13.11.2018
Datenanalyse-Tools
1. Teil: „Data Science für Nicht-Programmierer“
Data Science für Nicht-Programmierer
Autor: Charles Glimm



Khakimullin Aleksandr / Shutterstock.com
Selfservice-Plattformen sollen selbst anspruchsvolle Big-Data-Analysen bewältigen. Damit steht Data Science auch Unternehmen ohne eigenen Datenwissenschaftlern zur Verfügung.
Data Science – was ist das überhaupt? Der amerikanische Psychologe und Verhaltensökonom Dan Ariely hat einen drastischen Vergleich für den in Mode gekommenen Umgang mit riesigen Datensammlungen gefunden: Big Data sei „wie Teenager-Sex – alle reden drüber, keiner weiß wirklich wie’s geht, aber weil alle denken, die anderen täten es bereits, behauptet jeder, es auch zu tun“.
-
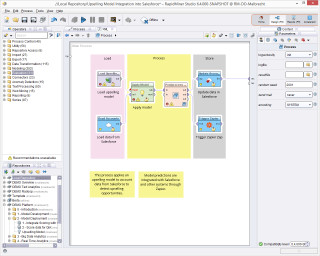
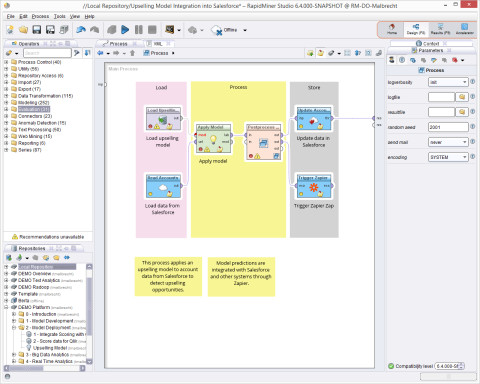
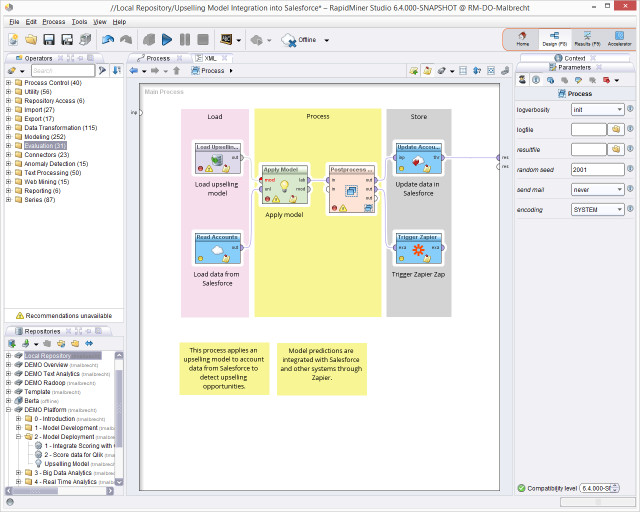 RapidMiner Studio: In der visuellen Design-Umgebung lassen sich vollständige prädiktive Analyse-Workflows per Drag and Drop zusammenstellen.Quelle:RapidMiner
RapidMiner Studio: In der visuellen Design-Umgebung lassen sich vollständige prädiktive Analyse-Workflows per Drag and Drop zusammenstellen.Quelle:RapidMiner
Die zugehörige Berufsbezeichnung lautet Data Scientist, im Deutschen auch Datenwissenschaftler. Dieser Spezialist sollte neben Branchenwissen über Kenntnisse in statistischen Programmiersprachen zum Aufbau von Datenverarbeitungssystemen, Datenbanken und Visualisierungswerkzeugen verfügen. Denn seine Aufgabe ist es, sowohl verwertbare Ergebnisse aus dem zur Verfügung stehenden, oft unstrukturierten Datenmaterial zu extrahieren, als auch die gewonnenen Einsichten für alle Unternehmensebenen verständlich aufzubereiten und zu präsentieren.
Der Weg zur Data Science
Dem Data Scientist helfen Abfrage- und Analyse-Tools, angeführt von diversen Programmiersprachen, die, wie etwa die Open-Source-Sprache R, besonders für statistische Aufgaben und die Ausgabe von Grafiken geeignet sind. Entsprechend sind Codierkenntnisse sowie der Umgang mit Programmier- und Abfragesprachen wie Python, R, C/C++ oder SQL eigentlich ein integraler Bestandteil der Datenwissenschaft. Wer Programmierlogik, Schleifen und Funktionen versteht, hat deutlich höhere Chancen, erfolgreich eine Karriere als Datenwissenschaftler zu durchlaufen.
