16.10.2015
Big Data in der Cloud
1. Teil: „AWS und Azure auf dem Prüfstand“
AWS und Azure auf dem Prüfstand



albund / Shutterstock.com
Datenberge lassen sich mit herkömmlichen Ansätzen nicht bewältigen. Helfen soll die Cloud mit ihren zwei führenden Dienstleistern Amazon und Microsoft.
An neuen Ideen mangelt es nicht. Die zwei führenden Cloud-Dienstleister – Amazon mit Amazon Web Services (AWS) und Microsoft mit Azure – überbieten sich gegenseitig im Wettlauf um das umfassendere Angebot an Big-Data-Lösungen mit einer recht unübersichtlichen Palette an Alternativen.
-
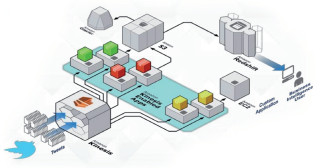
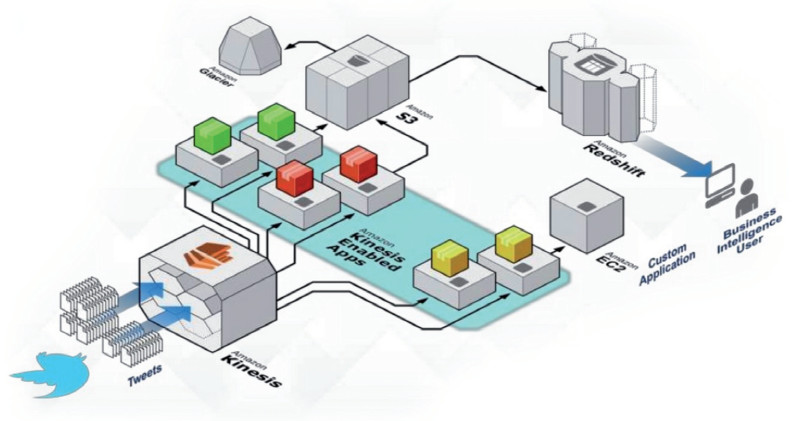
 Big Data aus sozialen Netzen: Beispiel eines Datenverarbeitungs-Workflows auf AWS unter Verwendung der Dienste Redshift, Kinesis, EC2, S3 und Glacier.Quelle:Amazon Web Services
Big Data aus sozialen Netzen: Beispiel eines Datenverarbeitungs-Workflows auf AWS unter Verwendung der Dienste Redshift, Kinesis, EC2, S3 und Glacier.Quelle:Amazon Web Services
Big Data und IoT
Unternehmen sammeln fein granulierte Daten über geschäftskritische Vorgänge von Web-Klickströmen über Social-Media-Interaktionen bis hin zu Messwerten aus Sicherheitskameras und Internet-of-Things-Sensoren (IoT). Bei diesen semistrukturierten Datenbeständen, die stetig anwachsen, spricht man von Big Data.
Unternehmen versprechen sich davon zusätzliche Einblicke in das Kauf- und Nutzungsverhalten der Kunden, Erkenntnisse für die Forschung und Entwicklung und eine verbesserte Entscheidungsgrundlage für die eigene Chefetage.
Herkömmliche Datenanalysesoftware à la Data Warehouse stößt bei Big Data schnell an ihre Grenzen. Rein relationalen Datenbanken fehlen die nötige Flexibilität im Umgang mit unstrukturierten oder semistrukturierten Daten und die Fähigkeiten zur parallelen Verarbeitung massiver Datenbestände in Echtzeit.
Um diese und andere Herausforderungen zu meistern, sind neue Ansätze und skalierbare Rechenkapazitäten gefragt. Auf in die Cloud, heißt die Devise.
2. Teil: „David Microsoft und Goliath Amazon“
David Microsoft und Goliath Amazon
Die beiden führenden Cloud-Anbieter im Bereich Big Data, AWS und Azure, liefern sich einen erbitterten Wettbewerb. Die Unterschiede zwischen beiden sind allerdings nach wie vor größer als ihre Gemeinsamkeiten.
