06.04.2020
Erklärbare KI
1. Teil: „Verständnis schafft Vertrauen und Akzeptanz“
Verständnis schafft Vertrauen und Akzeptanz
Autor: Andreas Dumont



bestfoto77 / shutterstock.com
Transparente Algorithmen fördern die Umsetzung von KI-Projekten in Unternehmen. Verstehen die Mitarbeiter die Technologie, zeigen sie auch mehr Vertrauen und Akzeptanz der KI gegenüber.
Auf fast magische Weise liefern Machine Learning und Deep Learning beeindruckende Ergebnisse. Das Problem: Wie bei guten Zaubertricks steht das Publikum staunend davor und weiß nicht, wie ihm geschieht. Was bei einem Magier den Reiz ausmacht, sorgt bei Künstlicher Intelligenz für einen eklatanten Mangel an Vertrauen, da Verzerrungen, Überanpassungen oder Fehler in den Modellen nicht erkannt werden können. Blackbox-Modelle werden mit Daten gefüttert, verarbeiten diese mit Algorithmen und spucken am Ende ein Ergebnis aus. Wie vertrauenswürdig, diskriminierend oder fehlerhaft der Output ist, kann niemand beurteilen. Der Blackbox-Ansatz macht es zudem schwierig bis unmöglich, Vorschriften wie die DSGVO einzuhalten.
Der Ansatz einer erklärbaren KI sucht demgegenüber nach Möglichkeiten, die Arbeitsweise von KI-Implementierungen nachvollziehbar zu machen und ein Verständnis für die Funktionsweise zu ermöglichen. Um das volle Potenzial von KI und ML auszuschöpfen, ist Vertrauen in die Abläufe der komplexen Algorithmen unbedingt notwendig. Menschen wollen verstehen, wie eine KI ihre Entscheidungen fällt.
Algorithmische Entscheidungssysteme (ADM) verwenden Algorithmen an zwei Stellen: Der erste Algorithmus lernt auf Basis der Daten ein statistisches Modell. Das statistische Modell ist dann die Grundlage für den zweiten Algorithmus, der die eigentliche Entscheidung berechnet.
Fehlerquellen, Fehlurteile
Künstliche Intelligenz ist gegen Fehler nicht gefeit und lässt sich mitunter leicht manipulieren. Die Auswirkungen sind im Voraus nicht absehbar. So entwickelte Microsoft den Chatbot Tay, der aus Konversationen lernen und das Gelernte in weiteren Chats anwenden können sollte. Doch schon nach kurzer Zeit war Tays Sprache von Rassismus und Sexismus durchsetzt. Ursache waren mehrere Benutzer, die den Chatbot durch entsprechende Konversationen manipulierten. Als Tay schließlich Völkermord befürwortete, wurde das Experiment abgebrochen.
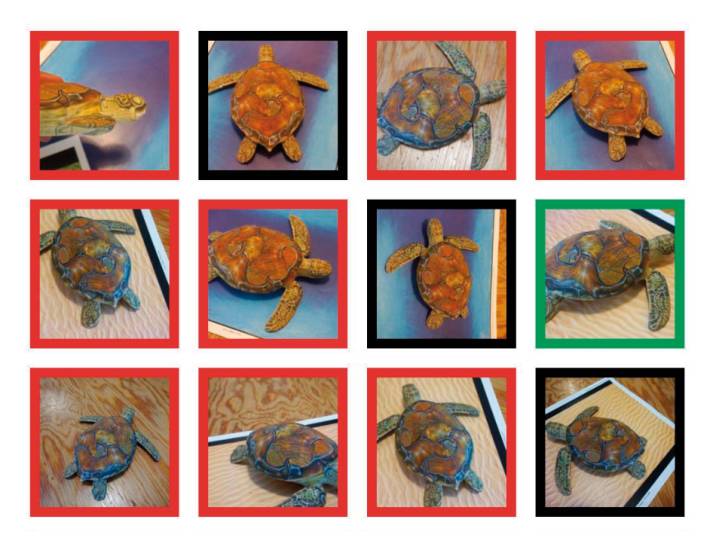
Ein anderes Beispiel betrifft die Bilderkennung: Wissenschaftler vom MIT in Massachusetts haben mit einem 3D-Drucker Schildkröten hergestellt, um zu zeigen, wie anfällig Bilderkennungssysteme sind. Die KI von Google hielt die meisten Schildkröten mit einer Wahrscheinlichkeit von 90 Prozent für ein Gewehr. Japanische Wissenschaftler von der Universität Kyushu haben gezeigt, dass es genügt, eine Handvoll Pixel in einem Bild zu verändern, um die Algorithmen komplett zu verwirren.
