inkrafttreten der EU-Datenschutz-Grundverordnung (DSGVO) im Mai 2018 stecken Unternehmen in der Zwickmühle: Einerseits verlangt die DSGVO, die persönlichen Daten der Kunden zu schützen und sie auf Verlangen sogar zu löschen, andererseits sind Unternehmen auf diese Daten für Tests und Analysezwecke angewiesen. Gerade die schützenswerten Kundendaten müssen ausgewertet werden, um das Business zu optimieren und die eigene Klientel besser bedienen zu können.
Besonders betroffen von diesem Datenschutz-Dilemma sind Betriebe und Forschungseinrichtungen, die mit großen Datensätzen arbeiten und Analytics und neue Technologien wie KI oder IoT zwingend benötigen. Gerade KI beispielsweise braucht große Datenmengen, um in Machine-Learning-Modellen trainiert werden zu können. Nur können viele KI-Anwender diese Daten wegen der DGSVO-Regularien nicht nutzen.
„Datenschutz und Datensicherheit sind die beiden größten Probleme in Unternehmen, die schon Big-Data-Initiativen in ihren Unternehmensprozessen implementiert haben“, lautete bereits 2015 ein zentrales Ergebnis der BARC-Studie „Big Data Use Cases“. Analysen über die Wünsche, Motive, Bedürfnisse sowie das Verhalten der Kunden - eines der häufigsten strategischen Ziele solcher Projekte - kollidieren mit den zu schützenden Kundendaten, heißt es in dem Report.
Mit der DSGVO hat sich die Situation weiter verschärft. Nicht nur die Wirtschaft stöhnt unter den DSGVO-Auflagen. In Wissenschaft und Medizin kann der strenge Datenschutz den Fortschritt und neue Erkenntnisse behindern: „Gesundheitsdaten werden oft nur wegen der DSGVO weggeschlossen“, berichtet etwa Sebastian Weyer, CEO des Berliner Start-ups Statice, das mit seinen Verfahren medizinische Daten anonymisieren will. „Dabei haben diese Daten für die Forschung großen Mehrwert. Ein Algorithmus könnte zum Beispiel die Wahrscheinlichkeit oder das Risiko von Krankheiten ausrechnen. Dafür bräuchte er aber spezielle Daten. Die sind momentan leider nur schwer oder gar nicht zugänglich.“
Herausforderung DSGVO
Trotz der unbestreitbaren Vorteile der DSGVO für den Datenschutz - die Kollateralschäden der Verordnung sind hoch: Viele Unternehmen sind so verunsichert, dass aufgrund von Bedenken Data Analytics reduziert oder ganz eingestellt wird. Dem Beratungshaus PwC zufolge stellt die DSGVO für 92 Prozent aller US-Unternehmen die größte Herausforderung im Datenschutz dar. Denn auch US-Firmen sind von der europäischen Datenschutz-Regelung betroffen, wenn sie persönliche Daten von EU-Bürgern sammeln.
Die PwC-Analysten fordern deshalb „sichere, automatisierte und einfach zu handhabende Technologielösungen, die sensible Daten nach dem Grundsatz ‚Privacy by Design‘ durch ein Gesamtkonzept schützen“. Hinter „Privacy by Design“ oder „Privacy by Default“ verbirgt sich nichts anderes als „Datenschutz durch Technikgestaltung“ - die Idee, dass der Datenschutz am besten eingehalten wird, wenn er bereits technisch integriert ist. Die DSGVO selbst schlägt mit Blick auf diese Herausforderungen die Pseudonymisierung oder Anonymisierung personenbezogener Daten vor - zwei zentrale Begriffe, die in der Verordnung eine wichtige Rolle spielen.
Auch die Aufsichtsbehörden für den Datenschutz betonen die Bedeutung von Pseudonymisierung und Anonymisierung bei der Nutzung von Kundendaten. „Ich setze darauf, dass die strengen Regeln der Datenschutz-Grundverordnung einen Anreiz für die europäische Digitalwirtschaft darstellen, datenschutzfreundliche Anwendungen zu entwickeln und diese am Markt als Qualitätsprodukte zu platzieren“, erklärte etwa Andrea Voßhoff, zum Zeitpunkt der DSGVO-Umsetzung Bundesbeauftragte für den Datenschutz und die Informationsfreiheit. „Gerade die Entwicklung von Anonymisierungs- und Pseudonymisierungsverfahren als Privacy-by-Default-Lösungen stellen einen wichtigen Beitrag zur Wahrung des Datenschutzes dar.“ Auch der Digitalverband Bitkom empfiehlt in seinen „Leitlinien für den Big-Data-Einsatz“, bevorzugt anonymisierte oder pseudonymisierte Daten zu verarbeiten.
