06.10.2014
Datenanalysen
1. Teil: „Big Data in kleinen und mittleren Unternehmen“
Big Data in kleinen und mittleren Unternehmen
Autor: Hartmut Wiehr



Foto: sorbetto / Stockphoto
Der Wettkampf um die IT-Technologie der Zukunft ist voll entbrannt. Auch kleine und mittlere Unternehmen profitieren von den Möglichkeiten systematischer Datenanalysen.
Die IT-Industrie hat Big Data zu einem der vorherrschenden Trends dieser Tage erklärt. Dabei setzen laut Gartner bisher nur 8 Prozent aller Unternehmen Big-Data-Technologien ein. Mehrheitlich sind es große Betriebe, der Rest hält sich zurück. Big Data als neue Waffe im Umgang mit der Konkurrenz ist noch nicht richtig in der Realität angekommen. Dabei würde es sich für alle Unternehmen – auch für die kleinen und mittleren (KMUs) – durchaus lohnen, aus ihren verfügbaren Daten mehr Nutzen zu ziehen.
-


 „Mit Big Data bekommen Unternehmen eine Macht, die es so bisher nicht gab.“ - Brian Hopkins, Vice President, Principal Analyst Forrester, www.forrester.com
„Mit Big Data bekommen Unternehmen eine Macht, die es so bisher nicht gab.“ - Brian Hopkins, Vice President, Principal Analyst Forrester, www.forrester.com

Tante-Emma-Effekt
Ein beliebtes Beispiel, um die Zielrichtung von Big Data zu erklären, ist der Tante-Emma-Laden. Tante Emma stand jahrzehntelang in ihrem kleinen Laden an der Ecke und kannte jeden Kunden und seine besonderen Wünsche. Der Kunde sagte nur „Guten Tag“ und schon bot ihm Tante Emma die Waren an, die er haben wollte. Sie hatte alles in ihrem Gedächtnis und ihre Erfahrung sagte ihr, was zu tun war. Schriftliche Notizen waren nur im Ausnahmefall erforderlich.
Im Supermarkt an der Ecke oder auf der grünen Wiese finden wir eine ganz andere Situation vor. Es sind Hunderte oder Tausende Kunden pro Tag, die an den geplagten Kassiererinnen vorbei zu ihren Autos und nach Hause strömen. Man kennt sich nur in den seltensten Fällen und das spielt an der Kasse auch keine Rolle.
-
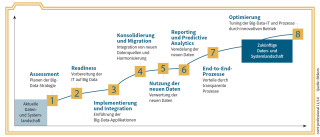
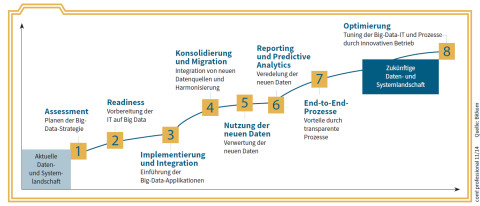
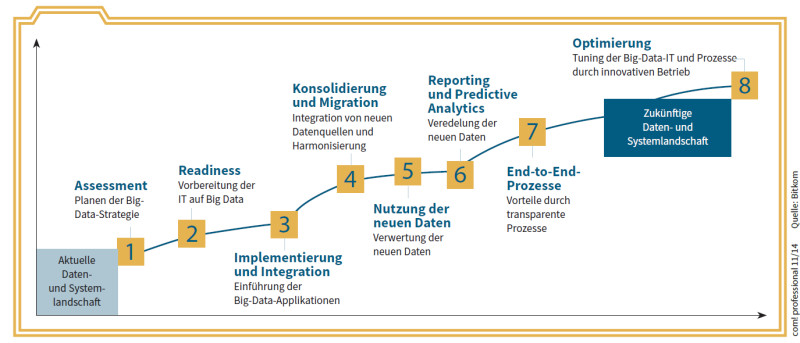
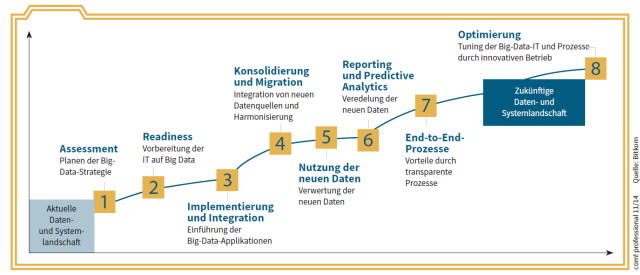 Big-Data-Projekte: Mehrstufige Vorgehensmodelle wie dieses helfen bei der Umsetzung eines Big-Data-Projekts.Quelle: com! professional / Bitkom
Big-Data-Projekte: Mehrstufige Vorgehensmodelle wie dieses helfen bei der Umsetzung eines Big-Data-Projekts.Quelle: com! professional / Bitkom
Dem Ideal der lückenlosen Erfassung sämtlicher Kundendaten und daraus abzuleitender individueller Angebote eifern inzwischen ganze Branchen nach. Banken oder Versicherungen beispielsweise sind gut bestückt mit Zahlenmaterial über ihre Kunden. Auf die wochen- oder monatelangen Auswertungen der Daten wollen viele Chefetagen aber nicht mehr warten. Das ist die Stunde von Big Data und Analytics.
Forrester Research hat in einem aktuellen Report die fünf wichtigsten strategischen Fragen zu Big Data festgehalten. Daraus und aus weiteren Berichten von Marktbeobachtern wie dem ITK-Verband Bitkom lassen sich die wesentlichen Schritte ableiten, die insbesondere kleinere oder mittlere Firmen unternehmen sollten, wollen sie den Einstieg in die Big-Data-Welt wagen.
2. Teil: „Wie wichtig sind Big Data und Analytics?“
Wie wichtig sind Big Data und Analytics?
„Daten sind das neue Gold“ heißt es heute häufig, oder auch „Daten sind das neue Öl“. Gemeint ist damit: Wer sich intensiv und in neuer Weise um die in seinem Unternehmen anfallenden Daten kümmert, dem eröffnen sich ganz neue Gewinnmöglichkeiten – wie beim kalifornischen Goldrausch im 19. Jahrhundert oder den riesigen Profiten der Erdölindustrie infolge des Autobooms. Bevor man solchen Äußerungen blind vertraut, sollte man sich allerdings fragen, inwieweit Daten tatsächlich das Kerngeschäft eines Unternehmens ausmachen oder doch nur Zusatzmaterial zu den klassischen Produkten und Dienstleistungen sind.

