18.07.2018
Datenbanken aus der Cloud
1. Teil: „Apps und Analysen beschleunigen mit NoSQL“
Apps und Analysen beschleunigen mit NoSQL
Autor: Thomas Hafen



wan wei / shutterstock.com
Nicht relationale Systeme ergänzen und ersetzen SQL-Datenbanken und Data Warehouses. Welche Art NoSQL-Datenbank genutzt wird, hängt jedoch vom jeweiligem Anwendungsfall ab.
-


 Quelle: Allied Market Research
Quelle: Allied Market Research

Streaming-Plattformen, vernetzte Maschinen und Geräte, Webshops und Online-Plattformen produzieren riesige Mengen an Daten, die teils in Echtzeit gespeichert und analysiert werden sollen. „Traditionelle Datenbanken sind an einem Punkt angelangt, an dem sie nicht mehr mithalten können“, erklärt Giscard Venn, Digital Explorer beim Datenbankspezialisten DataStax. Viele Anwender suchen daher nach Alternativen, die ohne starres Datenschema auskommen, aber dennoch schnelles Speichern, Durchsuchen und Analysieren ermöglichen. Solche schemafreien Systeme werden als „NoSQL“ bezeichnet. Da sie heute oft auch SQL-Abfragen verarbeiten, wird das „No“ meist als „not only“ gelesen.
Flexibler verarbeiten
NoSQL-Datenbanken können strukturierte, unstrukturierte und semi-strukturierte Daten in unterschiedlichen Formaten miteinander verknüpfen und zueinander in Beziehung setzen. „Die Technologie wird branchenübergreifend eingesetzt und bietet die notwendige Agilität, um große Datenmengen zu integrieren, zu speichern, zu durchsuchen und sinnvoll miteinander zu verknüpfen“, erläutert Stefano Marmonti, DACH Sales Director beim NoSQL-Datenbankanbieter MarkLogic.
Anders als SQL steht NoSQL allerdings nicht für einen bestimmten Typ von Datenbankschema. Das Angebot reicht von Key-Value-Stores, die einfache Schlüssel-Wert-Paare erzeugen, bis zu Varianten, die komplexe Datenbeziehungen in Form von Graphen speichern. „Welche Art NoSQL-Datenbank genutzt wird, hängt vom Anwendungsfall ab“, erklärt Jürgen Wirtgen, Data Platform Lead bei Microsoft.
Key-Value etwa sei besonders geeignet, um Daten schnell und einfach zu speichern und zu lesen, zum Beispiel Sensorinformationen. „Wenn man jedoch, wie in klassischen relationalen Systemen, mehrere Daten gleichzeitig verändern möchte, bringt der Key-Value-Ansatz Nachteile mit sich.“