Der Weg zu einem der begehrten und meist hoch dotierten Jobs in diesem Aufgabenfeld führt in den meisten Fällen über die Universität. Mehrere Hochschulen im deutschsprachigen Raum, etwa München, Stuttgart, Mannheim, Marburg und Darmstadt, bieten gegenwärtig Bachelor- oder Masterstudiengänge im Fach Data Science an. Weitere kommen ständig hinzu. Daneben gibt es aber auch spezialisierte Weiterbildungsangebote sowie berufsbegleitende Studiengänge, die engagierte Datengräber ans Ziel führen.
Auf dem Höhepunkt der digitalen Transformation und dem damit verbundenen Boom der Datenanalyse ist die Nachfrage vonseiten der Unternehmen dennoch höher als das Angebot an ausgebildeten Datenwissenschaftlern. Gleichzeitig sind auch viele Beschäftigte daran interessiert, diese Richtung einzuschlagen, obwohl sie sich mit Codierung nie zuvor beschäftigt haben. Das wirft die Frage auf: Wie stehen die Chancen für Nicht-Programmierer, als Data Scientist erfolgreich tätig zu werden?
2. Teil: „Tools für Nicht-Programmierer“
Tools für Nicht-Programmierer
Der typische Datenwissenschaftler ist wissbegierig und stets auf der Suche nach neuen Werkzeugen, die ihm helfen, seine Kenntnisse zu vertiefen und neue Antworten zu finden. Und es gibt in der Tat Tools, die hier einen möglichen Ausweg oder zumindest einen Einstieg für Lernwillige bieten. Sie klammern den Programmieraspekt weitgehend aus und setzen zur Bedienung auf eine benutzerfreundliche grafische Oberfläche. So kann sie im Grunde jeder mit minimalen Kenntnissen von Algorithmen einsetzen, um Maschinenlernprozesse oder Vorhersagemodelle zu erstellen.
-
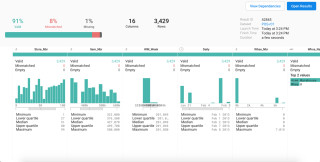
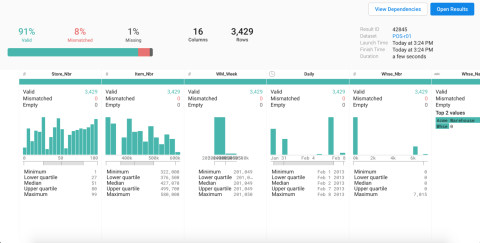
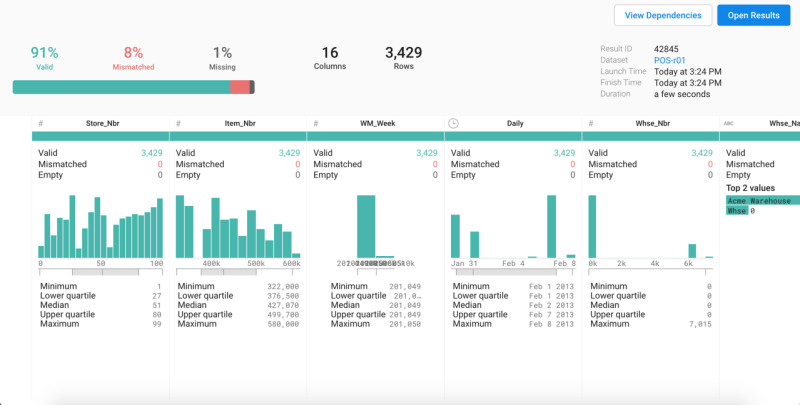
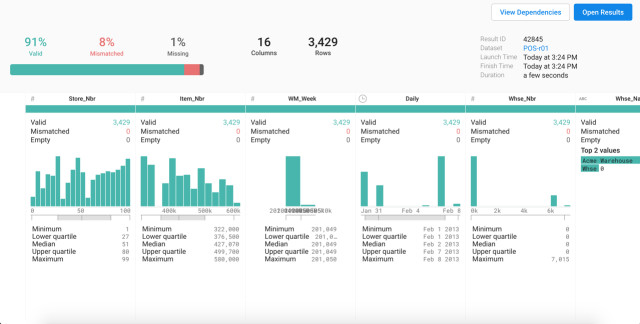 Übersichtlich: Ein Qualitätsbalken und Histogramme bieten bei Trifacta einen schnellen und grundlegenden Überblick über den Datensatz.Quelle:Trifacta
Übersichtlich: Ein Qualitätsbalken und Histogramme bieten bei Trifacta einen schnellen und grundlegenden Überblick über den Datensatz.Quelle:Trifacta
Dazu kommt, dass die gewonnenen Erkenntnisse meist nicht selbsterklärend sind, sie wollen interpretiert werden. Und gerade bei der Auswertung großer, unstrukturierter Datenbestände sind die Zusammenhänge selten eindeutig, Korrelation bedingt nicht zwangsläufig Kausalität. Berühmt-berüchtigt ist das Beispiel mit dem Vogel: In einem nördlichen Bundesland beobachteten Statistiker, dass in Jahren, in denen besonders viele Störche aus dem Süden zurückkehrten, auch die Geburtenrate in der Bevölkerung signifikant anstieg. Daraus zu schließen, dass der Storch die Babys bringt, wäre jedoch abenteuerlich.