-


 Isilon-Speicher: Die Storage-Systeme skalieren von wenigen Terabyte bis zu mehreren Petabyte. Sie werden im Bundle mit Big-Data-Software von Pivotal verkauft.Quelle: EMC
Isilon-Speicher: Die Storage-Systeme skalieren von wenigen Terabyte bis zu mehreren Petabyte. Sie werden im Bundle mit Big-Data-Software von Pivotal verkauft.Quelle: EMC

Es sind, folgt man dem Bitkom-Verband und anderen Experten, in den letzten Jahren neue Methoden zur Datenfindung, -analyse und -aufbereitung entstanden, die die herkömmlichen Herangehensweisen von Data Warehouses und Business Intelligence (BI) ersetzen oder ergänzen.
KMUs, die sich ernsthaft mit dem Potenzial von Big Data und Analytics befassen wollen, müssen sich neben der Begriffsbestimmung um eine erste Bestandsanalyse kümmern: Welche Daten sind bisher mit welcher Zielrichtung erfasst worden? Was wurde übersehen? Welche Daten sind durch die Digitalisierung der Geschäftsprozesse, durch das Internet, den Einsatz mobiler Geräte und durch soziale Netze hinzugekommen, wurden aber noch nicht effektiv erfasst? Hilfreich kann in diesem Zusammenhang die Bitkom-Broschüre „Big Data im Praxiseinsatz – Szenarien, Beispiele, Effekte“ sein. Sie enthält auch Praxisbeispiele aus dem Mittelstand.
Sinnvoll ist es außerdem, bei Herstellern und Dienstleistern nach Referenzen zu fragen und mit deren CIOs und IT-Abteilungen direkten Kontakt aufzunehmen.
3. Teil: „Datenquellen für Big Data identifizieren“
Datenquellen für Big Data identifizieren
Forrester-Analyst Brian Hopkins empfiehlt, von den bestehenden Transaktionsdaten auszugehen. Diese seien für 66 Prozent der Entscheider nach wie vor die wesentliche Basis ihrer strategischen Überlegungen. Darüber hinaus sollten sich die Unternehmen um jene Daten kümmern, die sie noch gar nicht kennen.
-
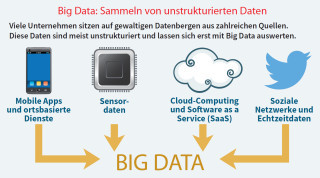
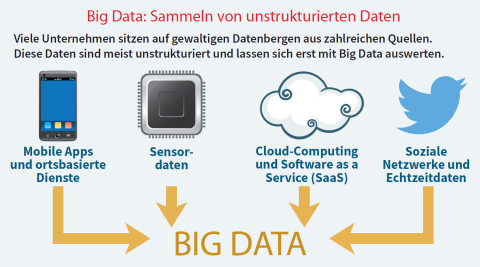
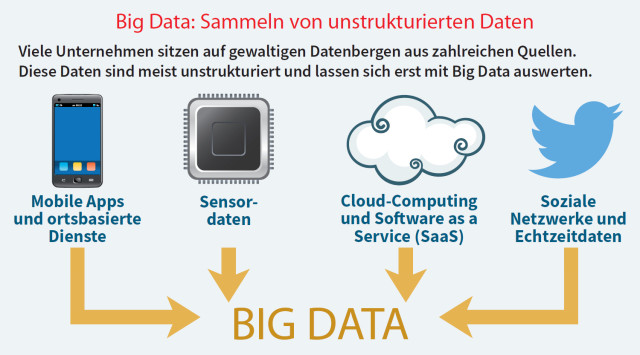 Big Data: Viele Unternehmen sitzen auf gewaltigen Datenbergen aus zahlreichen Quellen. Diese Daten sind meist unstrukturiert und lassen sich erst mit Big Data auswerten.Quelle: com! professional / Bitkom
Big Data: Viele Unternehmen sitzen auf gewaltigen Datenbergen aus zahlreichen Quellen. Diese Daten sind meist unstrukturiert und lassen sich erst mit Big Data auswerten.Quelle: com! professional / Bitkom
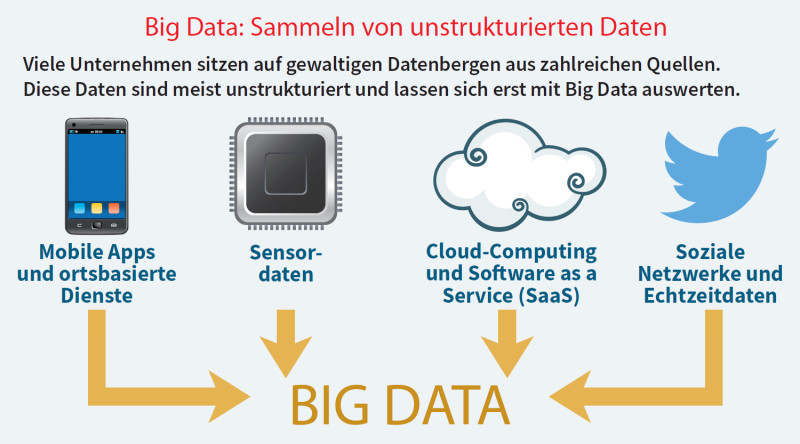
Mit dem Internet, den mobilen Aktivitäten, den Unmengen an Apps sowie den sozialen Netzwerken ist ein neuer Typus von Daten zu den bisherigen Applikationen hinzugekommen: Sie sind zum großen Teil unstrukturiert, da sie nicht nur aus den klassischen strukturierten Komponenten wie Name, Vorname, Beruf und so weiter bestehen, sondern aus E-Mail-Konvoluten oder Twitter-Kurztexten, aus Fotos, Videos oder ähnlichen Elementen.
Strukturierte Daten lassen sich relativ einfach in relationalen Datenbanken zeilen- und spaltenweise einfügen, sortieren und anschließend interpretieren. Zum Teil müssen sie aber zeit- und kostenaufwendig in eigene Applikationen eines Data Warehouses übertragen und zusammengeführt werden, um sie anschließend nach bestimmten Kriterien der Business Intelligence (BI) auszuwerten.
Strukturierte Daten lassen sich relativ einfach in relationalen Datenbanken zeilen- und spaltenweise einfügen, sortieren und anschließend interpretieren. Zum Teil müssen sie aber zeit- und kostenaufwendig in eigene Applikationen eines Data Warehouses übertragen und zusammengeführt werden, um sie anschließend nach bestimmten Kriterien der Business Intelligence (BI) auszuwerten.
Die seit Jahrzehnten aktiven Anbieter auf diesem Gebiet haben auf den Big-Data-Trend reagiert und ihre Angebote entsprechend erweitert und ergänzt.