2. Teil: „Anonym vs. Pseudonym“
Anonym vs. Pseudonym
Pseudonymisierung löst allerdings nicht das Problem, die Daten frei etwa für analytische Zwecke nutzen zu können. Laut Artikel 32 Absatz 1 der DSGVO trägt die Pseudonymisierung personenbezogener Daten zwar dazu bei, die Sicherheit der Verarbeitung personenbezogener Daten zu erhöhen, und unterstützt die Verantwortlichen, ihre Datenschutzpflichten einzuhalten, denn wer personenbezogene Daten pseudonymisiert, kann die Risiken für die betroffenen Personen senken.
Aber: „Auch pseudonymisierte Daten unterliegen als Informationen über eine identifizierbare natürliche Person dem Datenschutz“, heißt es dazu auf dem Online-Portal Datenschutz-praxis.de. „Denn sie lassen sich durch Heranziehung zusätzlicher Informationen einer natürlichen Person zuordnen.“ Die DSGVO gilt also auch für pseudonymisierte Daten. Auf der sicheren Seite mit dem Ziel einer freien Verwendung der Daten ist man erst mit anonymisierten Daten.
Felix Bauer, CEO des Start-ups Aircloak, weist in seinen „7 Mythen der Datenanonymisierung“ deshalb Kritik an einer angeblichen Unklarheit der DSGVO in diesem Punkt auch zurück: „An vielen Stellen hätte man sich die DSGVO vielleicht noch konkreter gewünscht - aber in der Unterscheidung zwischen Anonymisierung und Pseudonymisierung wurde klar Stellung bezogen: Nur anonymisierte Daten sind wirklich nicht mehr persönlich und können deswegen weitreichend und ohne datenschutzrechtliche Einschränkungen eingesetzt werden.“
In „Erwägungsgrund 26“ der DSGVO heißt es explizit: „Die Grundsätze des Datenschutzes sollten daher nicht für anonyme Informationen gelten, das heißt für Informationen, die sich nicht auf eine identifizierte oder identifizierbare natürliche Person beziehen, oder personenbezogene Daten, die in einer Weise anonymisiert worden sind, dass die betroffene Person nicht oder nicht mehr identifiziert werden kann. Diese Verordnung betrifft somit nicht die Verarbeitung solcher anonymer Daten, auch für statistische oder für Forschungszwecke.“
Anders gesagt: Für anonymisierte Daten gilt die DSGVO nicht. Unternehmen können mit diesen Daten frei agieren: sie auswerten, mit anderen teilen und weitergeben. Vorschriften wie beispielsweise die Zweckbindung der Datenverarbeitung oder die Einhaltung von Löschpflichten entfallen. Weil anonymisierte Daten nicht mehr persönlich sind, können sie weitreichend und ohne datenschutzrechtliche Einschränkungen eingesetzt werden.
3. Teil: „Datenmaskierung reicht nicht“
Datenmaskierung reicht nicht
-

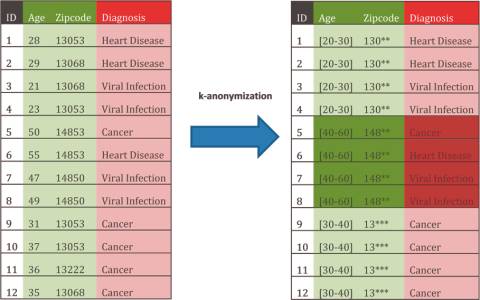
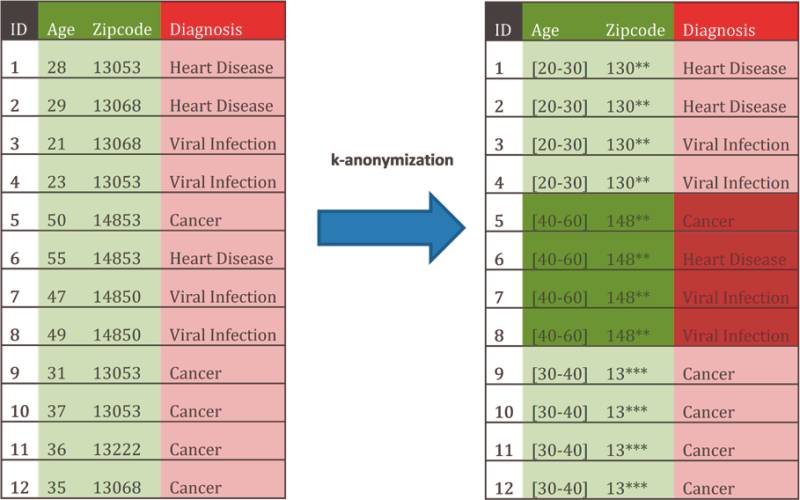
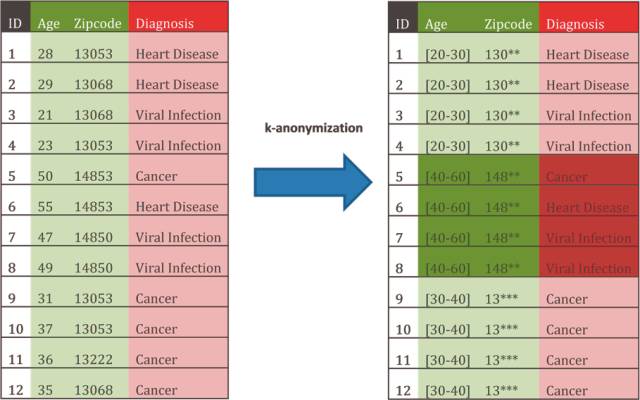 Tools wie Amnesia nutzen k-Anonymisierung: Alter und PLZ sind in diesem Beispiel Quasi-Indikatoren – diese Daten werden verallgemeinert.Quelle:Johner-Institut
Tools wie Amnesia nutzen k-Anonymisierung: Alter und PLZ sind in diesem Beispiel Quasi-Indikatoren – diese Daten werden verallgemeinert.Quelle:Johner-Institut