Auch weitgehend automatisierte und bedienfreundliche Data-Science-Tools sind also letzten Endes kein Ersatz für einen gut ausgebildeten und findigen Spezialisten, wenn ein Unternehmen im Zuge der digitalen Transformation verstärkt auf Big Data setzt. Was sie leisten können, ist hingegen eine gewisse Demokratisierung der Methodik, indem sie auch unausgebildeten Nutzern einen Zugang zu einfachen Modellen bieten. Und sie können den Einstieg ermöglichen, wenn ein Unternehmen noch vor der Frage steht, ob Data Science in großem Umfang in die Geschäftsprozesse einfließen sollte oder nicht.
Im Folgenden stellt com! professional sechs Lösungen vor, die erfolgreiches Data Mining auch ohne Universitätsabschluss versprechen: RapidMiner, DataRobot, Driverless AI, Alteryx, BigML und Trifacta Wrangler.
3. Teil: „RapidMiner “
RapidMiner
RapidMiner ist eine Data-Science-Plattform, die eine integrierte Umgebung für maschinelles Lernen, Deep Learning, Text- und Data Mining, Business Analytics sowie Predictive Analytics bietet. Dabei sollen sich die einzelnen Produkte RapidMiner Studio, Server, Radoop und Streams sowohl für Business-Anwendungen wie für Ausbildung, Training, Rapid Prototyping oder zur Anwendungsentwicklung eignen.
RapidMiner Studio ist eine visuelle Design-Umgebung zum schnellen Aufbau vollständiger prädiktiver Analyse-Workflows unter einer grafischen Oberfläche. Die Workflows werden als Prozesse bezeichnet und bestehen aus mehreren Operatoren. Jeder Operator führt im Prozess eine einzelne Aufgabe aus, die Ausgabe eines Operators bildet jeweils die Eingabe für den nächsten. Die Engine kann von anderen Programmen aufgerufen oder als API verwendet werden.
-
 Data-Science-Plattform: RapidMiner dient als integrierte Umgebung für maschinelles Lernen, Deep Learning, Data Mining und Predictive Analytics.Quelle:RapidMiner
Data-Science-Plattform: RapidMiner dient als integrierte Umgebung für maschinelles Lernen, Deep Learning, Data Mining und Predictive Analytics.Quelle:RapidMiner
Mit RapidMiner Server lässt sich das Programm auf Unternehmens-Hardware von jedem Gerät ohne Einschränkungen ausführen. Der Server kann verwendet werden, um Analysen zu planen, auszuführen und Echtzeitergebnisse zu erhalten. Er lässt sich in alle Datenquellen integrieren und erlaubt den Einsatz eigener Algorithmen fürs Data Mining. Über interaktive Dashboards kann man auf Informationen zugreifen, sie überwachen und freigeben sowie Aufgaben zuweisen.
RapidMiner Radoop bietet eine Plattform für die Verarbeitung von Big Data, einschließlich Analysen und Vorhersagen. Dazu gehört eine visuelle Schnittstelle für Big-Data-ETL (Extract, Transform, Load), Analysen, Ad-hoc-Reporting, prädiktive Modellierung und Visualisierung.
Mit RapidMiner Streams schließlich lassen sich Verarbeitungsanwendungen ohne Code streamen. So können Streaming-Analysen auf verteilten Apache-Storm-Clustern für das Datenmischen und Modell-Scoring bei Streaming-Daten bereitgestellt werden.
Neben der Möglichkeit, komplexe Workflows über die grafische Bedienoberfläche zu erstellen, unterstützt RapidMiner auch Skripting in mehreren Sprachen. Das System vereinfacht den Datenzugriff und ermöglicht das Laden und die Auswertung aller Arten von Daten, einschließlich Texten, Bildern und Audiotracks.
4. Teil: „DataRobot“
DataRobot
DataRobot will eine maschinelle Lernplattform für Datenwissenschaftler aller Fähigkeitsstufen bieten. Das Ziel ist, präzise Vorhersagemodelle in einem Bruchteil der bisher benötigten Zeit zu erstellen und einzusetzen. Auch hier hat man den kritischen Mangel an Datenwissenschaftlern erkannt und will das Problem adressieren, indem Geschwindigkeit und Wirtschaftlichkeit der Vorhersageanalytik verbessert werden, um Zeit zu sparen.