Für Fehlurteile von ADM-Systemen sind in erster Linie drei Faktoren verantwortlich. Da ist zunächst der Zufall. Der zweite Faktor sind zu kleine, inhomogene oder falsch gewichtete Datenmengen. Und schließlich können Fehlurteile auch aus einem fehlerhaft entwickelten ADM-System resultieren oder aus einer Fehlinterpretation der gelieferten Resultate.
Fehlerhaftes Design der verwendeten Modelle, die Wahl falscher oder ungeeigneter Methoden sowie das falsche Bedienen der Modelle sind offensichtliche Probleme. Aber auch das - absichtliche oder unabsichtliche - falsche Trainieren der Modelle kann zu Verzerrungseffekten (Bias) und Überanpassungen (Overfitting) führen. „Nicht zuletzt die Korrektheit, Vollständigkeit, Aktualität und Fehlerfreiheit der verwendeten Daten sind entscheidend für die Qualität der Modellergebnisse“, erklärt Konstantin Greger, Solution Consultant mit Schwerpunkt Datenvisualisierung und Reporting beim Business-Intelligence- und Analytics-Spezialisten Tableau Software. Kay Knoche, Principal Solution Consultant beim Software-Hersteller Pegasystems, konstatiert: „Wenn Algorithmen mit unzureichenden oder falschen Trainingsdaten gefüttert werden oder sich an falschen Geschäftszielen orientieren, kommt es zu Entscheidungen, die nicht zielführend sind.“
Julian Mehne ist Data Scientist beim IT-Dienstleister und Software-Entwickler DoubleSlash Net-Business. Er sieht den Grund für Bias darin, dass KI-Modelle oft als in sich geschlossene Systeme betrachtet werden, obwohl sie später meist in einer komplexen Umgebung genutzt werden. Das könne dazu führen, dass die gesammelten Daten nicht repräsentativ für den späteren Einsatzzweck des KI-Modells seien oder dass das KI-Modell ungewollt bestimmte Individuen benachteilige. „Viele dieser Effekte sind alles andere als offensichtlich.“
Auch nach Überzeugung von Kathy Baxter, Archi- tect of Ethical AI Practice bei Salesforce, sind verzerrte Trainingsdaten die häufigste und folgenschwerste Ursache für Fehlurteile. Falsche Annahmen über den Kontext, in dem KI-Empfehlungen genutzt werden, könnten ebenfalls zu Fehlern führen.
2. Teil: „Erklärbare KI“
Erklärbare KI
-
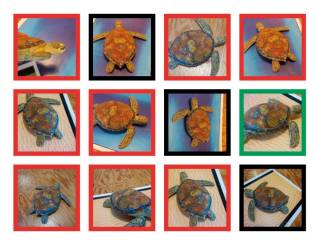
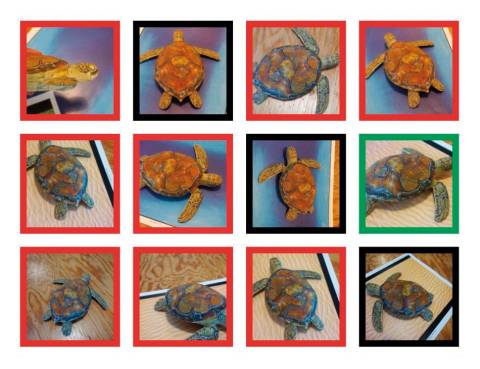