Im Data Warehouse werden diese Informationen aus den unterschiedlichsten Quellen gesammelt, analysiert und schließlich dem Management der Airline zur Verfügung gestellt. Das ist auch heute noch ein Prozess, bei dem es nicht auf Stunden oder Minuten ankommt (anders als bei aktuellen Analytics-Verfahren im Einzelhandel oder im Bankwesen).
Ein kleines oder mittleres Unternehmen sollte sich genau fragen, ob es alle seine Datenquellen kennt, sie wirklich benutzen will – und welche Methoden zur Analyse bereitstehen. Ferner muss es entscheiden, ob der BI- oder der Big-Data-Ansatz zunächst getestet werden soll, um ihn vielleicht später real einzusetzen.
Forrester Research empfiehlt, eine Roadmap zu entwerfen und dabei drei Aspekte zu beachten: Erstens sollten Firmen eine datenfokussierte Unternehmenskultur aufbauen. Der Grund ist, dass quantitative Informationen heute wichtiger sind als subjektive Erfahrungen oder Meinungen. In vielen Unternehmen denken die Mitarbeiter jedoch noch zu sehr in Kategorien wie „meine Abteilung“ und geben Informationen nicht weiter. Zweitens sollten sie geschäftliches Know-how und Management-Methoden („Governance“) für die Datenanalyse entwickeln – noch vor technischen Kenntnissen in Big-Data-Architekturen. Und drittens sollte man sich frühzeitig mit neuen Technologien wie der Datenmanagement-Plattform Hadoop befassen.
4. Teil: „Big Data zunächst einmal in der Cloud testen“
Big Data zunächst einmal in der Cloud testen
Der Bitkom-Verband empfiehlt, sich bei der Entwicklung und Umsetzung von Big-Data-Projekten an einem Vorgehensmodell zu orientieren. Ein solches Modell begleitet alle Schritte und Prozesse – etwa den ITIL-Projekten entsprechend (Information Technology Infrastructure Library; allgemein anerkannte Richtlinien für das IT-Service-Management). Transparenz und Nachvollziehbarkeit ermöglichen laut Bitkom, jederzeit eine Kosten- und Effektivitätskontrolle (Return on Investment, RoI) durchzuführen oder ein einmal begonnenes Projekt rechtzeitig wieder abzubrechen.
-
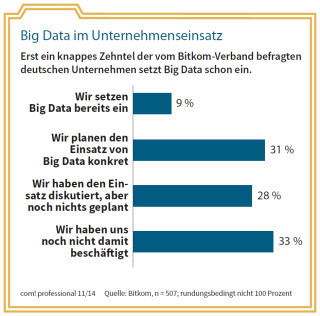
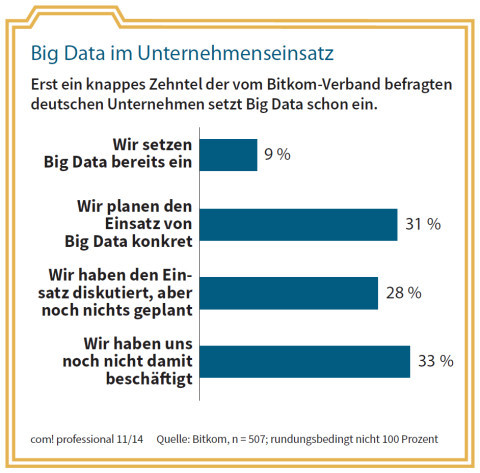
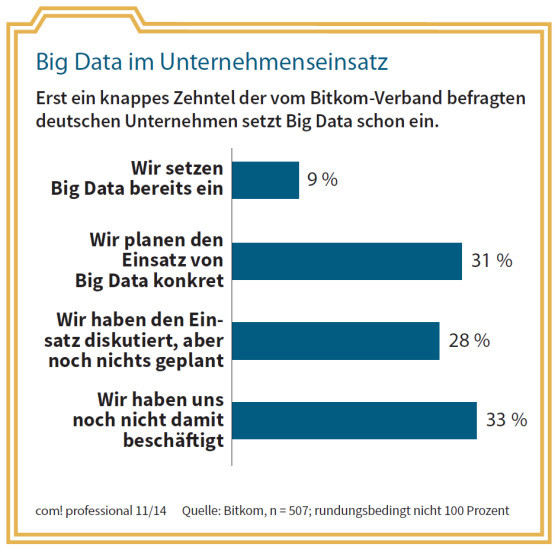
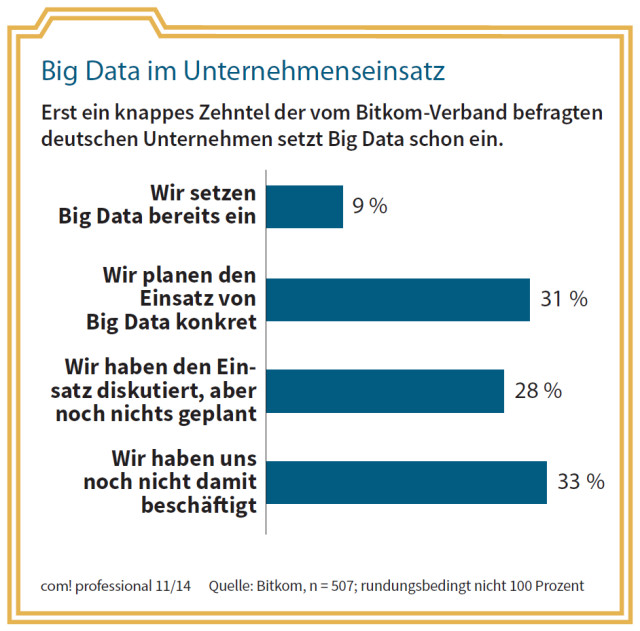 Big Data im Unternehmenseinsatz: Erst ein knappes Zehntel der vom Bitkom-Verband befragten deutschen Unternehmen setzt Big Data schon ein.Quelle: com! professional / Bitkom