-


 Satya Nadella, CEO von Microsoft: „In einer von Big Data dominierten Welt tragen winzige Datenmuster viel Gewicht.“
Satya Nadella, CEO von Microsoft: „In einer von Big Data dominierten Welt tragen winzige Datenmuster viel Gewicht.“

Als einer der Pioniere bei Big Data hat Amazon den zeitlichen Vorsprung genutzt, um das eigene Angebot an Diensten massiv auszubauen. Amazon punktet daher klar im Hinblick auf die Vielseitigkeit der verfügbaren Lösungen und ihren Reifegrad. So ist beispielsweise Cloudera Enterprise in einer produktionsreifen Edition auf AWS verfügbar. Für Azure gibt es Cloudera vorerst nur in einer Vorabversion.
Skalierbarkeit: Im Lauf der Jahre konnte sich AWS einen weltweiten Marktanteil von aktuell 80 Prozent sichern und sich als der bisher unangefochtene Markt- und Technologieführer behaupten. Amazons massive Kapazitäten spiegeln sich in den Zahlen wider. Die Deutsche Bank schätzt den weltweiten Umsatz von AWS 2014 auf satte 6 Milliarden Dollar.

Orchestrierung und Integration: Was die orchestrierte Bereitstellung der benötigten Cloud-Ressourcen und die massive Skalierbarkeit angeht, so hat AWS klar die Nase vorn. Azure trumpft im Hinblick auf die Integration mit Microsoft-eigenen Technologien.
Unterstützung für Open Source: Viele der führenden Big-Data-Lösungen verdanken ihre Existenz der Open-Source-Gemeinde. Sowohl AWS als auch Azure unterstützen daher quelloffene Software wie Linux, das Big-Data-Framework Hadoop, das Container-Framework Docker und zahlreiche andere quelloffene Lösungen.
-
 Kostenvoranschlag: Der AWS-Preisrechner geht zwar bis ins kleinste Detail, berücksichtigt allerdings nicht alle Kostenfaktoren.
Kostenvoranschlag: Der AWS-Preisrechner geht zwar bis ins kleinste Detail, berücksichtigt allerdings nicht alle Kostenfaktoren.
Wer von den beiden Dienstleistern im direkten Preisvergleich führt, lässt sich nicht pauschal beurteilen. In bestimmten Nutzungsszenarien, insbesondere bei den eigenen Produkten, hat Microsoft einen klaren Vorsprung und zeigt sich kulant, flexibel und innovativ. Azure gönnt dem Anwender zum Beispiel mehr Arbeitsspeicher als Amazon.
Datenschutz: Sowohl AWS als auch Microsoft Azure erfüllen mit ihren europäischen Datencentern gültige Datenschutzbestimmungen der EU. Amazon AWS stellt in Europa zwei Rechenzentren bereit: in Frankfurt und Irland. Microsoft hat Rechenzentren in Irland und in den Niederlanden. Wer ausschließlich eine Datenhaltung in Deutschland will, sollte daher von Azure vorerst Abstand nehmen.
Wie diese Vor- und Nachteile im Detail zu gewichten sind, hängt von dem ins Auge gefassten Nutzungsszenario ab. Gerade Big Data bietet viel Spielraum für innovative Lösungen.
3. Teil: „Big Data in der Cloud auf AWS und Azure“
Big Data in der Cloud auf AWS und Azure
Wer Big Data in der Cloud auswerten und aufbewahren möchte, kann verwaltete Dienste nutzen oder Infrastrukturdienste in Eigenregie einrichten. Soll etwa Hadoop das Kernstück des Big-Data-Deployments sein, dann bietet sich auf AWS der verwaltete Dienst EMR (Elastic MapReduce) an. Alternativ lässt sich Apache Hadoop auf EC2/VPC und S3 selbst aufsetzen und dann auch selbst administrieren. Auch Azure unterstützt beide Ansätze.