Sogenannte Wide-Column-Stores wiederum werden laut Wirtgen vor allem für Big-Data-Analysen genutzt, bei denen relationale Daten schnell gespeichert und ausgewertet werden müssen. Und in Document-Stores werden die Daten als Dokumente in Formaten wie XML oder JSON gespeichert. „Die Strukturen sind variabel, aber gleichzeitig schnell auswertbar“, betont Wirtgen. Graphenorientierte Datenbanken schließlich verarbeiten Daten in Form von Netzwerken, erklärt der Microsoft-Experte: „Das heißt, Objekte und deren Relationen untereinander werden gespeichert.“
2. Teil: „Großes Wachstum, geringer Anteil“
Großes Wachstum, geringer Anteil
-
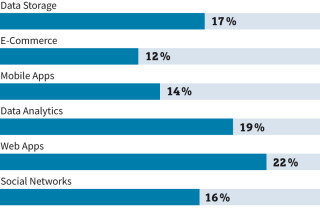
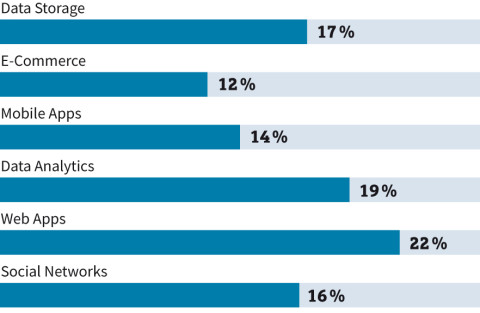
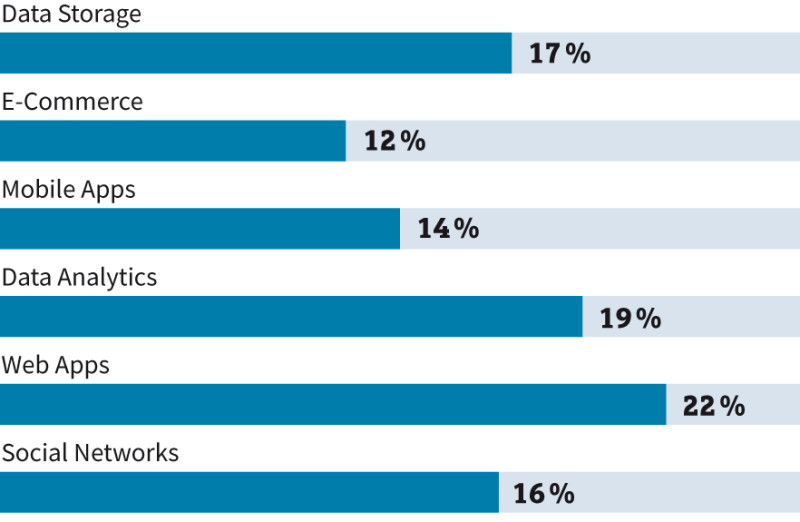
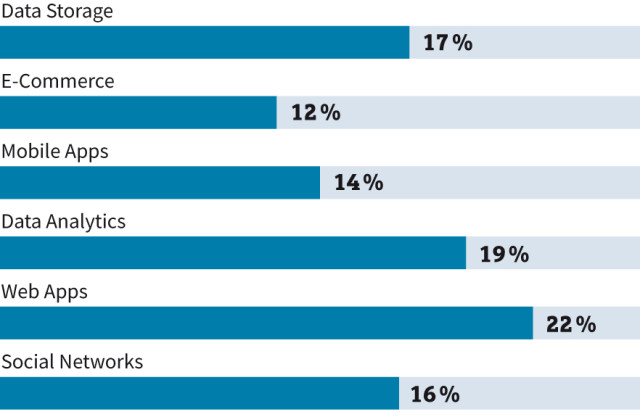 NoSQL-Aufschwung: Weltweit treiben Web-Applikationen und Analytik die Nachfrage nach NoSQL-Datenbanken.Quelle:Allied Market Research
NoSQL-Aufschwung: Weltweit treiben Web-Applikationen und Analytik die Nachfrage nach NoSQL-Datenbanken.Quelle:Allied Market Research
Diese Vorteile werden mittlerweile auch von den Unternehmen wahrgenommen, wie Marmonti beobachtet: „Vor allem bei Gesprächen mit Neukunden und Interessenten fällt uns auf, dass weniger danach gefragt wird, was NoSQL überhaupt ist – das scheint in den Unternehmen weitgehend angekommen zu sein.“
Analysten bestätigen diesen Trend. Laut Allied Market Research wächst die Nachfrage nach NoSQL-Lösungen derzeit mit durchschnittlich 35 Prozent pro Jahr und soll bis 2020 weltweit ein Marktvolumen von 4,2 Milliarden Dollar erreichen.
Auch wenn NoSQL vor allem für neue Projekte verwendet wird, gibt es doch auch immer mehr Firmen, die relationale Datenbanken durch NoSQL ersetzen. „Vor fünf Jahren waren noch rund 5 Prozent unserer Projekte Migrationen von relationalen Systemen, heute sind es 30“, bilanziert Roman Gruhn, Senior Director, Strategic Field Programmes beim NoSQL-Datenbankspezialisten MongoDB.