Big Data im Unternehmenseinsatz: Erst ein knappes Zehntel der vom Bitkom-Verband befragten deutschen Unternehmen setzt Big Data schon ein.Quelle: com! professional / Bitkom
Um diese Phasen allmählich anzugehen, sollte man sich mit Cloud-Prozeduren vertraut machen. Amazon Web Services (AWS), Microsoft Azure und lokale Cloud-Provider bieten neben der Speicherung der Daten inzwischen auch Analysewerkzeuge an – bei Microsoft zum Beispiel in Abstimmung mit den bisher im Unternehmen eingesetzten Datenwerkzeugen wie Excel oder SharePoint. Ein Service-Provider wie Accenture bietet darüber hinaus Brokering-Dienstleistungen für die Suche und Anwendung geeigneter Cloud-Lösungen an.
Big Data in mehreren Phasen
Der Bitkom-Verband schlagt mehrere Stufen vor, wenn ein Unternehmen ein eigenes Big-Data-Projekt in Angriff nehmen will. Zum Einstieg in echte Big-Data-Analysen gehören:
- Assessment: Potenziale für den Einsatz von Big-Data-Methoden erkennen und sich Klarheit über die Nutzung entsprechender Daten verschaffen.
- Readiness: Unternehmen jeder Größe müssen die erforderliche Hardware- und Software-Infrastruktur und entsprechende Kompetenzen aufbauen.
- Implementierung und Integration: Werden neue Infrastruktur-Komponenten für die Datenanalyse aufgebaut, sollten sie mit der bisher vorhandenen IT verbunden werden. Nur so lassen sich alle Datenquellen gemeinsam erschliesen.
- Reporting und Predictive Analytics: Die neuen Daten und daraus abgeleitete Erkenntnisse bilden die Basis für die Optimierung der Reporting-Prozesse, auch in Echtzeit. Eventuell können schon Prognosen für zukünftige Trends erstellt werden.
5. Teil: „Vorgefertigte Lösungen der Big-Data-Protagonisten“
Vorgefertigte Lösungen der Big-Data-Protagonisten
Fragt man EMC, den Marktführer im Speicherbereich und über das Tochterunternehmen Pivotal einer der größten Big-Data-Protagonisten, nach speziellen Angeboten für KMUs, erhält man eine ausweichende Antwort: Dedizierte Lösungen für kleinere Unternehmen gebe es nicht. Allerdings skalierten die Isilon-Speicher, die besonders für unstrukturierte Daten geeignet sind, laut einem EMC-Sprecher „von wenigen Terabyte (mindestens drei Knoten) bis zu mehreren Petabyte (maximal 144 Knoten)“. KMUs könnten somit klein einsteigen und bei Bedarf das Speichervolumen sukzessive erweitern.