Beispiele für solche Data-Masking-Module sind Informatica Data Masking, Oracle Data Masking, SQL Server, IBM InfoSphere Optim Data Masking und MariaDB MaxScale.
Data Masking hat seinen Nutzen und seine Berechtigung dann, wenn bestimmte Daten aus Datenschutzgründen vor nicht berechtigten Benutzern verborgen werden sollen. Die maskierten Daten können beispielsweise für Software-Tests oder Benutzerschulungen verwendet werden. Für die unumschränkte Nutzung von Datensätzen etwa zur Datenanalyse ist Data Masking hingegen nicht geeignet.
Data Masking unterscheidet sich von der strengeren Anonymisierung - ebenso wie Pseudonymisierung - dadurch, dass maskierte Daten immer noch Identifikationsmerkmale enthalten. Diese können - zumindest durch „Heranziehung zusätzlicher Informationen“, wie die DSGVO ausführt - eine Zuordnung zu einer Person möglich machen. So konnte eine US-Forscherin durch Kombination eines maskierten medizinischen Datensatzes mit einem öffentlich zugänglichen Wahlregister die persönliche Krankenakte des Senators von Massachusetts identifizieren und ihm zuzuschicken. Bei korrekt anonymisierten Daten wäre dies unmöglich.
Data Masking begrenzt eine unumschränkte Datennutzung aber auch aus anderen Gründen: Zum einen können maskierte beziehungsweise verschlüsselte Daten nicht einfach veröffentlicht oder weitergegeben werden. Zum anderen kann der Schlüssel zur Dekodierung auch Unbefugten in die Hände fallen. Zudem lassen sich maskierte Datensätze nicht ohne Weiteres für die Zwecke analytischer Auswertungen gebrauchen. „Datenmaskierung ist zwar ganz praktisch für Use Cases, die beispielsweise Statistiken auslesen oder Dashboards bauen, sagt Statice-CEO Weyer. „Die meisten Unternehmen wollen aber Daten komplexer nutzen. Weil Daten natürlich gerade für Machine Learning eine unheimlich wertvolle Ressource sind, kann dies durch Query Interfaces nicht gewährleistet werden.“
k-Anonymisierung
Unumschränkt nutzen lassen sich Daten nur nach einer Anonymisierung. Allerdings ist eine echte Anonymisierung im Eigenbau unter Wahrung der Privatsphäre schwierig. Sie erfordert Zeit, Ressourcen und umfangreiche Fachkenntnisse. Zudem ergibt sich immer das Problem, zu viel oder zu wenig zu schützen. So kann die Anonymisierung nicht ausreichend sein und die Daten unzureichend schützen. Oder sie kann die Daten so weit ändern, dass sie für eine Vielzahl von Anwendungsfällen kaum noch brauchbar sind. Der Datenschutzforscher Paul Ohm schrieb daher schon 2010: „Daten können entweder nützlich oder perfekt anonymisiert sein - aber niemals beides.“
Etablierte Verfahren zu einer echten Datenanonymisierung gibt es inzwischen einige. Sie wurden auch bereits in Software-Produkten umgesetzt. Eine Standard-Anonymisierungstechnik ist k-Anonymity. Sie wird beispielsweise von Google verwendet. Der k-Anonymity liegt die Idee zugrunde, bestimmte Identifikatoren zu Gruppen mit gleichem Informationsgehalt zusammenzufassen, sodass die hinter den Daten stehenden Individuen nicht mehr unterscheidbar sind und eine Verknüpfung mit damit zusammenhängenden Informationen nicht mehr möglich ist.