Diese Zahlen dürfen aber nicht darüber hinwegtäuschen, dass der Anteil von NoSQL am gesamten Datenbankmarkt noch vergleichsweise klein ist. Laut den Analysten von Gartner liegt dessen Volumen weltweit bei über 36 Milliarden Dollar, die Marktforscher von IDC gehen sogar von über 50 Milliarden Dollar aus. Der Vorsprung der traditionellen SQL-Systeme wird sich wohl nur langsam verringern. Gartner rechnet damit, dass bis 2020 immer noch rund 70 Prozent aller neuen Applikationen und Datenbankprojekte auf relationalen Technologien basieren werden.
3. Teil: „Ideales Paar: Cloud und NoSQL“
Ideales Paar: Cloud und NoSQL
Wie in vielen IT-Bereichen wird die Cloud als Bereitstellungsmodell auch für Datenbanken immer wichtiger. NoSQL-Systeme bieten dafür optimale Voraussetzungen, denn sie lassen sich sehr einfach skalieren. Auch viele der Daten, die typischerweise in NoSQL-Systemen verarbeitet werden, sind bereits in der Cloud, etwa Sensormessungen, E-Commerce-Transaktionen oder Social-Media-Informationen.
Schon die Nutzung der Cloud als Platform as a Service (PaaS) für Datenbankanwendungen bringt Vorteile hinsichtlich Flexibilität, weltweiter Verfügbarkeit und Skalierbarkeit. Einen Schritt weiter gehen „Database as a Service“-Angebote – voll gemanagte Datenbankdienste aus der Cloud.
„Unternehmen müssen sich nicht länger Gedanken über das Datenbankmanagment, Software-Patches, Sicherheit, Monitoring, Backups oder Aufbau und Betrieb komplexer verteilter Datenbanksysteme machen“, betont Roman Gruhn vom Unternehmen MongoDB, das mit MongoDB Atlas einen solchen Dienst anbietet. Die Nachfrage zeige, wie beliebt das Konzept sei: „Unsere Umsätze mit Atlas wachsen jährlich um 500 Prozent“, so Gruhn.
„Unternehmen müssen sich nicht länger Gedanken über das Datenbankmanagment, Software-Patches, Sicherheit, Monitoring, Backups oder Aufbau und Betrieb komplexer verteilter Datenbanksysteme machen“, betont Roman Gruhn vom Unternehmen MongoDB, das mit MongoDB Atlas einen solchen Dienst anbietet. Die Nachfrage zeige, wie beliebt das Konzept sei: „Unsere Umsätze mit Atlas wachsen jährlich um 500 Prozent“, so Gruhn.
Neben Datenbankdiensten wie Atlas, die auf unterschiedlichen Infrastrukturen betrieben werden können, gibt es auch Provider-eigene Angebote. Zu diesen cloudspezifischen Lösungen gehört Amazon DynamoDB. Der Dienst ist vollständig verwaltet und unterstützt sowohl Key-Value-Stores wie auch dokumentenbasierte Datenmodelle. Der Anwender legt nur eine Tabelle an und definiert, in welchem Umfang das System skalieren soll. Einrichtung und Konfiguration erfolgen automatisch. Über die Cache-Funktion DynamoDB Accelerator (DAX) lassen sich die Antwortzeiten laut Anbieter von Milli- auf Mikrosekunden beschleunigen.
DynamoDB kann vom Serverless-Computing-Dienst Lambda aus getriggert werden. Daten, die gerade nicht für Abfragen verwendet werden (Data at Rest) lassen sich automatisiert über den AWS Key Management Service (KMS) verschlüsseln. Ver- und Entschlüsselung erfolgen transparent, an der Applikation sind keine Änderungen notwendig. Die Verschlüsselung lässt sich allerdings nur für neue Tabellen einschalten, nicht für bereits bestehende. Auch eine nachträgliche Deaktivierung ist nicht möglich. DynamoDB unterstützt sowohl abgeschwächte (Eventual Consistency) als auch starke Konsistenz (Strong Consistency).