-


 Martin Geier, Managing Director AWS Deutschland: „Die Kunden bestimmen genau den Ort, wo ihre Daten gespeichert werden. (…) Der Kunde ist jederzeit Herr seiner Daten.“
Martin Geier, Managing Director AWS Deutschland: „Die Kunden bestimmen genau den Ort, wo ihre Daten gespeichert werden. (…) Der Kunde ist jederzeit Herr seiner Daten.“

Verwaltete Dienste
Verwaltete Dienste rund um Big Data auf AWS beinhalten folgende Module:
Redshift: Hierbei handelt es sich um ein Cluster-basiertes Data Warehouse in massiv paralleler Architektur mit Fähigkeiten zur Selbstheilung und bedarfsgerechter Skalierung. Dank seiner Unterstützung für verteilte SQL-Operationen integriert sich Redshift mit bestehenden BI-Werkzeugen, sofern diese zu SQL kompatibel sind. Typische Anwendungsszenarien beinhalten etwa die Analyse der Seitenaufrufe und Klickströme oder die Auswertung historischer Daten aus Finanzmärkten oder Vertriebskanälen.
Kinesis: Die Echtzeit-Handhabung von Big-Data-Datenströmen übernimmt der Dienst Kinesis. Kinesis bezieht Daten aus einem Langzeitspeicher wie S3 oder Redshift, stellt sie für eine beschränkte Zeit zur Analyse bereit und legt sie danach wieder in einem Langzeitspeicher ab.
-
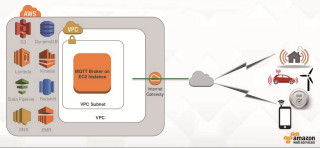
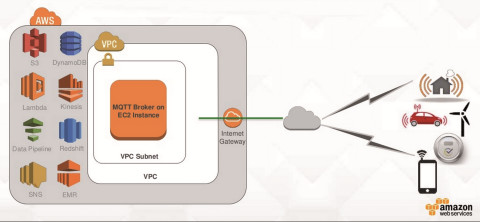
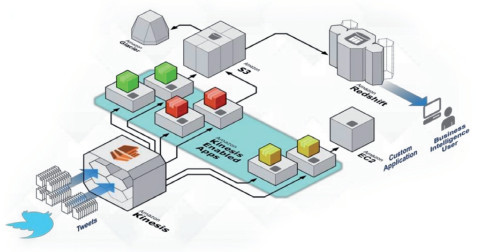
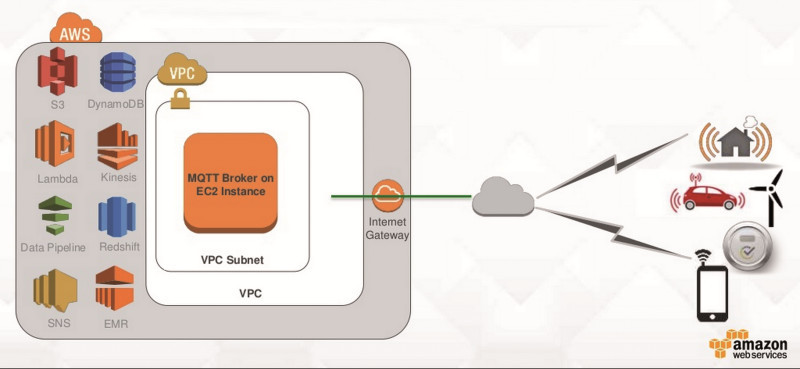
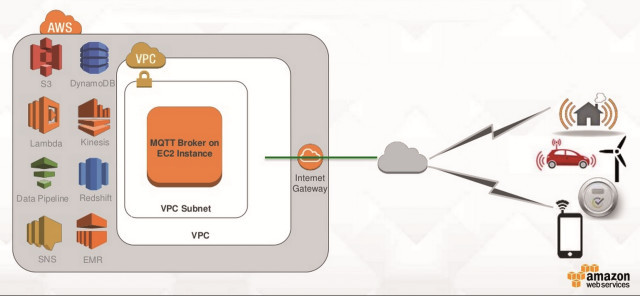 Echtzeitanalyse von Sensordaten in der Cloud: Big-Data-Datenanalyseworkflows auf AWS setzen sich aus vielen kleinen Puzzleteilchen zusammenQuelle:Amazon Web Services
Echtzeitanalyse von Sensordaten in der Cloud: Big-Data-Datenanalyseworkflows auf AWS setzen sich aus vielen kleinen Puzzleteilchen zusammenQuelle:Amazon Web Services
EMR (Elastic MapReduce): EMR ist Amazons eigene Implementierung von Hadoop als vollständig verwalteter Dienst. Der Service unterstützt alle üblichen Tools für Hadoop einschließlich Hive (ein Data Warehouse), Pig, Spark, HBase, Hunk und Impala; der Anwender kann weitere Softwarelösungen in das Ökosystem einbinden. Zusätzlich zu Hadoops eigenem verteilten Dateisystem HDFS werden zur weiteren Kostensenkung nativer S3-Speicher von Amazon und EMRFS (Elastic Map Reduce File System) unterstützt (empfehlenswert vor allem für historische Datenbestände). Typische Anwendungsszenarien für EMR sind die Verarbeitung von Log-Dateien, ETL-Transaktionen, die Analyse von Klickströmen und Risikomodellierung.