-
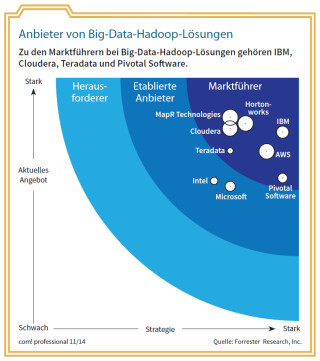
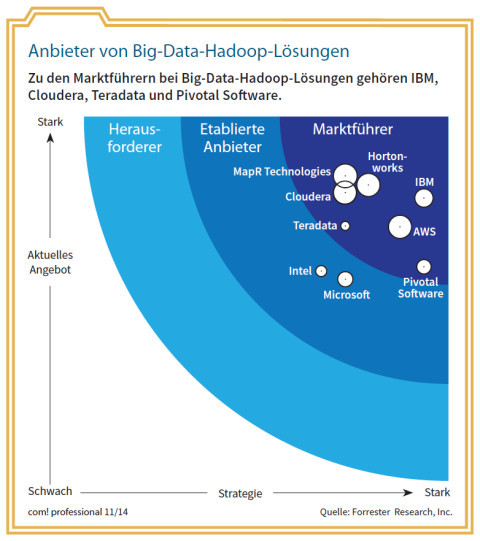
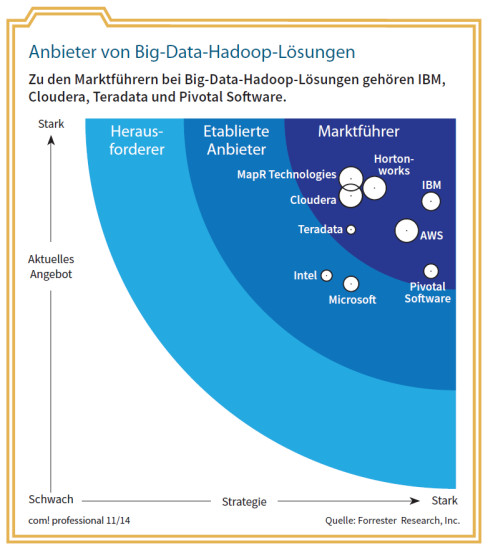
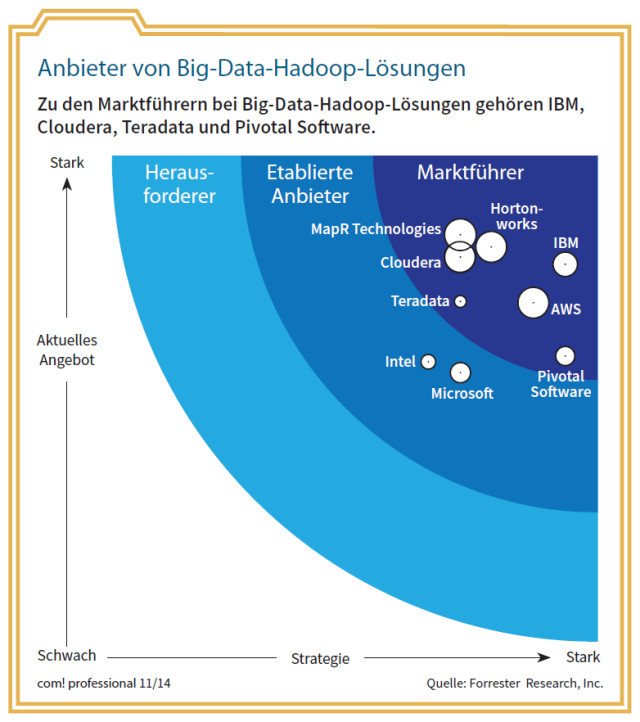 Anbieter von Big-Data-Hadoop-Lösungen: Zu den Marktführern bei Big-Data-Hadoop-Lösungen gehören IBM, Cloudera, Teradata und Pivotal Software.Quelle: com! professional / Forrester Research
Anbieter von Big-Data-Hadoop-Lösungen: Zu den Marktführern bei Big-Data-Hadoop-Lösungen gehören IBM, Cloudera, Teradata und Pivotal Software.Quelle: com! professional / Forrester Research
Pivotal spricht von einem „Business Data Lake“, in dem unterschiedlich strukturierte Daten aus diversen Quellen zusammenlaufen, ähnlich dem, was traditionell mit Data Warehouse bezeichnet wird. Im Juli 2014 hat dann EMC mit „Data Lake Hadoop“ ein weiteres Bundle vorgestellt, in dem die Software-Tools von Pivotal mit Scale-out-Speicher von EMC/Isilon zusammen vermarktet werden. Insbesondere die Subskriptionslösung könnte für solche mittelständischen Unternehmen interessant sein, die ein starkes Datenwachstum zu verzeichnen haben.
KMUs beziehungsweise SMBs (Small and Medium Businesses) sind seit Jahren Schlagwörter, ohne die kaum eine Marketingkampagne oder ein größerer Event auskommt. So auch bei Hewlett-Packard (HP). Der Hersteller verweist immer wieder auf seine Verbundenheit mit dem Mittelstand und das große Partnernetz, das man gerade in Deutschland aufgebaut habe, um nahe an den KMUs und den lokalen Gegebenheiten dran zu sein. Erst im Januar dieses Jahres wurden der Ausbau des „Just Right IT Port-folios für SMB-Kunden“ und die „HP Flex-Bundles“ vorgestellt. Diese Bundles sehen vorgefertigte Referenz-Architekturen für Microsoft Hyper-V, VMware vSphere mit Operations Management, Microsoft Exchange Server 2013 und für SAP HANA vor. Den SMB-Unternehmen könne so „zum richtigen Zeitpunkt die richtige IT-Lösung“ geliefert werden.
Im Rahmen von Converged Systems bietet HP „Big-Data-Analysen mit Warp-Geschwindigkeit“ an. Das neue HP Converged System 300 für die Software Vertica mache „aus der HP-Strategie für Big Data ein Produkt, das für eine erweiterte Analyse Hardware, Software, Services und Consulting vereint“.
-