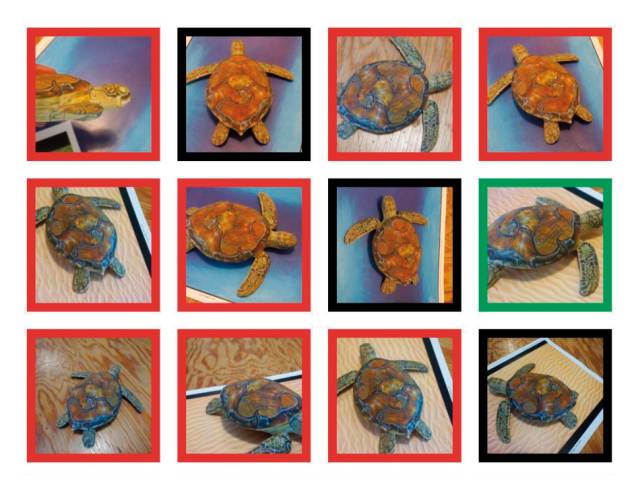 Künstliche Intelligenz von Google irrt sich: Die rot umrandeten Schildkröten hält die Bilderkennungs-KI für Gewehre.Quelle:LabSIX/MIT
Künstliche Intelligenz von Google irrt sich: Die rot umrandeten Schildkröten hält die Bilderkennungs-KI für Gewehre.Quelle:LabSIX/MIT
Nachdem Google den Algorithmus für den PageRank, einen besonders wichtigen Indikator für das Google-Ranking von Webseiten, veröffentlicht hatte, haben viele das ausgenutzt, um sich einen höheren Rank zu ergaunern. Außerdem wusste die Konkurrenz sogleich, wie sie die eigenen Suchmaschinen verbessern konnte.
Konstantin Greger betont: „Künstliche Intelligenz und Machine Learning wecken die Erwartung, dass Maschinen dem Menschen durch automatisierte Entscheidungen zu besseren Erkenntnissen verhelfen. Entscheider stellen sich aber immer häufiger die Frage: Wie können wir sicherstellen, dass automatische Empfehlungen und Modelle vertrauenswürdig sind?“ Die Algorithmen und Logiken, auf denen Entscheidungen und Empfehlungen beruhen, seien bei vielen Machine-Learning-Anwendungen nicht nachvollziehbar. Explainable AI (XAI) solle dabei helfen, diese Prozesse transparenter zu machen.
Julian Mehne definiert es so: „Explainable AI beschreibt eine Erwartungshaltung, zu verstehen, wie ein KI-Modell funktioniert, oder zumindest die Möglichkeit, eine getroffene Entscheidung nachträglich logisch nachvollziehen zu können.“
„Ein Beispiel für XAI ist Common-Sense-Reasoning bei der natürlichen Sprachverarbeitung“, sagt Kathy Baxter. „Zwar sehen wir große Fortschritte bei trainierten Sprachmodellen. Jedoch verfügen diese Systeme nicht über das intuitive, allgemeine Verständnis und die Zusammenhänge der realen Welt, die für einen Menschen selbstverständlich sind und gemeinhin als Common Sense, also gesunder Menschenverstand beschrieben werden. Bei Salesforce Research wurden deshalb Erklärmodelle genutzt, um dieses Common-Sense-Reasoning in ein Deep-Learning-Modell zu integrieren. Dabei wurde nachgewiesen, dass das Verfahren die Genauigkeit der zuvor NLP-basierten Vorhersagen um 10 Prozent steigert.“ Auf diese Weise trage Explainable AI nicht nur zum Vertrauen der Anwender, sondern auch zu einer besseren Leistungsfähigkeit der Technologien an sich bei.