Die Plattform verwendet daher massiv parallele Verarbeitung, um Modelle in R, Python, Spark MLlib, H2O und anderen Open-Source-Bibliotheken zu trainieren und zu bewerten. Dabei werden Millionen möglicher Kombinationen von Algorithmen, Vorverarbeitungsschritten, Features, Transformationen und Optimierungsparametern durchsucht, um die besten Modelle für die jeweiligen Datasets und Vorhersageziele zu liefern. Der Vorgang ist transparent, sodass der Benutzer die Gültigkeit seiner Ergebnisse verfolgen und überprüfen kann. Darüber hinaus lassen sich eigene Modelle auf der Plattform programmieren, trainieren, testen und vergleichen.
-
 DataRobot: Das System will den Datenwissenschaftler nicht ersetzen, sondern seine Arbeit möglichst umfassend unterstützen und verbessern.Quelle:DataRobot
DataRobot: Das System will den Datenwissenschaftler nicht ersetzen, sondern seine Arbeit möglichst umfassend unterstützen und verbessern.Quelle:DataRobot
Das System kann auf dem Hadoop-Cluster ausgeführt werden und bringt damit eine integrierte maschinelle Lernautomatisierung auf den Hadoop-Stack. Mit Spark für die Verarbeitung großer Datenmengen ist es für Datensicherheit und -management ausgelegt. So sind Machine-Learning-Datenobjekte und -Operationen für Hadoop-Managementprozesse und -Richtlinien sichtbar und stehen unter deren Kontrolle.
DataRobot findet auch wichtige Treiber in Geschäftsmetriken, identifiziert Schlüsselwörter und Phrasen in unstrukturiertem Text und kann grundlegende Visualisierungen seiner Ergebnisse ausgeben.
Wichtig ist, dass das System bei all dem nicht dazu gedacht oder geeignet ist, den Datenwissenschaftler zu ersetzen, sondern seine Arbeit vielmehr zu unterstützen und zu verbessern. DataRobot-Anwender brauchen daher zumindest ein grundlegendes Verständnis von Data-Science-Methoden und Business-Intelligence-Tools wie Tableau oder Excel.
5. Teil: „Driverless AI“
Driverless AI
Driverless AI von H2O.ai soll die Schwelle beim Einsatz von Data Science im Unternehmenskontext senken. Die Automatisierungsplattform unterstützt nichttechnische Mitarbeiter bei der Aufbereitung der Daten, der Kalibrierung der Parameter und dem Finden optimaler Algorithmen zur Lösung spezifischer Probleme mit maschinellem Lernen.
-
Driverless AI: Eine hohe Automatisierungsrate soll Data Science auch für nichttechnisch orientierte Anwender verfügbar und nutzbar machen. Quelle:h2o.ai
Trotz einer Reihe von eingebauten Use-Cases, die Benutzer an ihre eigenen Bedürfnisse anpassen können, löst das Tool allerdings nicht jedes Lernproblem automatisch. Es zielt vielmehr darauf ab, genügend Standardmodelle zu finden und einzustellen, um zumindest einen möglichst großen Teil der Abläufe zu automatisieren. So sollen auch Benutzer ohne fachspezifisches Know-how in die Lage versetzt werden, mit der Komplexität von Big Data umzugehen.
Dazu unterstützt das System GPU-Beschleunigung, XGBoost, Multi-GPUs, K-Means, GLM und weitere Verfahren, um eine bessere Leistung zu erzielen. AlphaGo für AI erhöht die Genauigkeit durch automatisches Feature-Engineering, während automatisches maschinelles Lernen dabei hilft, die richtigen Modelle zu finden und anzupassen, um den unterschiedlichen Geschäftsanforderungen gerecht zu werden.
Insgesamt zielt Driverless AI also – im Gegensatz etwa zu DataRobot – darauf ab, Data Science und KI für Unternehmen nutzbar zu machen, ohne dass diese über ausgewiesene Datenwissenschaftler verfügen müssen, indem es nichttechnischen Benutzern erlaubt, mit leistungsstarker Technologie zu experimentieren.