DynamoDB: Bei DynamoDB handelt es sich um Amazons eigenen NoSQL-Datenspeicher, den Amazon als vollständig verwalteten Dienst bereitstellt. DynamoDB kann sowohl Dokumente als auch Schlüssel-Wert-Paare erfassen. Typische Szenarien sind die Aufbewahrung von Daten aus IoT-Sensoren sowie Web und Mobile Analytics.
-
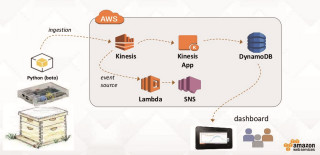
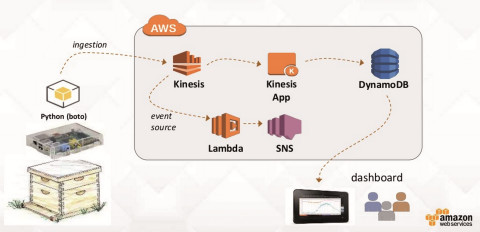
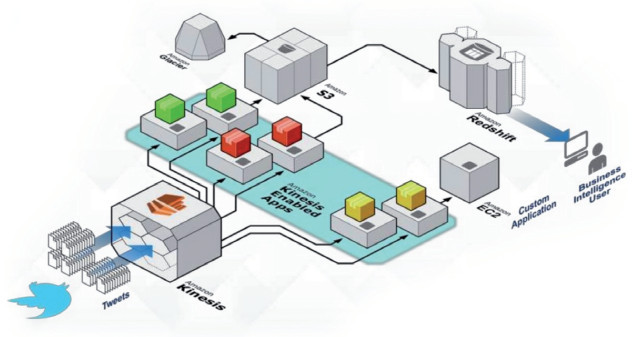
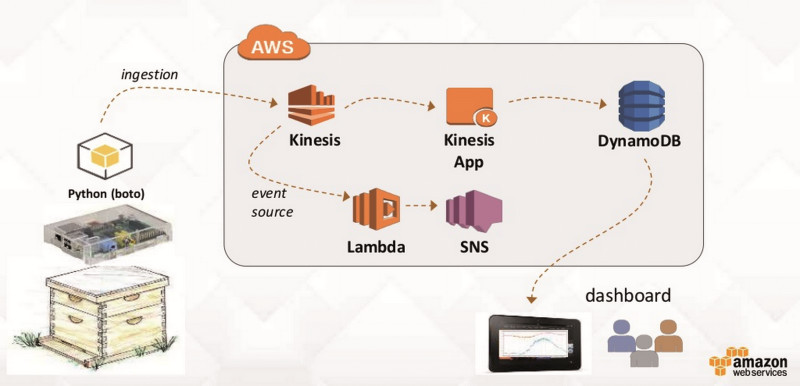
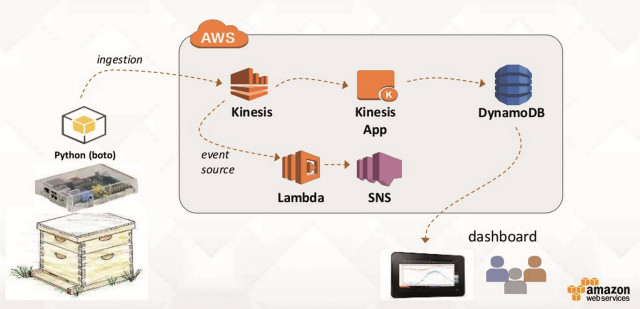 Temperaturüberwachung: Der Ablauf der Datenerfassung aus Sensoren in einem Honigbienenstock illustriert praktische Anwendbarkeit von Big-Data-Datenströmen im IoT-ZeitalterQuelle:Amazon Web Services
Temperaturüberwachung: Der Ablauf der Datenerfassung aus Sensoren in einem Honigbienenstock illustriert praktische Anwendbarkeit von Big-Data-Datenströmen im IoT-ZeitalterQuelle:Amazon Web Services
AWS Machine Learning: Big Data hat nur dann einen messbaren Wert, wenn sich daraus umsetzbare Erkenntnisse gewinnen lassen. Helfen soll künstliche Intelligenz, die Krönung prädiktiver Datenanalyse. Auch für diesen Einsatzzweck hat Amazon bereits einen Dienst parat: AWS Machine Learning zur Entwicklung von Prognosen, für die Personalisierung von Angeboten und die maschinelle Auswertung von Dokumenten in der Cloud.
