15.02.2016
Relational vs. NoSQL
1. Teil: „Die richtigen Datenbanken für Big Data“
Die richtigen Datenbanken für Big Data
Autor: com! professional



81095667
Verschiedene Datenbanklösungen müssen nahtlos verknüpft werden. Die große Herausforderung ist dabei die Integration von Datentypen aus verschiedensten Quellen an einem zentralen Knotenpunkt.
Digitalisierung, Internet der Dinge, Industrie 4.0 – diese Begriffe bestimmen viele Diskussionen in den IT-Abteilungen der Unternehmen und den Büros von CIOs und CTOs. Der gemeinsame Nenner dabei heißt: Big Data.

„Alles neu“ geht nicht
Mittlerweile gibt es unterschiedlichste Lösungsplattformen und Technologien, um mit Big Data umzugehen. Was man aber in der Regel nicht ganz oben auf der Liste findet, ist ein relationales Datenbankmanagementsystem (RDBMS). Vielmehr scheint das Potenzial einer digitalen Welt voller intelligenter Geräte, die miteinander kommunizieren, nach ganz neuen Wegen zu verlangen, um den Strom immer neuer, teils unstrukturierter Datentypen effizient nutzen zu können. Solche Lösungen werden meist mit dem Schlagwort NoSQL in Verbindung gebracht.
Darüber sollte man aber nicht vergessen, dass sich die Grundlagen trotz des Siegeszugs innovativer NoSQL-Lösungen nicht ändern. Unternehmensdaten müssen weiter in einem breiteren Kontext verstanden und detailliert bearbeitet werden können. CEOs wie auch Datenspezialisten müssen sich immer noch damit befassen, wie gesammelte und verarbeitete Daten mit allen anderen Unternehmensdaten in Zusammenhang stehen.
Traditionelle geschäftskritische Daten etwa für Budgetierung oder Prognose sind und bleiben wichtig. Finanzdaten sind primär strukturierte Daten und müssen zuverlässig, modifizierbar und sicher gespeichert werden, weshalb die relationale Datenbank weiterhin eine zentrale Rolle in der Datenlandschaft des Unternehmens spielen wird.
2. Teil: „Das Datendilemma eigenständiger Nischenlösungen“
Das Datendilemma eigenständiger Nischenlösungen
Ein Rechenzentrum gleicht heute in puncto Datenmanagement-Technologien meist einem Flickenteppich: Das Sammelsurium reicht von relationalen Datenbanken über eigenständige reine NoSQL-Nischenlösungen bis hin zu spezialisierten Erweiterungen.

Allerdings haben die meisten von ihnen sehr vereinfachte Funktionen, wenn es darum geht, mit den Daten tatsächlich etwas zu tun. Bei solchen Lösungen wird die eigentliche Datenverarbeitung in die Anwendung verschoben, sodass die Entwicklung von Applikationen sehr viel komplexer ausfällt. Zudem fehlt typischen NoSQL-Lösungen die Konformität mit den sogenannten ACID-Eigenschaften für verlässliche Verarbeitungsschritte: Unteilbarkeit, Konsistenz, Isolation, Dauerhaftigkeit. Deshalb gibt es bei ihnen keine absolute Garantie, dass Transaktionen in der Datenbank sicher verarbeitet werden. Um dennoch ACID-Konformität zu erreichen, muss in den Anwendungen immer wieder sehr komplexer Code geschrieben werden.
Auf der anderen Seite wurden relationale DBMS von Anfang an entwickelt, um die ACID-Eigenschaften stets zu erfüllen, sodass sie sehr zuverlässig und robust funktionieren und mit den in ihnen gespeicherten strukturierten Daten auf einer sehr detaillierten Ebene gearbeitet werden kann. Zudem ermöglicht der relationale Charakter des DBMS einen umfassenden Überblick über alle gespeicherten Daten und darüber, wie sie mit anderen Unternehmensdaten in Beziehung stehen.