Das Verfahren wird gern im Gesundheitswesen eingesetzt. Professor Johann Eder von der Universität Klagenfurt erläutert das Verfahren auf der Technologie- und Methodenplattform für die vernetzte medizinische Forschung TMF so: „,k‘ steht für die Größe der Gruppe. Je höher das ,k‘ ist, desto stärker die Anonymisierung. Zuerst identifizieren wir im Datenbestand die Quasi-Identifier: Das sind all jene Felder, deren Inhalt ein potenzieller Angreifer kennen kann. Typische Kandidaten sind Geburtsdatum, Alter, Beruf, Wohnort, Geburtsort und so weiter. Die Inhalte dieser Felder werden verallgemeinert, indem etwa der Geburtsort durch den Landkreis ersetzt wird, das Alter durch eine Altersgruppe. Die Daten werden so weit verallgemeinert, dass es zu jedem Datensatz ,k-1‘ Datenzwillinge gibt. Wird beispielsweise ,k‘ mit 7 festgelegt, müssen also sieben Datensätze dieselbe Kombination von Werten in den quasi-identifizierenden Feldern haben. Ein Angreifer kann so keinen einzelnen Datensatz identifizieren, sondern nur mehr eine Gruppe von ‚k‘ Datensätzen.“
Um k-anonymisierte Datensätze handelt es sich zum Beispiel bei den Ortsdaten der Telefonkunden, die die Data Anonymization Platform von Telefónica Deutschland Partnern und Kunden zur Verfügung stellt. „Unser Anonymisierungsverfahren zeigt, dass der Schutz von Daten und das Gewinnen interessanter Erkenntnisse keinen Widerspruch darstellen. Wir können Daten je nach Fragestellung sicher und flexibel analysieren und dabei auch verschiedene Datenquellen unter Wahrung der Anonymität einbeziehen“, versichert Jonathan Ukena, Leiter Big Data Privacy Services bei Telefónica.
4. Teil: „Dynamisch anonymisieren“
Dynamisch anonymisieren
k-Anonymity hat in der Praxis allerdings auch einen Nachteil: Je mehr Dimensionen hinzugefügt werden, desto mehr Informationen müssen anonymisiert werden. Dadurch verschlechtern sich die analytischen Möglichkeiten. Moderne Anonymisierungslösungen wie Differential Privacy oder Diffix sind hier etwas besser aufgestellt.
Diffix ist ein Anonymisierungsansatz, der am Max-Planck-Institut für Softwaresysteme zusammen mit dem Start-up Aircloak entwickelt wurde. Diffix versucht nicht, einen ganzen Datensatz am Stück abzusichern, sondern anonymisiert ihn vielmehr dynamisch bei jeder Abfrage der Datenbank. Die Anonymisierung wird damit an die jeweilige Abfrage und die angeforderten Daten angepasst. Anonymisiert werden die Abfrageergebnisse, indem ein sowohl auf den Input als auch auf den zugrunde liegenden Datensatz zugeschnittenes Rauschen hinzugefügt wird. Es gleicht einem vollautomatischen Filter zwischen Datenbank und Analysten und stellt sicher, dass Letztere zwar mit allen Datenpunkten arbeiten können, aber dies nur geschieht, ohne Rückschlüsse auf einzelne Personen zu erlauben.
Datensätze können damit laut Aircloak schnell, einfach und sicher für neue Anwendungsfälle „entsperrt“ werden und trotzdem kann ein hohes Level an Datenschutz gewährleistet werden. Das vollständig anonymisierte Abfrageergebnis falle nicht mehr unter den Datenschutz der DSGVO und könne somit frei geteilt werden, ohne sich Gedanken darüber zu machen, welches zusätzliche Wissen ein Analyst haben könnte. Der Ansatz wird derzeit unter anderem in der Medizin und im Bankwesen eingesetzt - bei der TeamBank etwa, um Transaktionsdaten anonym auszuwerten.