3. Teil: „XAI im Unternehmen“
XAI im Unternehmen
-
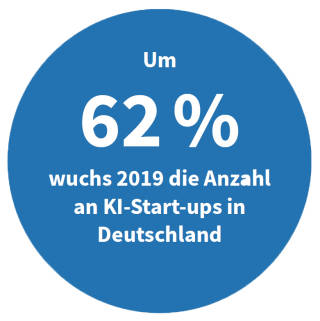
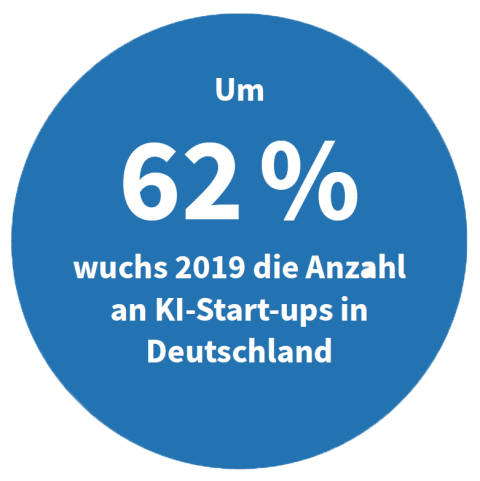
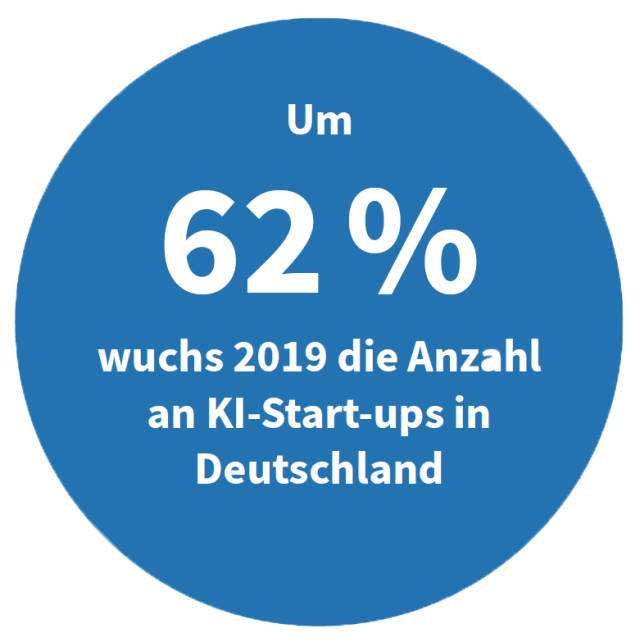 Quelle:Applied AI
Quelle:Applied AI

Tableau verwende KI und Machine Learning, um mit Funktionen wie „Ask Data“ und „Explain Data“ mehr Menschen den Zugang zu Daten und Analysen zu ermöglichen, erklärt Konstantin Greger. „Nur wenn Entscheider sich auf Lösungsvorschläge aus vertrauenswürdigen Daten und Prozessen verlassen können, haben intelligente Anwendungen einen echten Mehrwert für die Unternehmen.“
Salesforce-Managerin Kathy Baxter ergänzt: „In regulierten Branchen wird es nötig sein zu beweisen, dass ein solches System mit den Gesetzen und Regularien in Einklang steht. Auch weltweit gibt es immer mehr Bestrebungen für die Regulierung von KI, die eine entsprechende Erklärbarkeit erfordern, vor allem in Hochrisiko-Anwendungen.“
Marco Peisker, Branch Manager beim IT-Dienstleister Adesso, spricht XAI auch aus Effizienzgründen eine Daseinsberechtigung zu. „Ein Beispiel ist die Erkennung von Versicherungsbetrug: Die Maschine hat einen Versicherungsfall als Betrug erkannt und entsprechend ausgesteuert. Ohne die Erklärung für die Entscheidungsgründe müssen die internen Spezialisten den gesamten Schadensfall inklusive der Historie des Versicherungsvertrags, die beteiligten Parteien und Dienstleister, die Schadensumstände und vieles mehr komplett durchleuchten, um den Fall ebenfalls bewerten zu können. Liefert die KI jedoch gleich die Begründung für die Entscheidung mit, entfallen eine Vielzahl manueller Aktivitäten und es wird eine echte Effizienz über den gesamten Prozess erreicht. Aus betriebswirtschaftlicher Sicht sollte die Erklärbarkeit der KI also immer mitbetrachtet werden.“
4. Teil: „Blick in die Blackbox“
Blick in die Blackbox
Das Fraunhofer Heinrich-Hertz-Institut in Berlin entwickelt zusammen mit der Technischen Universität Berlin eine Art Gehirnscan für KI. Das Verfahren nennt sich Layer-wise Relevance Propagation (LRP). Vereinfacht gesagt lässt LRP den Denkprozess einer KI rückwärtslaufen. So wird nachvollziehbar, welcher Teil des Inputs welchen Einfluss auf das Ergebnis hatte. Mit einem Werkzeug wie LRP ließe sich also überprüfen, wie eine KI im Einzelfall zu einer medizinischen Diagnose oder einer Risikobewertung gekommen ist. In neuronalen Netzen betrachtet LRP die einzelnen Entscheidungsprozesse schichtweise rückwärts und berechnet, welche „Neuronen“ welche Entscheidungen getroffen haben und welche Relevanz diese für das Endergebnis hatten. Visualisieren lässt sich das Ganze mit einer Heatmap. Diese Methode, Ergebnisse neuronaler Netze nachträglich interpretierbar zu machen, lässt sich nicht nur in der Bilderkennung, sondern universell einsetzen.