Die Handhabung von Big Data auf AWS erfordert typischerweise die Nutzung verschiedener weiterer Dienste wie beispielsweise Data Pipeline für die zeitgesteuerte Datenübertragung zwischen Diensten mit Möglichkeiten zur Integration mit einem externen Datencenter oder Lambda für die Ereignisüberwachung. Business-Intelligence-Software ist praktisch auch nur einen Klick entfernt. Auf Amazon Marketplace gibt es sie als fertig installierte Maschinen-Images.
4. Teil: „Big Data mit Hadoop auf Microsoft Azure“
Big Data mit Hadoop auf Microsoft Azure
Auch Microsoft baut den eigenen Marktplatz für Enterprise-Software unter Hochdruck aus. Mit Azure machte sich Microsoft bereit, zu Amazon AWS aufzuschließen. Anders als AWS und seine übrigen Rivalen konnte der Softwareriese eine einzigartige Trumpfkarte aus dem Ärmel ziehen: die eigenen Softwarelizenzen mit den eigenen Cloud-Diensten kostengünstig zu bündeln und als optimierte Gesamtlösung anzubieten, um den Unternehmen die Nutzung von Azure schmackhaft zu machen.
-
 Kostenrechner für Azure: Microsofts Bruch mit der Tradition unüberschaubarer Lizenzpreise fällt in der Cloud positiv auf.
Kostenrechner für Azure: Microsofts Bruch mit der Tradition unüberschaubarer Lizenzpreise fällt in der Cloud positiv auf.
Auf der diesjährigen Build Developer Conference stand das Thema Big Data ein weiteres Mal im Vordergrund. Kein Wunder, denn mit Big Data steht und fällt künftig der Erfolg eines Unternehmens. Microsofts aktuelle Hadoop-Implementierung beinhaltet die Dienste HDInsight und Azure Data Lake, das sich derzeit noch im Preview-Stadium befindet.
Hadoop als Dienst auf Azure
Mit HDInsight (zuvor AHoWA für Apache Hadoop on Windows Azure) bietet Microsoft eine Implementierung des quelloffenen Frameworks Hadoop zur Verarbeitung von Big Data als Dienst auf Microsoft Azure an. HDInsight basiert auf Hortonworks Data Platform (HDP), einer Hadoop-Distribution, die sich etwa auch auf die Zusammenarbeit mit SAP HANA versteht.