Die Datenanonymisierungs-Lösung auf Diffix-Basis wird von Aircloak für verschiedene Zielgruppen angeboten. „Aircloak hat Forschungsarbeiten des Max-Planck-Instituts für Softwaresysteme weiterentwickelt und so eine hochentwickelte und gleichzeitig einfach zu handhabende Lösung für Kunden geschaffen, die maximale Datensicherheit und Datenschutz gewährleistet”, schwärmt Florian Kirschenhofer, Start-up & Portfolio Manager bei Max-Planck-Innovation, der Technologietransfer-Organisation der Institute der Max-Planck-Gesellschaft.
5. Teil: „Differential Privacy“
Differential Privacy
-
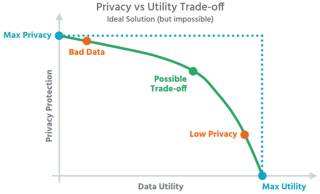
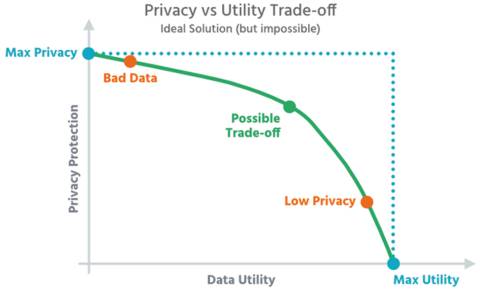
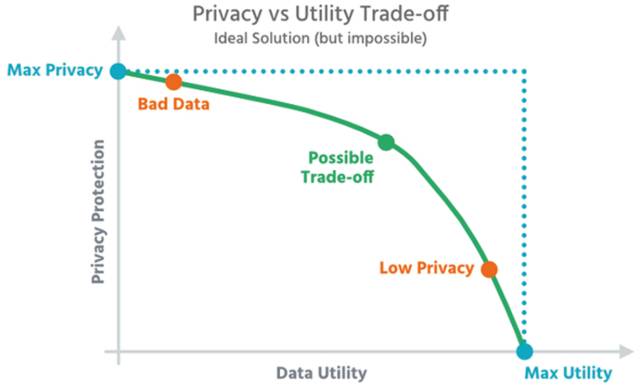 Dilemma: Je höher der Schutz der Daten (Privacy), desto geringer ist die Nutzbarkeit für hochwertige Analysen (Utility) – und umgekehrt.Quelle:Aircloak
Dilemma: Je höher der Schutz der Daten (Privacy), desto geringer ist die Nutzbarkeit für hochwertige Analysen (Utility) – und umgekehrt.Quelle:Aircloak
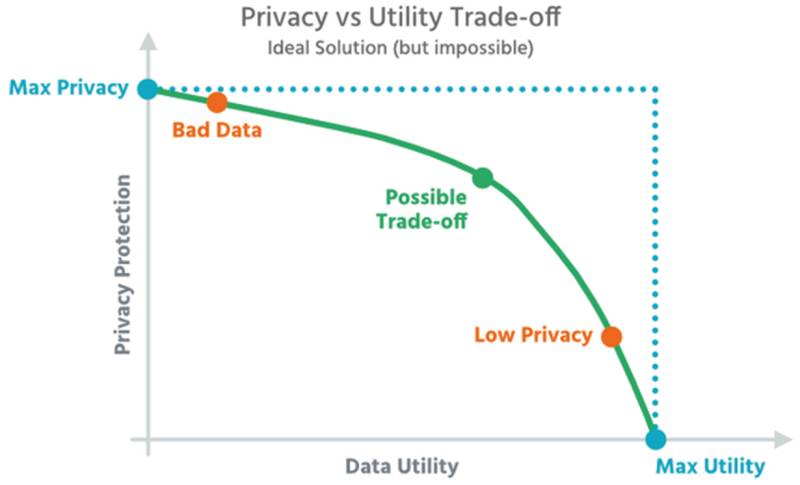
Bei Differential Privacy wird den Daten mathematisches Rauschen - falsche Daten - hinzugefügt. Dabei werden aufgrund eines Algorithmus die Merkmalsausprägungen einzelner Datensätze verändert oder weitere „unechte“ Datensätze hinzugefügt, die in die Auswertung miteinbezogen werden. Ergebnis und Verteilung werden nur geringfügig beeinträchtigt, es ist für den Anwender jedoch nicht mehr nachvollziehbar, welche der untersuchten Datensätze „echt“ sind.