„Deep-Learning-Modelle sind von Haus aus zunächst einmal nicht interpretierbar“, führt Kathy Baxter aus. „Deshalb wurden verschiedene Methoden entwickelt, damit diese Modelle eine Art Erklärung oder Begründung für ihre Vorhersagen liefern können.“ Eine Methode sei es, diejenigen Eigenschaften zu betrachten, die entscheidend für eine Vorhersage sind, wie etwa bei Layer-wise Relevance Propagation (LRP) oder Saliency Maps. Damit lässt sich in neuronalen Netzen zum Beispiel kontrollieren, ob die richtigen Regionen im Bild für die Klassifizierung verwendet werden. Dafür werden die Saliency Maps als Maske über das Eingabebild gelegt. Sollte eine nicht relevante Region markiert werden, deutet dies auf Fehler im neuronalen Netz hin.
„Die Bestimmung der einflussreichsten Trainingsbeispiele ist ein weiterer Weg, um die Vorhersagen zu erklären. So wird ein neuronales Netz eine Katze auf einem Bild erkennen, weil es den Trainingsdaten mit dem Label „Katze“ am meisten ähnelt.“ Die Beseitigung von Alternativen könne eine weitere Form der Erklärung für Vorhersagen mit mehreren Möglichkeiten sein. So würde ein neuronales Netz ein „Flugzeug“ erkennen, weil es Beweise gebe, die die alternative Möglichkeit „Vogel“ ausschließen. Der Einsatz eines weiteren Modells zur Validierung der ursprünglichen Vorhersage ist eine weitere Methode für XAI.
Marco Peisker von Adesso kennt eine Vielzahl von XAI-Ansätzen und hält zwei Methoden für besonders relevant: LIME und Anchors. „Bei diesen Methoden handelt es sich um Modell-agnostische Verfahren, die sich in einer Vielzahl von Modellen des maschinellen Lernens anwenden lassen. Indem bei LIME die Eingangsdaten der KI iterativ verändert werden, können aus der Beobachtung der Auswirkungen auf die Ausgangswerte Aussagen zum Verhalten des Systems getroffen werden.“ Das Ergebnis erlaube dem menschlichen Bearbeiter so eine einfache Interpretation.
Bei Anchors wird versucht herauszufinden, welche Features eines Datensatzes sich nicht ändern dürfen, damit die Vorhersage gleich bleibt.
Pegasystems biete „Guardrails for Responsible AI“, erläutert Kay Knoche. „Damit können abhängig vom Geschäftsbereich eines Unternehmens Schwellenwerte für Transparenz eingestellt werden.“ Das stelle sicher, dass etwa in sensiblen Bereichen nur transparente Algorithmen zum Einsatz kommen. „Das verständliche Bedürfnis nach transparenter KI bedeutet aber nicht, dass sie per se die bessere KI ist, denn intransparente KI kann zutreffendere Ergebnisse liefern - ganz einfach deshalb, weil sie in den Methoden und Entscheidungskriterien, die sie verwendet, nicht eingeschränkt wird.“ Deshalb gelte es beim Einsatz von KI immer abzuwägen, was im konkreten Fall schwerer wiege: die möglicherweise besseren Ergebnisse oder die Erklärbarkeit der KI.