 „KMUs haben die Bedeutung von Big Data noch nicht klar erkannt.“ - Tom Joyce, Vice President für Converged Systems bei Hewlett-Packard, www.hp.com
„KMUs haben die Bedeutung von Big Data noch nicht klar erkannt.“ - Tom Joyce, Vice President für Converged Systems bei Hewlett-Packard, www.hp.com

Etwas anders äußerte sich Tom Joyce, Senior Vice President für Converged Systems bei HP, noch im Dezember 2013 auf der Kundenveranstaltung HP Discover in Barcelona: „KMUs haben die Bedeutung von Big Data noch nicht klar erkannt. Sie sind noch nicht fokussiert auf solche Sachen wie Virtualisierung, Cloud oder Big Data. Das könnte sich in Zukunft ändern, wenn es gelingt, diese Technologien in ähnlicher Weise in leicht zu bedienende Appliances zu packen, wie es heute schon mit Firewalls üblich ist. Ich glaube, die meisten KMUs wollen Lösungen in einer Box, die von selbst laufen. Es ist unsere Aufgabe, diese Technologien einfacher zu machen.“
Fast alle großen Hersteller bieten heute Lösungen mit dem Label „Big Data“ an. Interessierte Unternehmen sollten sehr genau prüfen, was Dell, Fujitsu, Netapp, Oracle oder SAP für ihre spezifischen Bedürfnisse anzubieten haben. So sind zum Beispiel In-Memory- oder HANA-Lösungen und -Appliances nicht automatisch geeignete Werkzeuge für Big Data und Analytics, sondern sorgen lediglich für eine (oft wünschenswerte) Beschleunigung von Applikationen und In-/Output-Prozessen für Daten.
6. Teil: „Open Source und integrierte Umgebungen“
Open Source und integrierte Umgebungen
Während die klassischen Data-Warehouse- und BI-Lösungen immer schon mit dem Ruf zu kämpfen hatten, kompliziert, supportabhängig und teuer zu sein, sind mit den Open-Source-Angeboten rund um die Hadoop-Technologie preisgünstige Alternativen entstanden. Wie bei aller Open-Source-IT treten jedoch auch hier Anbieter auf den Plan, die zusätzliche Service-Leistungen bieten und sich diese dann extra bezahlen lassen. Zu nennen sind in diesem Zusammenhang Cloudera, Horton Works, MapR Technologies oder Pivotal Software.