Google erläutert das Verfahren auf der Seite „Wie Google Daten anonymisiert“ so: „Stellen Sie sich zum Beispiel vor, dass wir die Gesamtentwicklung bei den Suchanfragen für Grippe in einer geografischen Region messen. Um Differential Privacy zu erreichen, fügen wir den Daten Rauschen hinzu. Dabei addieren oder subtrahieren wir die Anzahl der Personen, die in einem bestimmten Viertel nach Grippe suchen. Dies wirkt sich jedoch nicht auf die Werte des Trends in der geografischen Region insgesamt aus. Die Aussagekraft von Datensätzen nimmt jedoch durch den Einsatz von Rauschen unter Umständen ab.“
Bekannt geworden ist Differential Privacy vor allem durch die Nutzung bei Apple. Der IT-Konzern bedient sich dieses Verfahrens, um sich aus einem hausgemachten Dilemma zu befreien. Einerseits erklärt sich Apple zum strengen Verfechter des Datenschutzes und Hüter der Privatsphäre seiner Nutzer. Andererseits möchte natürlich auch Apple wie Facebook oder Google von den großen Datenmengen profitieren, die auf den iPhones, iPads und Macs oder in der iCloud täglich anfallen. Mit Differential Privacy könne Apple „das Nutzererlebnis verbessern, indem das Verhalten vieler Anwender analysiert wird“, heißt es in einem Apple-Papier. Seit iOS 10 und Mac OS High Sierra ist Differential Privacy deshalb Bestandteil von Apples Betriebssystemen.
Daten synthetisieren
Ein ganz neuer Ansatz, Daten konsequent zu anonymisieren, ist die Daten-Synthetisierung. Bei dieser Methode wird eine künstliche Repräsentation der zu schützenden Originaldaten generiert, die keinerlei Rückschlüsse mehr auf Personen erlaubt. Ein Machine-Learning-Algorithmus läuft über die Kundendaten, analysiert deren Struktur und lernt durch Training die statistischen Informationen und statistischen Strukturen der Originaldaten. Mit diesem Wissen erzeugt der Algorithmus neue künstliche Daten. Diese spiegeln den gesamten Datensatz mit seinen statistischen Informationen, Strukturen und Echtdaten wider. In einer großen Datenbank-Tabelle würde der Algorithmus etwa die statistische Häufigkeitsverteilung in den einzelnen Spalten und die statistischen Korrelationen zwischen den Spalten analysieren. Sobald das Modell trainiert wurde, erzeugt die Software die synthetischen Daten mit denselben statistischen Eigenschaften. So könnte man wie bei den Originaldaten abfragen, wie hoch der Prozentsatz an männlichen Herzinfarkt-Patienten über 55 mit Übergewicht ist, und zum gleichen Ergebnis kommen.
„Diese Methode ist bereits bei Behörden und Instituten mehrerer Länder im Einsatz und wird dazu benutzt, Mikrodatensätze, also Datensätze mit Daten, die auf Individualebene beobachtet werden, zu anonymisieren“, schreiben Jörg Drechsler und Nicola Jentzsch von der Stiftung Neue Verantwortung (SNV), einer gemeinnützigen Berliner Denkfabrik. In ihrem Papier „Synthetische Daten“ verweisen sie darauf, dass die Daten-Synthetisierung bereits bei Statistikbehörden und Institutionen, aber auch in Unternehmen im Einsatz ist: „In den USA veröffentlicht das U.S. Census Bureau synthetisierte Ströme von Berufspendlern oder Einkommensdaten und Transferleistungen. In Schottland erhalten Forscher, die mit den Daten der Scottish Longitudinal Study arbeiten wollen, synthetische Daten für ihre Analysen. In Deutschland ist das Institut für Arbeitsmarktforschung (IAB) der Vorreiter in der Synthetisierung. Dort wurde das IAB-Betriebspanel für Forschungszwecke synthetisiert.“ In Deutschland hat das Start-up Statice für dieses Verfahren eine Anonymisierungs-Software entwickelt. „Wir wollen den Unternehmen nicht nur ermöglichen, auf interessanten Daten zu arbeiten, sondern gemeinsam mit Partnern aus der Analyse neue Geschäftsmodelle entwickeln, ohne die Privatsphäre ih-rer jeweiligen Kunden zu gefährden“, erklärt Statice-CEO Sebastian Weyer.
6. Teil: „Im Gespräch mit Sebastian Weyer von Statice“
Im Gespräch mit Sebastian Weyer von Statice
-
 Sebastian Weyer: Co-Gründer und CEO des Anonymisierungs-Start-ups StaticeQuelle:Statice
Sebastian Weyer: Co-Gründer und CEO des Anonymisierungs-Start-ups StaticeQuelle:Statice
com! professional: Herr Weyer, warum erlebt das Thema Datenanonymisierung gerade jetzt einen Aufschwung?