Auch Microsoft bietet in der Azure Cloud mit Cosmos DB eine NoSQL-Lösung an. Der Service unterstützt Key-Value-, dokumentenorientierte, graphenbasierte und Wide-Column-Datenbankmodelle und bietet fünf Konsistenzoptionen. Die Latenz der weltweit verteilten Datenbank beträgt laut Anbieter in der Regel weniger als 10 ms für Lese- und 15 ms für indizierte Schreibvorgänge. „Unsere Datenbanken wurden von Anfang an für eine globale Verteilung und horizontale Skalierbarkeit konzipiert“, sagt Data Platform Lead Wirtgen.
Google hat gleich zwei NoSQL-Services im Angebot: Cloud Bigtable ist vor allem für das Big-Data-Umfeld konzipiert und lässt sich über die HBase-API leicht mit Hadoop oder Spark verbinden. Der vollständig verwaltete Service soll mehrere Hundert Petabyte und mehrere Millionen Vorgänge pro Sekunde verarbeiten. Die Daten werden während der Übertragung (Data in Motion) und der Speicherung (Data at Rest) verschlüsselt.
Cloud Datastore ist ein vollständig von Google verwalteter dokumentenorientierter Service, der sich vor allem für mobile Apps und Web-Applikationen eignet. Diese können unter anderem über eine JSON-API auf die Daten zugreifen. Der Dienst bietet ein Abfragemodul, über das sich Inhalte suchen und sortieren lassen, und unterstützt ACID-Transaktionen. ACID steht für eine besonders verlässliche Datenspeicherung. Neben dem erwähnten MongoDB Atlas gibt es eine Reihe NoSQL-Systeme, die als verwalteter Service auf verschiedenen Cloud-Plattformen zur Verfügung stehen. „Wir beobachten speziell in den letzten zwölf Monaten eine verstärkte Nachfrage nach cloudneutralen NoSQL-Datenbank-Lösungen“, sagt Stefano Marmonti von MarkLogic.
Auf der Open-Source-Datenbank Apache Cassandra setzt beispielsweise DataStax Enterprise (DSE) auf. Es bildet eine gemanagte Datenschicht mit Graph-, Such- und Analysefunktionen. Diese lässt sich in hybriden Umgebungen betreiben und über APIs oder Microservices steuern. „Als moderne Datenbankplattform bietet DSE sämtliche Pluspunkte von Apache Cassandra ohne die damit verbundenen Komplexitäten und ermöglicht so eine unternehmensweite, bedarfsgesteuerte Implementierung mit hoher Nutzerakzeptanz“, sagt Giscard Venn.
Aus dem Apache-Umfeld kommt auch die MapR Converged Data Platform. Neben der Datenbank, die dokumentenorientierte wie auch Wide-Column-Modelle unterstützt, bietet sie Analyse-Tools wie Apache Drill und Apache Spark. MapR lässt sich ebenfalls in hybriden Umgebungen betreiben.
MarkLogic will mit seiner NoSQL-Datenbank vor allem eine Basis für Integrationsprojekte liefern und empfiehlt sich für unternehmenskritische Anwendungen. Die Lösung ist ACID-kompatibel und verwaltet verschiedene Datenmodelle und -arten gemeinsam in einer Datenbank. Besonderen Wert legt der Hersteller auf Sicherheit. „Kunden entscheiden sich für Datenbank-Plattformen mit zertifizierten, granularen Sicherheitsfunktionen, die auch als cloudbasierte Lösung ein Höchstmaß an Sicherheit bieten“, weiß Sales Director Marmonti.
Der Zugriff auf Dokumente und deren Bearbeitung wird rollenbasiert gesteuert, Schlüssel für die Ver- und Entschlüsselung lassen sich in externen Key-Management-Systemen (KMS) speichern, sensible Daten wie Kreditkartennummern lassen sich regelbasiert vom Export ausnehmen.