6. Teil: „Alteryx“
Alteryx
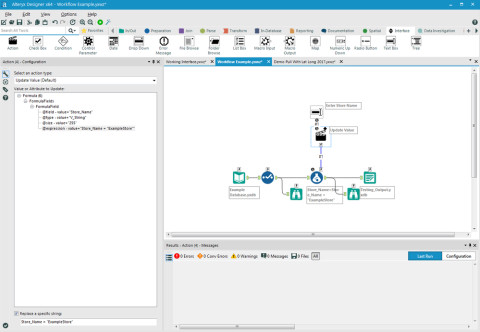
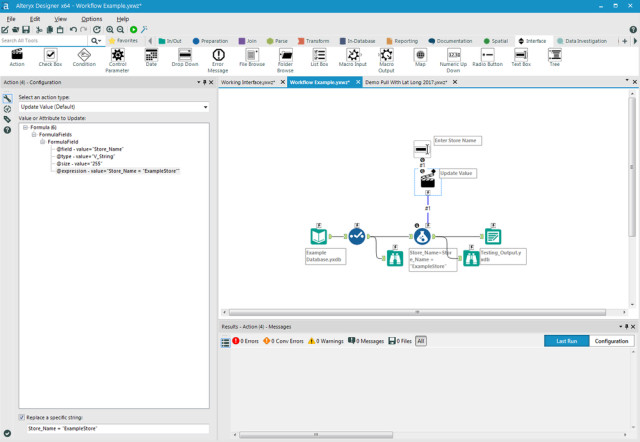
Alteryx ist zugeschnitten auf die Bedürfnisse von Business-Analysten, die eine Selfservice-Lösung suchen. Die Plattform besteht aus drei Komponenten namens Galerie, Designer und Server, die jeweils auch separat verwendet werden können. Sie ist sowohl vor Ort als auch in der Cloud verfügbar. Abgedeckt werden vor allem Data Blending, Predictive Analytics, Geoanalysen und Sharing Insights
Das System strukturiert und bewertet Input aus verschiedenen externen Quellen und ist besonders darauf ausgelegt, die Daten in sich wiederholende Arbeitsabläufe zu überführen, zu mischen und zu umfassenden Erkenntnissen zusammenzufassen. Eine Reihe R-basierter Vorhersagewerkzeuge erstellt Berichte. Hadoop-Abfragen können in jede Datenquelle integriert werden, die später verwendet werden soll.
-
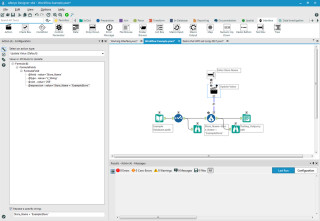
 Alteryx: Die Plattform wendet sich an Business-Analysten, die eine Selfservice-Lösung suchen und wenig Zeit für die Einarbeitung aufwenden wollen.Quelle:Alteryx
Alteryx: Die Plattform wendet sich an Business-Analysten, die eine Selfservice-Lösung suchen und wenig Zeit für die Einarbeitung aufwenden wollen.Quelle:Alteryx
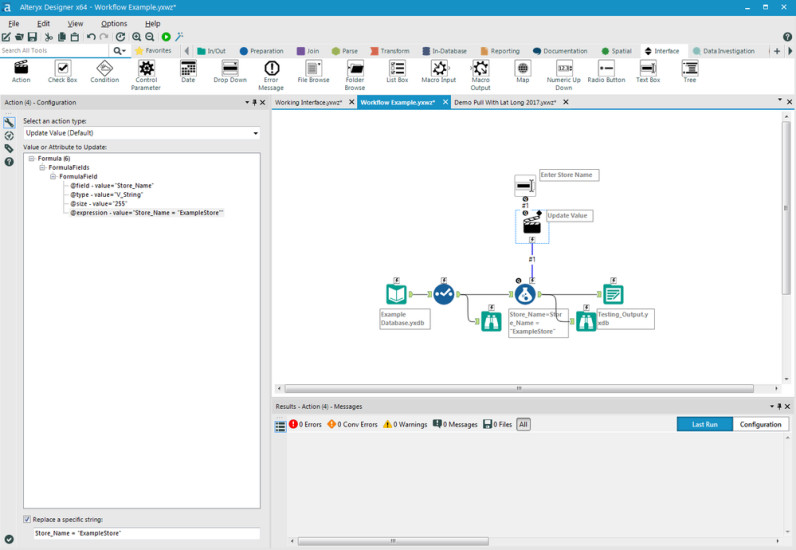
Auch auf Analyseebene verfügt Alteryx über komfortable Tools, um Infos aus allen Kanälen und Systemen zusammenzuführen. Sie ermöglichen etwa einen einfachen Zugriff auf Big-Data- und Kundenanalysen, Darüber hinaus gibt es eine Customer-Churn-Analytics-Funktion, die alle Kundendaten kombiniert und Vorhersagen über die Wahrscheinlichkeit von Abwanderungen oder Ausfallraten ermöglicht.
Alteryx arbeitet auch mit Salesforce zusammen und ergänzt die dortigen Informationen zum Kundenbeziehungsmanagement um umfangreiche Daten wie demografische Merkmale, geografische Daten und Segmentierung.