Sebastian Weyer: Mit Inkrafttreten DSGVO im Mai 2018 wird für Unternehmen die Nutzung der sensiblen Kundendaten immer komplizierter. Unternehmen müssen heutzutage darauf achten, dass sie personenbezogene Daten nur im Rahmen eines klaren Verarbeitungszwecks bearbeiten dürfen - und das ist nicht immer leicht. Die Anonymisierung dieser Daten gibt ihnen die Möglichkeit, ihre Daten auch für weitere Zwecke ganz legal zu verarbeiten. Wobei Anonymisierung heißt, die Daten so zu verändern, dass es absolut keinen Bezug mehr auf eine echte Person gibt.
com! professional: In welchen Bereichen ist es besonders wichtig, dass die Daten anonymisiert werden?
Weyer: Allgemein sind alle Unternehmen betroffen, die mit Daten von EU-Kunden zu tun haben. Besonders wichtig ist die Datenanonymisierung für Unternehmen, die auf personenbezogene Daten und deren Auswertung angewiesen sind. Dazu gehören beispielsweise Unternehmen im Finanz- oder Gesundheitswesen. Unabdingbar ist die Datenanonymisierung vor allem für Unternehmen, die im Rahmen der Digitalisierung Daten für neue Produktentwicklungen und besseren Kundenservice benötigen. Sie müssen sensible Kundendaten auswerten.
com! professional: Es reicht also nicht, Daten wie Name oder Geburtsdatum zu löschen, um einen Datensatz zu anonymisieren.
Weyer: Ganz genau. Das ist auch leider der Trugschluss, dem viele Unternehmen heutzutage noch unterliegen. Der Gesetzestext unterscheidet ganz klar zwischen Pseudonymisierung und Anonymisierung.
Pseudonymisierung ist das, was Sie gerade beschrieben haben: Man löscht oder verändert den Namen oder andere persönliche Daten. Anonymisierung ist viel stärker: Es heißt wirklich, die garantierte Re-Identifizierung einer echten Person unmöglich zu machen. Der Gesetzestext sagt, dass Daten erst dann als anonym einzustufen sind, wenn es selbst mit signifikantem Rechen- und anderem Aufwand nicht möglich ist, Daten auf Einzelpersonen zurückführen zu können. Das ist auch deshalb wichtig, weil Pseudonymisierung - wie schon häufig bewiesen - nicht sicher ist.
com! professional: Haben Sie dafür ein Beispiel?
Weyer: Vor ungefähr zehn Jahren veröffentlichte Netflix einen sehr großen, schlecht anonymisierten Nutzerdatensatz, damit externe Forscher und Data Scientists damit ihren Kernalgorithmus verbessern konnten. Eine außenstehende Person stellte dann bei Inspektion der Daten fest, dass man sie mit der International Movie Database IMDB verbinden konnte. Basierend auf den Bewertungen von Filmen konnte die Person einen Großteil der Daten auf Einzelpersonen zurückführen. Das ist ein gutes Beispiel dafür, dass Anonymisierung per se leider nicht trivial ist, sondern ein sehr komplexes Unterfangen.
com! professional: Wie wird Anonymisierung sicher?
Weyer: Bei der k-Anonymisierung etwa aggregiert man Datensätze aus gewissen Attributen. Beim Attribut „Geburtsdatum“ heißt das, dass eine Person, die im Jahr 1975 geboren wurde, in diesem neuen Datensatz nur noch als Person erscheint, die zwischen den Jahren 1970 und 1980 geboren ist. Das Problem dabei ist allerdings: Je sicherer man die Daten macht und je besser man sie anonymisiert, umso mehr verlieren sie an Aussagekraft.
com! professional: Wie kann man das besser lösen?
Weyer: Wir haben eine Software entwickelt, die im Kern aus einem generativen Modell besteht, einem Machine-Learning-Algorithmus, der auf einen Datensatz trainiert wird und durch dieses Training die statistischen Informationen und Strukturen der Originaldaten erlernt. Mit diesem Wissen wird ein komplett neuer, „synthetischer Datensatz“ generiert, der keine originalen Einträge mehr hat, sondern aus komplett neuen künstlichen Datenpunkten besteht, die den echten Datensatz mit seinen statistischen Informationen und Strukturen widerspiegeln. So eine Anonymisierung ist erst seit etwa zwei Jahren durch das Aufkommen von Deep-Learning-Frameworks wie TensorFlow umsetzbar.
com! professional: Wie hat man sich das vorzustellen?