Fazit & Ausblick
NoSQL-Datenbanken bieten hauptsächlich dort Vorteile, wo unterschiedliche Datenformate, schnell wechselnde Anforderungen an Datenmodell und Leistung sowie große Mengen an Daten anfallen, die schnell verarbeitet und analysiert werden müssen. Da sie sehr leicht über zusätzliche Server oder Rechenknoten skaliert werden können, sind sie besonders gut für die Nutzung in der Cloud geeignet. Die vollständig verwalteten Datenbankdienste der Provider und anderer Anbieter tun ihr Übriges, um die Einstiegshürden zu senken.
Noch herrschen in vielen Firmen Vorurteile gegen den Einsatz bei unternehmenskritischen Anwendungen oder großen Analyseaufgaben im Business-Intelligence-Umfeld. Immer mehr NoSQL-Lösungen genügen jedoch höchsten Sicherheitsanforderungen. Sie lassen sich zudem in hybriden Umgebungen installieren und erlauben so eine nahtlose Migration zwischen den Ressourcen im eigenen Rechenzentrum und Cloud-Instanzen.
4. Teil: „Im Gespräch mit Prof. Dr. Carsten Kleiner von der Hochschule Hannover, Fakultät IV, Abt. Informatik“
Im Gespräch mit Prof. Dr. Carsten Kleiner von der Hochschule Hannover, Fakultät IV, Abt. Informatik
Professor Carsten Kleiner lehrt an der Hochschule Hannover unter anderem über Datenstrukturen und Datenbanksysteme. Im Interview mit com! professional erklärt er, welche Vorteile NoSQL-Datenbanken haben und was man bei der Wahl einer cloudbasierten NoSQL-Lösung beachten sollte.
com! professional: Herr Professor Kleiner, welche Rolle spielen NoSQL-Datenbanken im Studium Ihrer Studenten?
Carsten Kleiner: In unserem Bachelor-Studiengang „Angewandte Informatik“ können wir das Thema nur am Rande bearbeiten, weil die Studenten zunächst einmal relationale Datenbanksysteme verstehen
müssen, um eine Grundlage zu haben. Es gibt aber einen Vertiefungskurs Datenbanksysteme, in dem wir auch nicht relationale Systeme in Ansätzen behandeln. Im Master-Studiengang biete ich die Veranstaltung „Datenbankparadigmen“ an, in der ich auch ausführlich auf NoSQL-Ansätze eingehe.
-


 Prof. Dr. Carsten Kleiner: Hochschule Hannover, Fakultät IV, Abt. InformatikQuelle:Carsten Kleiner
Prof. Dr. Carsten Kleiner: Hochschule Hannover, Fakultät IV, Abt. InformatikQuelle:Carsten Kleiner

com! professional: Und in Ihren Forschungsprojekten?
Kleiner: Unsere Forschung ist sehr angewandt, wir kooperieren eng mit Unternehmen. Da steht das Thema NoSQL noch nicht so sehr im Fokus.
com! professional: Kann man daraus schließen, dass Unternehmen bei der Nutzung von NoSQL-Datenbanken zögern?
Kleiner: Diese Frage lässt sich nicht allgemein beantworten. NoSQL-Datenbanken stellen insgesamt ein so heterogenes Feld dar, dass Aussagen meist nicht für alle Systeme gleichermaßen gelten. Viele Firmen sind aber auf jeden Fall noch in der Experimentierphase.
com! professional: Welche Unternehmen setzen NoSQL schon produktiv ein?
Kleiner: Das sind eher junge, internetaffine Firmen und weniger traditionelle Unternehmen wie Finanzdienstleister, die bereits große relationale Datenbanken – oder womöglich sogar noch ältere Systeme – betreiben. Sie experimentieren zwar auch mit den NoSQL-Alternativen, ein Umzug ihrer Produktivsysteme auf NoSQL ergäbe aber schon aus rein wirtschaftlicher Sicht aktuell keinen Sinn.
com! professional: Wo liegen die typischen Einsatzgebiete für NoSQL-Datenbanken?