In dem Report „The Forrester Wave: Big Data Hadoop Solutions, Q1 2014“ vom Februar 2014 schreiben die Forrester-Analysten Mike Gualtieri und Noel Yuhanna: „Hadoop ist heute die wirklich heiße Plattform für Datenmanagement. Und zwar aus folgenden Gründen: Erstens bietet sie günstigere Speichermöglichkeiten als traditionelle Systeme. Zweitens beruht sie auf echten Open-Source-Neuerungen. Drittens skaliert sie ohne Probleme, da ihr verteiltes Dateisystem das Weiterleiten und Speichern großer Datenmengen unterstützt. Viertens hat Hadoop vielen Unternehmen die Augen geöffnet für die Möglichkeiten und Gewinne , die in ihren Daten schlummern.“
Hadoop hat damit bereits die Grenze vom puren Hype zum ernsthaften Trend überschritten.
Integrierte Umgebungen

Gartner zählt zu den Stärken von Teradata die Kundenbasis von mehr als 1200 großen Unternehmen, die trotz der vergleichsweise hohen Kosten bisher nicht gebröckelt sei, und die Fähigkeit, sich kontinuierlich an neue Entwicklungen wie Hadoop oder In-Memory-Prozesse anzupassen. Allerdings sei der Druck durch neue Konkurrenten stärker geworden. Besonders kritisch könnte es für Teradata aber werden, wenn große Unternehmen wie IBM, Oracle oder SAP damit beginnen, transaktionale und analytische Prozesse in einer gemeinsamen Datenbasis durchzuführen.
7. Teil: „Hadoop und die die Apache Software Foundation“
Hadoop und die die Apache Software Foundation
Es lohnt sich also, sich auf die Erkundung des Open-Source-Terrains für Hadoop-Lösungen einzulassen, wenn selbst Marktführer wie Teradata und andere sich dafür geöffnet haben.
Man muss sich dabei darüber im Klaren sein, woher der Hadoop-Ansatz eigentlich stammt. Alle großen Internetfirmen wie Amazon, Facebook, Google oder Yahoo waren damit konfrontiert, ihre tagtäglich und stündlich hereinströmenden Datenmengen zu erfassen und zu verarbeiten.
-


 Bestandteile von Big Data: Vier Bereiche prägen Big Data: Datenmenge und -vielfalt, Geschwindigkeit der Datenübertragung und Analyse der Informationen.Quelle: com! professional / Bitkom
Bestandteile von Big Data: Vier Bereiche prägen Big Data: Datenmenge und -vielfalt, Geschwindigkeit der Datenübertragung und Analyse der Informationen.Quelle: com! professional / Bitkom