-
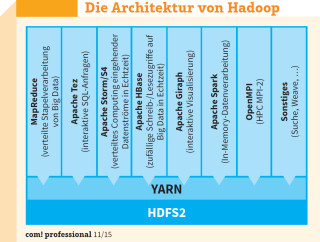
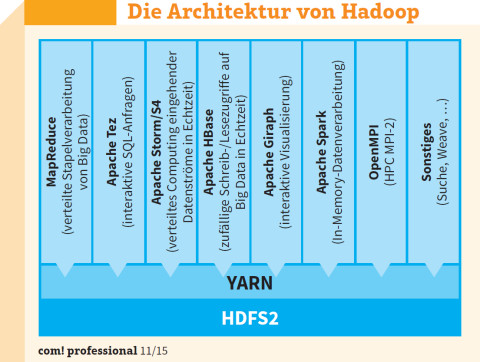
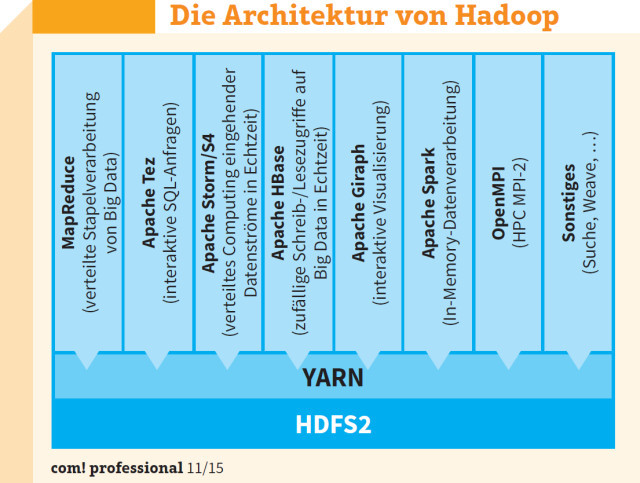 Modular und erweiterbar: YARN ist einer der wichtigsten Teile von Hadoop. Es handelt sich dabei eigentlich um eine Cluster-Verwaltungstechnik für Hadoop 2.x.
Modular und erweiterbar: YARN ist einer der wichtigsten Teile von Hadoop. Es handelt sich dabei eigentlich um eine Cluster-Verwaltungstechnik für Hadoop 2.x.
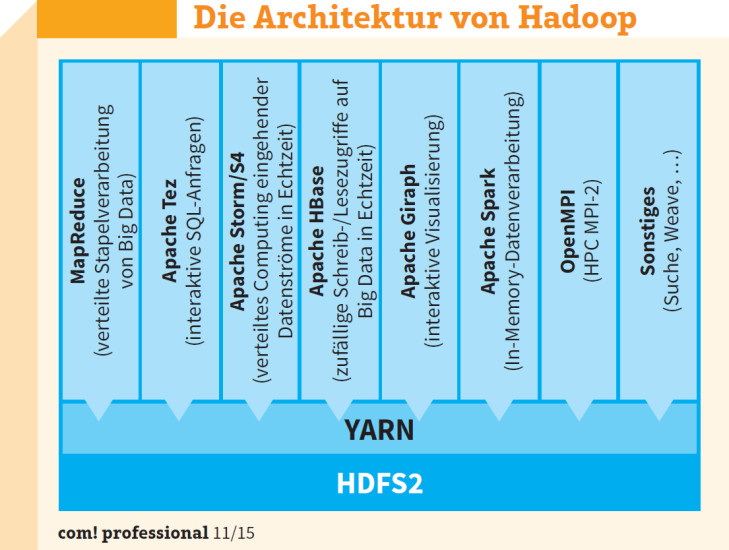
Außerdem bietet HDInsight die freie Wahl der Programmiersprache zur Erstellung und Steuerung von Hadoop-Aufträgen, einschließlich C#, Java und .NET. Das Besondere an HDInsight ist die Integration in Microsoft Excel zur Visualisierung der Resultate der Datenanalyse.
HDInsight kann unternehmenseigene Hadoop-Installationen im Datencenter an Azure anbinden, um bedarfsgerecht – und somit kostensenkend – skalieren zu können. Mit Hilfe benutzerdefinierter Skripte lassen sich nahezu beliebige Projekte integrieren und Erweiterungen nutzen, darunter Spark, R, Giraph und Solr.
HDInsight beinhaltet HBase, eine spaltenbasierte NoSQL-Datenbank auf der Basis von HDFS. Diese Integration ermöglicht die Umsetzung umfassender OLTP-Workloads mit nicht relationalen Daten. Typische Szenarien sind die Datenerfassung von Benutzerinteraktionen mit einer Webapplikation oder aus IoT-Sensoren direkt in Azure Blob-Speicher.
Microsofts uneingestandenes Motto „embrace and extend“ (im Deutschen etwa „annehmen und erweitern“) trägt offenbar Früchte, denn Microsofts Ökosystem an Big-Data-Lösungen hat in der letzten Zeit so einiges an Neuzugängen mit Wurzeln in der Open-Source-Gemeinde vorzuweisen, das vielversprechend scheint. So hat man nach dem Erfolg von HDInsight mit Azure Data Lake einen eigenen HDFS-Dienst vorgestellt.