Kleiner: Überall wo Geräte sehr viele, eher einfache Daten generieren, die zentral koordiniert werden müssen, etwa im Bereich Smart Home oder beim vernetzten Fahren. Eine Variante von NoSQL, die Dokumenten-Datenbanken, werden häufig in kleinen bis mittleren Projekten eingesetzt, wo Daten in nicht allzu großer Komplexität und Menge zwischen verschiedenen Systemen ausgetauscht werden sollen. Mit so einer Datenbank ist man flexibel und kann auch dann weiter arbeiten, wenn sich die Schnittstellen ändern, ohne erst das ganze Datenmodell neu definieren zu müssen.
com! professional: NoSQL ist besonders für nicht strukturierte oder semistrukturierte Daten geeignet. Sehen Sie darin auch einen der Hauptvorteile?
Kleiner: Davon bin ich nicht so ganz überzeugt. Alle aktuellen relationalen Systeme können beispielsweise auch XML-Dokumente speichern. Die Frage ist weniger, in welchem Format die Daten vorliegen, sondern vielmehr, was man mit der Speicherung bezweckt. Sollen die Daten beispielsweise durchsucht und analysiert werden können? Das wird schwierig, wenn keine Struktur vorgegeben ist.
com! professional: Wie sieht es mit Streaming-Daten aus?
Kleiner: Damit können relationale Systeme in der Tat Schwierigkeiten haben, wenn sehr viele Daten sehr schnell gespeichert werden müssen. Sie sind nicht dafür ausgelegt, sehr viele parallele Schreibzugriffe zu verarbeiten. NoSQL-Systeme können durch ihre Skalierbarkeit hier Vorteile bieten.
com! professional: Worin sehen Sie die größten Nachteile von NoSQL?
Kleiner: Der große Vorteil, kein explizites Datenmodell entwickeln zu müssen, ist gleichzeitig der größte Nachteil. Entwickler verwenden NoSQL-Datenbanken gerne, weil sie ohne großen Aufwand ihre Daten darin speichern können. Wenn die Anwendung aber nicht gut dokumentiert ist oder später Fehler auftreten, ist es ausgesprochen schwierig, die Ursachen dafür zu finden, weil höchstens die ursprünglichen Entwickler wissen, wie die Daten überhaupt strukturiert sind.
com! professional: Raten Sie also auch beim Einsatz von NoSQL dazu, immer ein Datenmodell zu entwerfen?
Kleiner: Man sollte sich auch beim Einsatz von NoSQL Gedanken über die Struktur der Daten machen. Es muss ja nicht in der Tiefe und Ausführlichkeit sein, wie das bei relationalen Systemen notwendig ist.
com! professional: Viele NoSQL-Datenbanken sind kostenlos. Ist das auch ein Anreiz, sie einzusetzen?
Kleiner: Kostenlose Varianten gibt es mittlerweile auch von relationalen Systemen. Wenn man Enterprise-Features benötigt, muss man auch bei NoSQL-Systemen zu den kostenpflichtigen Versionen greifen. Dennoch kommt man in der Regel immer noch wesentlich günstiger weg als mit hochpreisigen traditionellen Systemen wie DB2 oder Oracle.
com! professional: Was schätzen Anwender an NoSQL-Datenbanken noch, abgesehen vom Preis?
Kleiner: Die Einstiegshürde ist nicht so hoch wie bei den klassischen Systemen. Eine Oracle-Datenbank installiert man nicht mal so eben in einem Tag. NoSQL-Systeme sind dagegen schnell einsatzbereit. Die meisten NoSQL-Datenbanken sind außerdem für eine horizontale Skalierung konzipiert. Während sich relationale Systeme im Wesentlichen nur durch neue, stärkere Hardware beschleunigen lassen, fügt man im NoSQL-Umfeld einfach zusätzliche Server oder Rechenknoten hinzu. Man kann daher sehr dynamisch mehr Leistung bereitstellen.
com! professional: Eignen sich NoSQL-Datenbanken deshalb auch besonders gut für die Nutzung in der Cloud?