Erklärbare KI und DSGVO
Die Datenschutz-Grundverordnung (DSGVO)hat zur Folge, dass sich Unternehmen intensiv damit befassen müssen, wie sie mit Daten umgehen. Das legt die Grundlage für ein transparentes Datenmanagement und somit auch für erklärbare KI. Ethische Aspekte werden ebenfalls immer wichtiger. „Die EU-Kommission hat im Frühjahr letzten Jahres Ethik-Richtlinien für die Entwicklung und Anwendung von KI in Europa vorgelegt“, weiß Konstantin Greger von Tableau. Er betont, dass der gesamte Lebenszyklus der Daten hinterfragt werden müsse: von der ersten Erfassung über die Bearbeitung bis hin zur Analyse. So lasse sich einerseits die komplette Datenmanagement-Strategie durchleuchten und zudem die Einhaltung gesetzlicher Regelungen und interner ethischer Vorgaben sichern. „Aktuelle Entwicklungen beim Datenschutz werden die Verbreitung erklärbarer KI zusätzlich vorantreiben.“
Artikel 22 der DSGVO behandelt „Automatisierte Entscheidungen im Einzelfall“ und fordert eine grundlegende Transparenz. Die EU-Kommission diskutiert über konkrete Anforderungen für Konzeption, Umsetzung und Einsatz von KI-Anwendungen. Marco Peisker geht davon aus, dass in naher Zukunft weitere Vorgaben für die Ausgestaltung von KI-Systemen seitens des Gesetzgebers und auch der Aufsichtsbehörden folgen. „Die Anforderungen an die Erklärbarkeit der maschinellen Entscheidungen werden weiter steigen und der Einsatz von XAI wird sich zu einem Schlüsselfaktor aufsichtsrechtlicher Compliance entwickeln.“
5. Teil: „Algorithmen als Open Source“
Algorithmen als Open Source
Angesichts der drohenden Gefahren durch Manipulation oder fehlerhafte Daten werden Stimmen laut, KI restriktiv zu handhaben. Die US-amerikanische KI-Forscherin Kate Crawford etwa fordert, kritischen Einrichtungen den Einsatz von Blackbox-Algorithmen zu untersagen. Andere regen an, alle Algorithmen als Open Source zu veröffentlichen.
Data Scientist Julian Mehne meint dazu: „In kritischen Anwendungsfällen muss die Qualität der eingesetzten KI-Lösungen gewährleistet sein. Dafür gibt es sicher viele Wege. Open-Source-Algorithmen können hierfür ein Baustein sein, der aber alleine noch keine Qualität garantiert.“
Im KI-Kontext ist für eine volle Transparenz über den Quellcode hinaus der Trainingsdatensatz interessant, da er Rückschlüsse auf das Modellverhalten erlaubt. Und die Trainingsdatensätze sind häufig nicht einsehbar. Wenn also eine vollständige Transparenz erreicht werden soll, dann reicht der Algorithmus nicht aus, sondern die Datensätze müssten ebenfalls offengelegt werden.
„Entscheidungen insbesondere öffentlicher Institutionen, die den Menschen direkt betreffen, sollten grundsätzlich nicht als Ergebnis einzig von Blackbox-Algorithmen getroffen werden“, so Adesso-Manager Marco Peisker. Eine KI, die etwa über die Gewährung bestimmter staatlicher Leistungen entscheide, werde selbst bei objektiv korrekter Entscheidung im Fall einer Ablehnung zu einer fehlenden Akzeptanz bei dem Entscheidungsempfänger führen. Wenn ein Blackbox-Algorithmus Entscheidungen treffe, werde dem Einzelnen zudem die Möglichkeit eines begründeten Einspruchs genommen.
„Alternativ sollten Entscheidungen in Zusammenarbeit zwischen einer Maschine, die die Vorentscheidungen trifft, und einem Menschen zur Entscheidungskontrolle und gegebenenfalls Begründung getroffen werden. Anders sehe ich die Situation bei Entscheidungen durch Blackbox-KI, wenn diese im Zusammenhang mit innerinstitutioneller Prozessoptimierung getroffen werden“, fährt Peisker fort. Öffentliche Einrichtungen empfangen postalisch und elektronisch Unmengen an Schreiben. KI könne hier effizient eingesetzt werden, um die Eingangsdokumente automatisiert zu analysieren, relevante Metadaten zu extrahieren und diese strukturiert dem richtigen Sachbearbeiter zur Verfügung zu stellen. „Begründungen oder Erklärungen für die jeweiligen Entscheidungen der KI sind hier nicht notwendig. Mögliche Fehler haben keinen direkten gravierenden Einfluss auf einzelne Individuen. Hier können natürlich Blackbox-Algorithmen verwendet werden.“
Empathische KI
Neue Buzzwords sind Empathical oder sogar Emotional AI. Schon heute können Algorithmen rudimentäre Emotionen klassifizieren, zum Beispiel durch Gesichtserkennung oder Textanalyse.