5. Teil: „Azure Data Lake für Big-Data-Analyse-Workloads“
Azure Data Lake für Big-Data-Analyse-Workloads
Bei Azure Data Lake handelt es sich um ein neues Repository für Big-Data-Analyse-Workloads (noch Preview). Der Dienst setzt auf HDFS auf, Hadoops verteiltem Dateisystem, kann aber auch NoSQL-Datenbanksysteme wie Schlüssel-Wert-Paare integrieren.

Azure Data Lake wurde für massiven Datendurchsatz großer Analysesysteme mit Fähigkeiten zur Parallelverarbeitung und für kleine Schreibvorgänge optimiert – etwa Sensordaten aus dem IoT. Der Dienst soll dank der niedrigen Latenz nicht nur gewöhnliche Stapelverarbeitung von Aufträgen, sondern auch Datenanalysevorgänge nahezu in Echtzeit unterstützen. Es bleibt abzuwarten, inwiefern sich die hohe Leistung auf den Preis auswirkt und welche anderen Optionen Microsoft im Hinblick auf die Aufbewahrung und Auswertung von Big Data in Zukunft vorsieht.
Der Azure-Standardspeicher zählte bisher jedenfalls zu den Flaschenhälsen. Microsofts Bemühungen um eine enge Integration führender Open-Source-Lösungen mit der eigenen Infrastruktur und Software sind zumindest lobenswert. Microsofts neueste Technologien wie Azure Machine Learning für prädiktive Datenanalyse und Azure Data Factory für Datenorchestrierung deuten auf eine überaus interessante Zukunft hin.
Fazit
Big Data erfreut sich eines rapiden Wachstums. Die Cloud verspricht massive Datenverarbeitungsfähigkeiten, lockt Unternehmen mit niedrigen Einstiegskosten im Pay-as-you-go-Modell und mit robuster, bedarfsgerechter Skalierbarkeit. Für viele Unternehmen stellt sich lediglich die Frage, welche Cloud die bessere Wahl darstellt.
Die zwei führenden Cloud-Dienstleister liefern sich mit ihren Lösungen rund um Big Data einen entschlossenen Schlagabtausch. Microsoft versucht, Amazons Vorsprung durch eine engere Integration der eigenen Enterprise-Software mit Open-Source-Lösungen wie Hadoop zu kompensieren und ermöglicht dem Anwender sogar die freie Wahl der Server-Plattform (Windows Server oder GNU/Linux).
Ein gesunder Wettbewerb kann den Anwendern im Big-Data-Zeitalter nur recht sein.
Weitere Infos
Huawei Roadshow 2024
Technologie auf Rädern - der Show-Truck von Huawei ist unterwegs
Die Huawei Europe Enterprise Roadshow läuft dieses Jahr unter dem Thema "Digital & Green: Accelerate Industrial Intelligence". Im Show-Truck zeigt das Unternehmen neueste Produkte und Lösungen. Ziel ist es, Kunden und Partner zusammenzubringen.
>>
Nach der Unify-Übernahme
Mitels kombinierte Portfoliostrategie
Der UCC-Spezialist Mitel bereinigt nach der Unify-Übernahme sein Portfolio – und möchte sich auf die Bereiche Hybrid Cloud-Anwendungen, Integrationsmöglichkeiten in vertikalen Branchen sowie auf den DECT-Bereich konzentrieren.
>>
Bildbearbeitungs-Tipps
Das neue Paint - Das kann es inklusive KI-Funktionen
Microsoft hat seine altehrwürdige Bildbearbeitungs-Software Paint generalüberholt. Wir erklären die neuen Funktionen und was Sie damit anstellen können.
>>
Umweltschutz
Netcloud erhält ISO 14001 Zertifizierung für Umweltmanagement
Das Schweizer ICT-Unternehmen Netcloud hat sich erstmalig im Rahmen eines Audits nach ISO 14001 zertifizieren lassen. Die ISO-Zertifizierung erkennt an wenn Unternehmen sich nachhaltigen Geschäftspraktiken verpflichten.
>>