Der Anstoß zu Neuentwicklungen kam daher von diesen Internetunternehmen, die schon bei der Hardware-Ausstattung ihrer Rechenzentren auf kostengünstige Standard- und Speichergeräte gesetzt hatten. Die Entwicklung durch eine Community von Softwarespezialisten ermöglichte darüber hinaus, die Applikationen in unterschiedlichen Unternehmen einzusetzen, zu testen und zu verbessern. Um die Professionalität und Unabhängigkeit der Software-Entwicklung zu gewährleisten, kam es zu verschiedenen Ausgründungen, die dem gesamten Markt zur Verfügung stehen sollten. So ist der Hadoop-Spezialist Horton Works aus Yahoo hervorgegangen.
Die Entwicklung von Hadoop wird durch die Apache Software Foundation und ihre Mitglieder vorangetrieben. Hadoop ist heute schon fast ein Synonym für Big Data geworden, weil es Applikationen auf großen Clustern von Standard-Hardware eine kontinuierliche Scale-out-Architektur zur Verfügung stellt. Hadoop benutzt dabei einen Algorithmus namens Map-Reduce, der eine Applikation in viele kleine Fragmente unterteilt, die auf jedem beliebigen Cluster-Node lauffähig sind.
Zusätzlich bietet Hadoop das verteilte File-System HDFS (Hadoop Distributed File System), das Daten auf den Netzknoten speichert und über eine große Bandbreite verfügt. Map-Reduce und HDFS sind beide in der Lage, beim Crash einzelner Nodes automatisch die Daten über das Netzwerk zu verteilen.
Im Rahmen der Hadoop-Umgebung gibt es zahlreiche weitere interessante Tools, zum Beispiel die Programmiersprache R für statistische Zwecke, die ebenfalls frei verfügbar ist, oder Visualierungssoftware für die Performance von Algorithmen (Confusion Matrix).
Spezialisten im eigenen Haus
Man muss nicht gleich seltene (und teure) Datenanalyse-Spezialisten anheuern, um Big-Data- und Analytics-Verfahren sinnvoll einzusetzen. Es geht auch anders: indem man zunächst einen oder mehrere IT-Mitarbeiter auf Fortbildungsveranstaltungen schickt oder – noch günstiger – ihnen Zeit für die Beschäftigung mit den zahlreichen Kursen gibt, die inzwischen im Internet zu Big Data angeboten werden.
Nicht übersehen sollte man dabei, dass spezielle Fachkenntnisse bei der Anwendung von Big-Data-Technologien mit der Zeit weniger nötig sein werden, da die Anbieter immer mehr Automatisierung in ihre Programme hineinpacken – etwa nach dem Vorbild von Firewall-Appliances, die inzwischen für Implementierung und Anwendung auch kein Expertenwissen in Sachen Security mehr voraussetzen.
8. Teil: „Big Data als Mainstream-Technologie für KMUs“
Big Data als Mainstream-Technologie für KMUs
Datenanalyse-Spezialisten wird man sicher noch eine Weile brauchen, um tatsächlich alle Vorteile aus Big-Data- und Analytics-Lösungen zu schöpfen. Doch die Entwicklung hin zu einer Mainstream-Technologie ist nicht mehr aufzuhalten.
-


 Big Data und Analytics: Die Entwicklung hin zu einer Mainstream-Technologie ist nicht mehr aufzuhalten.Quelle: sorbetto / Stockphoto
Big Data und Analytics: Die Entwicklung hin zu einer Mainstream-Technologie ist nicht mehr aufzuhalten.Quelle: sorbetto / Stockphoto

Excel-Spreadsheets sind das natürliche Ausgangsmaterial für fast alle traditionellen und neueren Methoden der Datensammlung und -analyse. Mit aufgefrischten Excel-Kenntnissen können Unternehmen einen Schritt vorwärts gehen in Richtung Analytics. Hinzu kommen sollten aber weitere Funktionen aus professionellen BI-Programmen, die in der Regel über ein größeres Tool-Set und mehr Möglichkeiten für die Datenintegration verfügen. Allein für die Visualisierung der Big-Data-Ergebnisse gibt es heute neben Tableau eine ganze Reihe von Tools – darunter Chartio, iCharts, Qlik oder Good Data. Tableau bietet sogar eine kostenlose Einsteigerversion an.
Alle diese Wege zu mehr Big-Data-Know-how stehen nicht nur den Großen zur Verfügung. Kleine und mittlere Unternehmen können sogar mehr Nutzen daraus ziehen, weil ihre IT-Mannschaften nicht so bürokratisch eingeengt sind. Außerdem gibt es genügend Open-Source-Enthusiasten auf dem (Arbeits-)Markt.
Weitere Infos
- Big-Data-Analysen mit Google Cloud Dataflow,
Dr. Thomas Hafen, com! professional 11/2014 - Q & A: The Top Five Strategic Big Data Questions,
Brian Hopkins u.a.; Forrester Research Juli 2014 - Big Data und Recht, Thomas Hoeren (Hrsg.);
C.H. Beck, ISBN 978-3-406-6711-7
Huawei Roadshow 2024
Technologie auf Rädern - der Show-Truck von Huawei ist unterwegs
Die Huawei Europe Enterprise Roadshow läuft dieses Jahr unter dem Thema "Digital & Green: Accelerate Industrial Intelligence". Im Show-Truck zeigt das Unternehmen neueste Produkte und Lösungen. Ziel ist es, Kunden und Partner zusammenzubringen.
>>
Nach der Unify-Übernahme
Mitels kombinierte Portfoliostrategie
Der UCC-Spezialist Mitel bereinigt nach der Unify-Übernahme sein Portfolio – und möchte sich auf die Bereiche Hybrid Cloud-Anwendungen, Integrationsmöglichkeiten in vertikalen Branchen sowie auf den DECT-Bereich konzentrieren.
>>
Umweltschutz
Netcloud erhält ISO 14001 Zertifizierung für Umweltmanagement
Das Schweizer ICT-Unternehmen Netcloud hat sich erstmalig im Rahmen eines Audits nach ISO 14001 zertifizieren lassen. Die ISO-Zertifizierung erkennt an wenn Unternehmen sich nachhaltigen Geschäftspraktiken verpflichten.
>>
Cyberbedrohungen überall
IT-Sicherheit unter der Lupe
Cybersecurity ist essentiell in der IT-Planung, doch Prioritätenkonflikte und die Vielfalt der Aufgaben limitieren oft die Umsetzung. Das größte Sicherheitsrisiko bleibt der Mensch.
>>