Für Data Scientist Julian Mehne ist es gut vorstellbar, dass eines Tages Künstliche Intelligenz menschliche Gefühle zumindest grundlegend verstehen und in die Entscheidungsfindung einfließen lassen kann. „Bis wir aber Liebesbeziehungen mit unserem virtuellen Assistenten eingehen wie vor einiger Zeit in dem Spielfilm „Her“ zu sehen, ist es sicher noch ein weiter Weg.“
Marco Peisker ist da zuversichtlich: Eine Empathical AI könne Texte, Bilder oder auch biometrische Daten analysieren und dann die Entscheidung treffen. Nüchtern betrachtet unterscheide sich eine solche Empathische KI kaum von klassischen Künstlichen Intelligenzen. Nach Emotionen klassifizierte Datensätze werden analysiert und Muster trainiert. Für Systeme, die tatsächlich in der Lage seien, auf menschliche Emotionen zu reagieren, gebe es Unmengen von Einsatzmöglichkeiten. Ein Beispiel sei KI, die zur Verbesserung der Kundenzufriedenheit eingesetzt wird. Die KI schätze bei Texten anhand von Wortwahl, Formulierungen und Satz- oder Sonderzeichen Stimmungslagen ein und untersuche bei Telefonaten Stimmfarbe und die Betonung von Wörtern. „Das ermöglicht die zu der Gefühlslage passende Bearbeitung des Anliegens und erlaubt es den Verantwortlichen, effiziente Strategien und Maßnahmen zur Zufriedenheitsoptimierung zu definieren.“
„In den Bereichen Online-Handel oder Kundenservice sollte Empathische KI weitaus mehr als nur ein Buzzword sein“, findet Pegasystems-Mann Kay Knoche. „Denn Kunden bevorzugen es nach wie vor, persönlich mit einem Berater zu sprechen. Und ein wesentlicher Grund dafür sind die fehlenden empathischen Fähigkeiten der KI.“
6. Teil: „Im Gespräch mit Thomas Liebig von Materna“
Im Gespräch mit Thomas Liebig von Materna
-


 Thomas Liebig: Head of Data Analytics & AI bei MaternaQuelle:Materna
Thomas Liebig: Head of Data Analytics & AI bei MaternaQuelle:Materna

com! professional: Wie können Big Data und KI transparent gestaltet werden?
Thomas Liebig: Letztendlich geht es darum, dass sich das Verfahren in all seinen Facetten erklären lässt. Man kann mitunter sogar schon bevor man das Verfahren verwendet etwas darüber aussagen, wie gut es funktionieren wird.
Wenn ich schlechte Daten habe, dann kommt auch kein tolles Ergebnis dabei heraus. Man hat viel über Diskriminierung durch KI gelesen. Es sind aber nicht die Methoden, die diskriminieren, sondern die verwendeten Datensätze. Deswegen gibt es Bestrebungen zum Beispiel vom Kompetenzzentrum Maschinelles Lernen Rhein Ruhr, dass man eine Art Waschzettel für solche Algorithmen erstellt. Das betrifft dann nicht nur den Algorithmus selbst, sondern auch dessen Implementierung. Da steht dann etwa „Dieser Datensatz funktioniert gut, wenn die Daten die folgende Verteilung haben“. Der Vorteil solcher Waschzettel wäre, dass man die Eigenschaften verifizieren kann, bevor man das Verfahren anwendet.
com! professional: Welche Methoden gibt es noch?
Liebig: Eine weitere Methode ist zum Beispiel eine Perturbation Analysis, wobei man die Daten leicht modifiziert und kleine Schwankungen dazugibt. Dann trainiert man sein Modell neu und schaut, wie stabil das Ergebnis ist, wie sich diese kleinen Störungen auswirken. Dann kann man bestimmte Schranken definieren, wie stark die Auswirkungen sein dürfen, und daraus Erklärmodelle entwickeln. Es gibt Arbeiten in Berlin, die Ergebnisse von neuronalen Netzen zurückpropagieren, um durch eine Art Rückwärts-Ansatz zu Erklärmodellen zu kommen.