Weyer: Die vollständig neu generierten Daten enthalten die sehr detaillierten, granularen und statistisch relevanten Informationen des Originals, ohne dass man mit den echten Daten arbeiten müsste. Die Technologie lässt sich mit den kürzlich in der Presse thematisierten Deep Fakes vergleichen. Bei diesen Deep Fakes generieren Algorithmen Bilder und Videos von Menschen, die aussehen wie echte Menschen, aber keine echten Menschen sind. Die Technologie ist der unseren ähnlich. Nur dass wir anstelle von Bildern statistisch Daten und strukturierte Daten generieren, und sich diese statistisch gesehen an den Echtdaten orientieren. Sie sehen aus wie echte Daten, es sind aber keine echten Daten drin.
com! professional: Wie sieht die Verbindung zum Original-Datensatz aus? Legen Sie Kriterien fest, was anonym bleiben soll?
Weyer: Nein. Das ist genau der Fehler, den man bei der Pseudonymisierung von Daten macht. Hier werden bestimmte Attribute als sensibel und andere als nicht sensibel eingestuft. Das ist keine Anonymisierung. Warum? Wie das Netflix-Beispiel zeigt, gibt es in jedem Datensatz sogenannte Quasi-Identifikatoren, die auf den ersten Blick überhaupt nicht sensibel erscheinen, aber durch Hinzuziehen von anderen Datenquellen Rückschlüsse auf Echtpersonen zulassen können. Wir hingegen machen so eine Unterscheidung zwischen sensiblen und weniger sensiblen Informationen nicht. Wir gehen davon aus, dass jedes einzelne Attribut in einem Datensatz sensibel ist und dementsprechend neu generiert werden muss. Also nehmen wir den gesamten Datensatz und generieren daraus einen komplett neuen Datensatz.
com! professional: Welche unterschiedlichen Anonymisierungsansätze gibt es?
Weyer: Grob kann man zwei Ansätze unterscheiden. Zum einen wird versucht, Daten so aufzubereiten, dass sie möglichst frei genutzt werden können. Zu diesen Data-Release-Lösungen zählt unser Verfahren. Dabei werden komplette Datensätze so anonymisiert, dass man sie bedenkenlos weitergeben kann. Zum anderen gibt es sogenannte Query-Interfaces. Dabei zieht man aus einer bestimmten Datenbank über ein Interface anonym aggregierte Informationen. Das ist zwar praktisch für Use Cases, die etwa Statistiken auslesen oder Dashboards bauen. Die meisten Unternehmen wollen aber Daten komplexer nutzen, gerade für Machine Learning.
com! professional: Welche Branchen fragen Ihren Anonymisierungsdienst besonders stark nach?
Weyer: Wie sind sehr stark im Gesundheits- und Automobilbereich aktiv sowie im Versicherungs- und Finanzwesen. Gerade in diesen Segmenten sind Daten höchst sensibel, und sie haben gleichzeitig auch einen starken Mehrwert für Unternehmen, wenn diese etwa für Produktinnovationen ausgewertet werden.
Roadmap
Estos bringt neue Services und Produkte
Der Software-Hersteller feilt an seinem Partnerprogramm, hat Schlüsselpositionen neu besetzt und kündigt eine ganze Reihe neuer Produkte und Services an. Das ist die Estos-Roadmap bis Ende des Jahres.
>>
Mit KI
Enreach Open Air Partner-Event 2024 in Dortmund
Der Hersteller Enreach lädt Partner am 5. Juni an seinen Firmensitz ein, um mit Ihnen über smarte Sprachassistenten, Conversational AI und weitere Kommunikationslösungen zu diskutieren.
>>
Sponsored Post
Passwörter - versteckte Kostenfalle für Unternehmen?
Passwörter spielen für die Sicherheit vieler Unternehmen eine wichtige Rolle. Allerdings können sie auch einen erheblichen Kostenpunkt darstellen. Von unzähligen Stunden, die Ihr Service Desk mit Passwort-Resets und dem Entsperren von Konten verbringt, bis hin zu den enormen Kosten, die durch Cyberangriffe entstehen - Kurzum: Passwörter kosten Ihrem Unternehmen Geld.
>>
Mainframe
T-Systems gewinnt größten Auftrag in Dänemark
Der dänische IT-Spezialist für den öffentlichen Sektor und moderne Gesellschaften KMD hat T-Systems mit dem Betrieb seiner Mainframe-Infrastruktur beauftragt.
>>