7. Teil: „BigML“
BigML
BigML ist eine pragmatische und dank grafischer Oberfläche einfach zu bedienende Plattform zum Erstellen leistungsfähiger Vorhersagemodelle. Die cloudbasierte Machine-Learning-Plattform kombiniert überwachtes und unüberwachtes Lernen, Anomalie-Erkennung, Datenvisualisierungs-Tools und Mechanismen zur Datenanalyse. Resultierende Vorhersagemodelle können in verschiedenen Formaten und Sprachen exportiert werden und lassen sich über eine REST-API einfach in Produktionsanwendungen einbinden. Die Zielgruppe sind mittlere und große Unternehmen, die die Vorteile des maschinellen Lernens ohne große Vorlaufkosten oder Implementierungsverzögerungen ausprobieren beziehungsweise nutzen möchten.
-
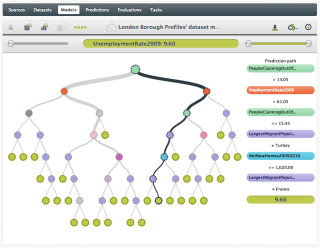
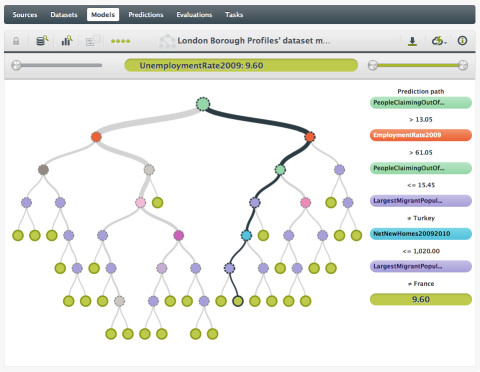
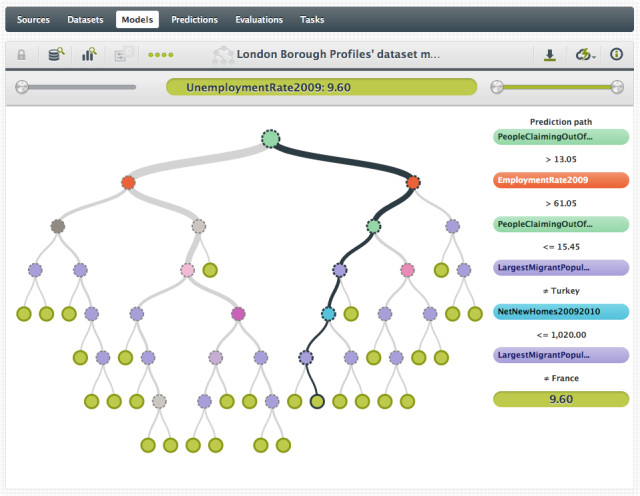 BigML: Dank ihrer grafischen Bedienoberfläche ist die Plattform einfach zu bedienen.Quelle:BigML
BigML: Dank ihrer grafischen Bedienoberfläche ist die Plattform einfach zu bedienen.Quelle:BigML
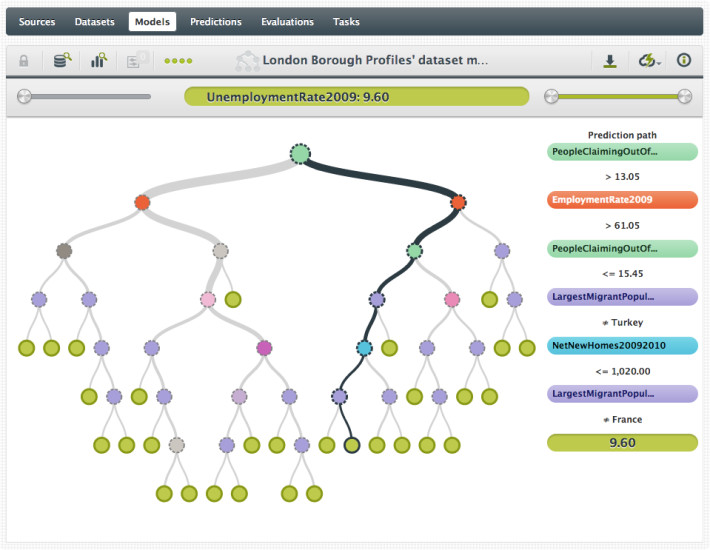
Als cloudbasiertes System wird BigML über den Browser bedient. Daten können über mehrere Mechanismen geladen werden, auch per Direktzugriff auf Cloud-Dienste wie Amazon S3. Für Bereinigung, Normalisierung, Transformation und Feature-Engineering stehen zahlreiche Tools zur Datenvorbereitung zur Verfügung. Dabei erkennt und formatiert BigML Daten automatisch nach ihrem Typ. Zu einzelnen Attributen werden jeweils Metadaten angezeigt. Nützlich ist auch ein integriertes Verteilungsdiagramm.