Es geht bei KI aber nicht nur um Prognosen und das Clustern von Gruppen. Es gibt auch Planung und Suche, Schlussfolgern und Wissensrepräsentation. Das sind Aspekte, die häufig unter den Tisch fallen. Bei Planung und Suche etwa geht es darum, kürzeste Wege zu finden oder Stundenpläne auszurechnen. Auch so etwas muss erklärbar sein.
com! professional: Wie kommt es zu Diskriminierung und Fehlurteilen?
Liebig: Es gibt für ein Bias verschiedene Ursachen. Es kann ein systematisches Bias sein. Die Auswahl der Daten spielt eine wichtige Rolle. Wenn Sie einen Datensatz haben über Bewerber, dann sollten Sie wahrscheinlich persönliche Daten weglassen wie das Geschlecht und das Alter. Sie trainieren ein Modell und gelangen zu einer Entscheidung. Wenn Sie dieses Modell analysieren, dann ist es mit hoher Wahrscheinlichkeit so, dass es Frauen diskriminiert - obwohl sie das Merkmal Geschlecht weggelassen haben. Das liegt einfach daran, dass etwa die Zeiten des Mutterschutzes im Lebenslauf enthalten sind und das Weglassen der diskriminierenden Eigenschaft das Problem eher verschlimmert. Da Sie die Spalte weggelassen haben, können Sie nicht überprüfen, ob das Modell fair ist oder nicht. Man braucht folglich Verfahren, die in der Lage sind, mögliche Probleme während des Trainierens zu erkennen und gegenzusteuern. Vieles ergibt sich nicht automatisch aus den Daten, muss aber berücksichtigt werden.
com! professional: Sollten Algorithmen Open Source sein oder zertifiziert werden?
Liebig: Ich höre immer wieder, man müsse Algorithmen zertifizieren. Als Informatiker juckt es mich dann unter den Fingernägeln. Eine Zertifizierung von Algorithmen halte ich nicht für sinnvoll. Dazu kommt: Fast alle Verfahren werden bereits als Open Source veröffentlicht, da sie aus wissenschaftlichen Arbeiten hervorgehen. Open-Source-Implementierungen im öffentlichen Bereich könnten sinnvoll sein. Wenn es aber um Unternehmen geht - dort besteht der berechtigte Wunsch, eigene Systeme nicht als Open Source zu veröffentlichen. Was ich gut finde, ist, wenn man Daten Open Source stellt, um Innovationen zuzulassen und Diskriminierung in den Daten offenzulegen.
com! professional: Werden wir eines Tages eine empathische oder emotionale KI erleben?
Liebig: An der TU Darmstadt wird eine Moral-Choice-Machine entwickelt. Es werden viele Textdokumente und Frage-Antwort-Listen maschinell verarbeitet und daraus wird eine empathische KI gebaut. Menschliche Werte wurden so in das System übernommen. Die KI lernte im Experiment etwa, dass man Menschen nicht töten sollte, es aber in Ordnung ist, Zeit totzuschlagen. Man sollte auch lieber eine Scheibe Brot toasten als einen Hamster.
Künstliche Intelligenz
Memary - Langzeitgedächtnis für autonome Agenten
Das Hauptziel ist es, autonomen Agenten die Möglichkeit zu geben, ihr Wissen über einen längeren Zeitraum hinweg zu speichern und abzurufen.
>>
Cloud Infrastructure
Oracle mit neuen KI-Funktionen für Sales, Marketing und Kundenservice
Neue KI-Funktionen in Oracle Cloud CX sollen Marketingspezialisten, Verkäufern und Servicemitarbeitern helfen, die Kundenzufriedenheit zu verbessern, die Produktivität zu steigern und die Geschäftszyklen zu beschleunigen.
>>
Reactive mit Signals
Neuer Vorschlag für Signals in JavaScript
Das für die Standardisierung von JavaScript verantwortliche Komitee macht einen Vorschlag für die Einführung von Signalen in die Programmiersprache. Signals sollen reaktives Programmieren in JavaScript einfacher machen.
>>
Datenverfügbarkeit
Where EDGE Computing meets 5G
Logistik- und Produktionsprozesse sollen flüssig und fehlerfrei laufen. Maschinen und Personal müssen im Takt funktionieren. Zulieferer haben just-in-time anzuliefern. Dies stellt hohe Anforderungen an die lokale Datenübertragung. Welche Technik bietet sich dazu an?
>>