-
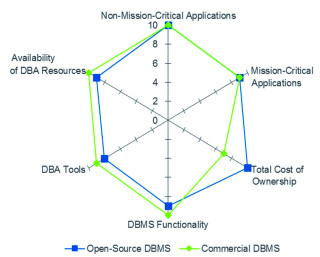
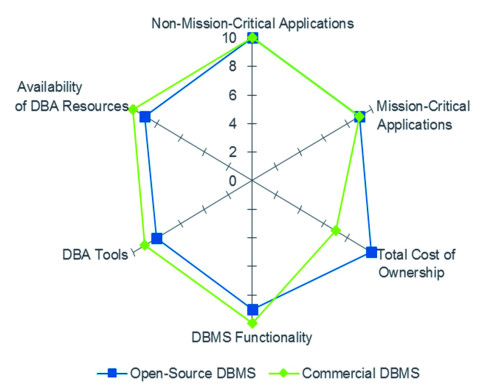
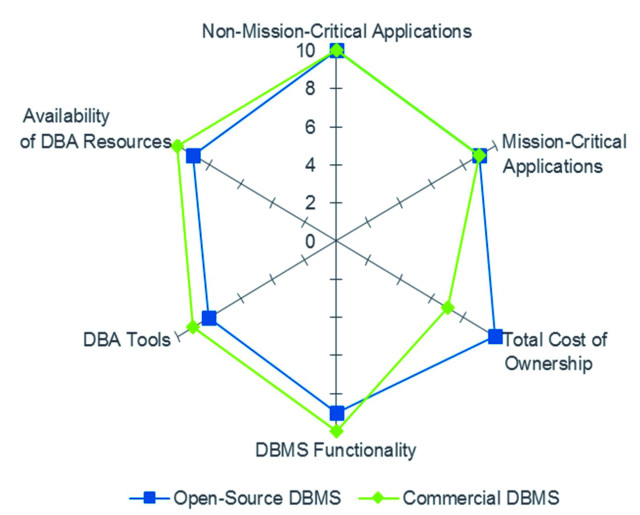 Vorteil Open Source: Freie DBMS erfüllen mittlerweile die Anforderungen der Unternehmen – zu einem Bruchteil der Kosten.Quelle:Gartner, State of Open Source RDBMSs, 2015
Vorteil Open Source: Freie DBMS erfüllen mittlerweile die Anforderungen der Unternehmen – zu einem Bruchteil der Kosten.Quelle:Gartner, State of Open Source RDBMSs, 2015
Gemeinsam sind sie stark
Ohne Zweifel werden NoSQL-Funktionen bestehen bleiben und in Zukunft sogar noch wichtiger werden, denn Big Data- und Webapplikationen verändern schon heute das Datenmanagement von Unternehmen. Jedoch fehlt NoSQL-only-Lösungen die erwähnte ACID-Konformität, die insbesondere für den sicheren Umgang mit geschäftskritischen Daten von entscheidender Bedeutung ist.
Auf der anderen Seite fehlt den relationalen Datenbanken mit ACID-Konformität oft die erforderliche Performance, um auch unstrukturierte Daten effizient zu verarbeiten. Da Datensicherheit aber nicht Gegenstand von Kompromissen sein darf, müssen relationale Datenbankmanagementsysteme heute in der Lage sein, ein Maximum unterschiedlichster Datentypen zu verarbeiten, und NoSQL-Lösungen müssen sowohl Sicherheits- als auch Compliance-Funktionen integrieren, um wettbewerbsfähig zu bleiben.
In den nächsten Jahren werden sich Unternehmen also bei der Auswahl ihres DBMS nicht von einer Entweder-oder-Entscheidung leiten lassen, sondern von einem netzwerkähnlichen Ansatz ausgehen, bei dem die verschiedenen Lösungen nahtlos miteinander in Verbindung stehen und ihre jeweiligen Stärken kombinieren, um gemeinsam das Unternehmens-DBMS zu schaffen, das für Big Data gewappnet ist.