Das unüberwachte Lernen basiert auf Clusterbildung und wird eingesetzt bei der Kundensegmentierung, Betrugserkennung, Objektverifizierung und etlichen anderen Anwendungen. Die überwachten Lernalgorithmen verwenden CART-Tree-ähnliche Klassifizierer und Entscheidungsbäume. Typische Anwendungen hierfür sind beispielsweise Credit Scoring, Churn Prevention und Predictive Maintenance. Die Anomalie-Erkennung isoliert und bewertet Anomalien und kann zur Verhaltensauthentifizierung, zur Datenbereinigung, für Intrusion Detection oder auch Videoüberwachung verwendet werden.
In der Benutzerumgebung lassen sich per Drag and Drop interaktive Grafiken erzeugen, anhand derer Daten und Modelldetails genauer untersucht werden können. Zur Modellauswertung dienen Splits in Trainings- und Testdaten sowie eine Konfusionsmatrix-Identifikation von Falschpositiven und Negativen. Die entstandenen Modelle können in Java, Python, Node.js und Ruby sowie ins Tableau- oder Excel-Format exportiert werden.
8. Teil: „Trifacta Wrangler“
Trifacta Wrangler
Trifacta Wrangler ist ein cloudbasiertes Datenaufbereitungs-Tool, dessen Hauptzweck darin besteht, die Daten für die Analyse mit anderen Tools in Form zu bringen. Zu den wichtigsten Funktionen der Software gehören deshalb die Strukturierung, Anreicherung, Bereinigung und Validierung von Daten.
Eine kostenlose Wrangler-Version, die von der Betreiber-Website heruntergeladen werden kann, erlaubt es, bis zu 100 MByte große Dateien zu bearbeiten. Die kostenpflichtige Variante bietet mehr Leistung, Zugriff auf zusätzliche Datenquellen wie Hadoop und Amazon S3 sowie erweiterte Funktionen, zum Beispiel Stichproben.
-
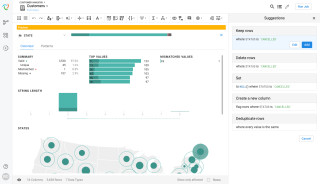
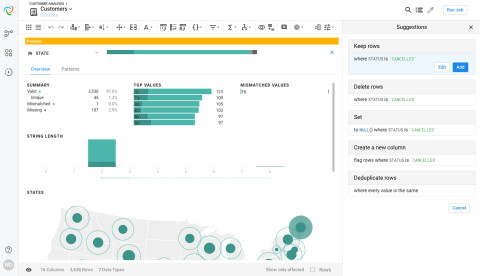
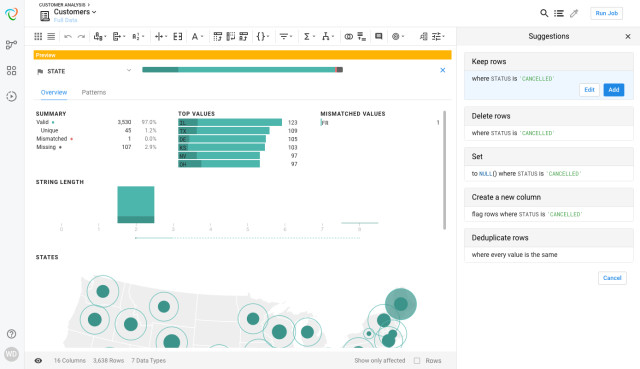 Trifacta: Der Wrangler ist ein cloudbasiertes Datenaufbereitungs-Tool, mit dem sich Daten für die Analyse mit anderen Tools vorbereiten und strukturieren lassen.Quelle:Trifacta
Trifacta: Der Wrangler ist ein cloudbasiertes Datenaufbereitungs-Tool, mit dem sich Daten für die Analyse mit anderen Tools vorbereiten und strukturieren lassen.Quelle:Trifacta
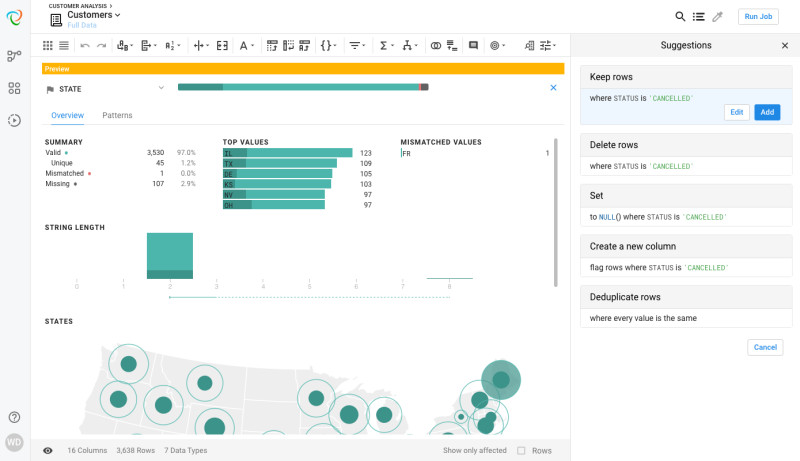
Trifacta bietet native Unterstützung für komplexere Datenformate wie JSON, Avro, ORC oder Parquet und nutzt die Multi-Workload-Fähigkeiten von Hadoop zur Skalierung der Datentransformation. Visual Data Profiling ermöglicht einen sofortigen Einblick in einzelne Elemente des Datensatzes wie Datenverteilung und Ausreißer, um Transformation und Analyse zu unterstützen.