Kleiner: Ja, das ist einer der Gründe, warum NoSQL-Datenbanken gerne in der Cloud betrieben werden. Starke Schwankungen in den Lastanforderungen kann man über eine solche Infrastruktur am besten abdecken.
com! professional: Gibt es weitere Gründe, die für NoSQL aus der Cloud sprechen?
Kleiner: Man spart Zeit, unter Umständen auch Geld, und benötigt weniger Personal für die Implementierung und Verwaltung. NoSQL-Datenbanken wie MongoDB kann man fertig in der Cloud buchen und direkt einsetzen.
com! professional: Nach welchen Kriterien sollten Unternehmen eine NoSQL-Datenbank aus der Cloud auswählen?
Kleiner: Entscheidend ist, welche Daten gespeichert werden sollen und wie die Abfragen auf diese Daten aussehen. Wie groß sind die Datenmengen, wie komplex sind die Daten und mit welcher Dynamik ist zu rechnen? Das sind wichtige Punkte, die man sich klarmachen sollte.
com! professional: Spielen Konsistenzüberlegungen auch eine Rolle?
Kleiner: Ja sicher. Auch die meisten NoSQL-Datenbanken lassen sich so konfigurieren, dass sie die ACID-Kriterien (Atomicity, Consistency, Isolation und Durability) erfüllen, auch wenn das eher ein untypischer Anwendungsfall ist.
com! professional: Viele Anwender lockt ja die praktisch unbegrenzte Skalierbarkeit in die Cloud …
Kleiner: … die Frage ist nur, ob sie die wirklich brauchen. Ein einzelner Server kann schon eine Menge Daten speichern, viele Anwendungsanforderungen sind damit locker abgedeckt. Es muss sich also schon um ein extrem dynamisches System handeln, wenn die Cloud in dieser Hinsicht ihre Stärke ausspielen soll …
com! professional: … also typische Big-Data-Anwendungen?
Kleiner: Ja, im Prinzip schon. Allerdings ist der Begriff „Big“ in Big Data mit sehr unterschiedlichen Größenordnungen belegt. Einige glauben, sie haben Big Data, weil sie Tabellen mit ein paar Hunderttausend Zeilen verwenden. Das ist aber nicht wirklich „Big“, damit sollte jedes Datenbanksystem locker auch auf einem einzelnen Server klarkommen.
Cloud-PBX
Ecotel erweitert cloud.phone-Lösung um MS Teams-Integration
Die Telefonanlage aus der Cloud von Ecotel - ein OEM-Produkt von Communi5 - cloud.phone, ist ab sofort auch mit Microsoft-Teams-Integration verfügbar.
>>
Container
.NET 8 - Container bauen und veröffentlichen ganz einfach
Dockerfiles erfreuen sich großer Beliebtheit. Unter .NET 8 lassen sich Container für Konsolenanwendungen über den Befehl "dotnet publish" erzeugen.
>>
Personalien
Komsa stellt sich im Solution-Segment neu auf
Der Distributor richtet sein UC- und Cloud-Business neu aus und stellt mit Christof Legat einen neuen Vice President UC-Solutions vor, Friedrich Wahnschaffe ist als Vice President für das MS-Cloud-Geschäft von Komsa in Deutschland verantwortlich.
>>
Roadmap
Estos bringt neue Services und Produkte
Der Software-Hersteller feilt an seinem Partnerprogramm, hat Schlüsselpositionen neu besetzt und kündigt eine ganze Reihe neuer Produkte und Services an. Das ist die Estos-Roadmap bis Ende des Jahres.
>>