3. Teil: „Den Knoten knüpfen für verschiedenste Datentypen“
Den Knoten knüpfen für verschiedenste Datentypen
Die große Herausforderung ist damit die Integration von Datentypen aus verschiedensten Quellen an einem zentralen Knotenpunkt – erst dann lassen sie sich wirklich analysieren und verstehen sowie gemeinsam mit bestehenden Daten aus langjährigen Lösungen nutzen. Mit anderen Worten: Daten aus Hadoop-Clustern oder MongoDB-Implementierungen müssen mit relationalen Tabellen in Einklang gebracht werden, um das Gesamtbild zu sehen, aussagekräftige Momentaufnahmen zu erhalten und mit wirklich allen Daten im Unternehmen wertschöpfend und sicher arbeiten zu können.
-
 Big-Data-Apps: Weil PostgreSQL Sprachen und Formate wie Javascript, Python, Ruby, node.js, JSON, Geospatial und XML unterstützt, lassen sich damit sehr einfach Apps schreiben.Quelle:EnterpriseDB
Big-Data-Apps: Weil PostgreSQL Sprachen und Formate wie Javascript, Python, Ruby, node.js, JSON, Geospatial und XML unterstützt, lassen sich damit sehr einfach Apps schreiben.Quelle:EnterpriseDB
Der JSON-Datentyp ist ein Beispiel für ein Objekt, das eine wichtige neue Funktion eingeführt hat. Der Datentyp wird von einem anderen Feature namens „Foreign Data Wrappers“ verwendet. Dieses ist zentral für die Fähigkeit, Daten aus anderen Datenbanken zu unterstützen – und markiert einen wichtigen Schritt auf dem Weg zum Datenbanknetzwerk.
Foreign Data Wrappers erlauben die Integration von Daten aus externen NoSQL-Implementierungen wie MongoDB, MySQL oder Hadoop-Clustern in Postgres-Tabellen. So lassen sich unstrukturierte Daten, die in NoSQL-Lösungen innerhalb des Datenbanknetzwerks gespeichert sind, in eine Umgebung ziehen, deren transaktionale Funktionen den nötigen Detailgrad haben und die vollständig ACID-konform ist, um die nötige Datenkonsistenz zu gewährleisten. Dies ermöglicht es, Postgres als Datenbank-Hub zu verwenden, sodass Nutzer SQL-Abfragen für externe Datenquellen lesen und schreiben können, als wären sie Teil der eigenen Postgres-Tabelle.
Mit JSON/JSONB werden unstrukturierte und semistrukturierte Implementierungen unterstützt, deren Datentypen erkannt und die Daten mit relationalen Tabellen kombiniert. Da dabei aus einer Postgres-Tabelle heraus gearbeitet wird, geschieht dies unter Einhaltung der ACID-Grundsätze relationaler Technologien sowie zentraler Regeln der Geschäftsabwicklung und der Logik. So lassen sich die Grenzen zwischen Datensilos innerhalb heterogener Datenbanklandschaften aufbrechen und Anwendern wird ein ganzheitlicher Einblick in ihre Daten gewährt.
Personalie
CEO Frank Roebers verlässt Synaxon
Er war 32 Jahre bei der Verbundgruppe und hat sie maßgeblich geprägt. Nun tritt der CEO von Synaxon Ende des Jahres zurück – und gründet ein eigenes Unternehmen.
>>
Konferenz
Wird generative KI Software-Ingenieure ersetzen? DWX-Keynote
Auf der Developer Week '24 wird Professor Alexander Pretschner von der TU München eine der Keynotes halten. Er klärt auf, ob Ihr Job in Gefahr ist.
>>
Test-Framework
Testautomatisierung mit C# und Atata
Atata ist ein umfassendes C#-Framework für die Web-Testautomatisierung, das auf Selenium WebDriver basiert. Es verwendet das Fluent Page Object Pattern und verfügt über ein einzigartiges Protokollierungssystem sowie Trigger-Funktionalitäten.
>>
Programmiersprache
Primärkonstruktoren in C# erleichtern den Code-Refactoring-Prozess
Zusammenfassen, was zusammen gehört: Dabei helfen die in C# 12 neu eingeführten Primärkonstruktoren, indem sie Code kürzer und klarer machen.
>>