Die Datenanreicherungsfunktionen erleichtern die Standardisierung von Daten, die Verknüpfung von Datensätzen und die Aggregation von Datenausgaben auf die richtige Ebene. Erweiterte visuelle Datenprofilierungsfunktionen verschaffen dem Benutzer ein besseres Verständnis der Eigenschaften eines Datensatzes.
Die Bedienung erfolgt im Wesentlichen per Mausklick oder Drag and Drop. Für jede Aktion des Benutzers generiert Trifacta eine Codezeile. Das so entstandene Skript lässt sich dann auch aufrufen und direkt im Editor optimieren. Über dessen eigene Wrangle-Skriptsprache lassen sich außerdem weitere Funktionen ausführen, die keine GUI-Entsprechung haben.
Die Software erledigt Transformationen wie das Ändern von Spaltendatentypen, das Filtern nach verschiedenen Kriterien, das Aufteilen von Spalten, das Verbinden und Aggregieren mehrerer Datenquellen sowie das Neuordnen von Spalten.
Eine Farbkodierung zeigt im Transformationseditor die Datenqualität an – Grün gibt den Anteil der Zeilen wieder, die Einträge des richtigen Typs enthalten, andere Farben verweisen auf fehlende oder inkorrekte Datensätze. Über jeder Spalte sorgt außerdem ein Histogramm für eine grundlegende Vorstellung von der Datenverteilung.
Qualitätsbalken und Histogramm bieten einen schnellen und grundlegenden Überblick über einen Datensatz, während die Spaltendetailansicht statistische Werte wie Median, Durchschnitt, Standardabweichung, untere und obere Quartile sowie Minimal- und Maximalwerte vermittelt.
Dank der grafischen Bedienoberfläche gestaltet sich die Arbeit mit Trifacta einfacher, als wenn man eigene Skripts von Grund auf neu schreiben müsste. Andererseits ist man dafür natürlich weniger flexibel als bei Nutzung einer Sprache wie R. Die Grenzen der gewöhnlichen Mausschnittstelle lassen sich überwinden, indem man Trifactas Wrangle-Sprache verwendet, allerdings muss der Benutzer einiges an Zeit investieren, um sich in die Skriptsprache einzuarbeiten.
Glasfasernetz
GlobalConnect stellt B2C-Geschäft in Deutschland ein
Der Glasfaseranbieter GlobalConnect will sich in Deutschland künftig auf das B2B- und das Carrier-Geschäft konzentrieren und stoppt die Gewinnung von Privatkunden mit Internet- und Telefonanschlüssen.
>>
Pilot-Features
Google Maps-Funktionen für nachhaltigeres Reisen
Google schafft zusätzliche Möglichkeiten, um umweltfreundlichere Fortbewegungsmittel zu fördern. Künftig werden auf Google Maps verstärkt ÖV- und Fußwege vorgeschlagen, wenn diese zeitlich vergleichbar mit einer Autofahrt sind.
>>
Codeerzeugung per KI
Code ist sich viel ähnlicher als erwartet
Eine Studie zeigt, dass einzelne Codezeilen zu 98,3 Prozent redundant sind, was darauf hindeutet, dass Programmiersprachen eine einfache Grammatik haben. Die Machbarkeit von KI-erzeugtem Code war also zu erwarten.
>>
JavaScript Framework
Hono werkelt im Hintergrund
Das JavaScript-Framework Hono ist klein und schnell. Ein weiterer Vorteil ist, dass Hono auf vielen Laufzeitumgebungen zum Einsatz kommen kann.
>>