06.03.2019
Datenmanagement
1. Teil: „Auf dem richtigen Weg zu guten Daten“
Auf dem richtigen Weg zu guten Daten
Autor: Klaus Manhart



Bild: Shutterstock / phipatbig
Korrekte und saubere Daten sind heute die Basis für den Erfolg. Für die Software-basierte Sicherstellung gibt es verschiedene Tools aus dem ETL-Umfeld. Kommen diese nicht weiter, bietet sich eine Speziallösung an.
-


 Quelle:Omikron, Navesink Consulting Group
Quelle:Omikron, Navesink Consulting Group

Sind die Daten bei Big-Data-Analysen schlecht, stimmen die Ergebnisse nicht. Entscheidungen werden dann möglicherweise falsch getroffen. „Datenqualität und Entscheidungsqualität stehen in einem direkten Verhältnis“, betont Michaela Tiedemann, CMO beim Münchner Analytics- und Data-Science-Berater Alexander Thamm.
Im KI-Umfeld sind korrekte Daten mindestens ebenso wichtig. Hier ist die Datenqualität entscheidend für das Training der Algorithmen. Und auch hier gilt: Generell ist ein KI-System nur so gut, wie die Daten, auf denen es basiert. Wird mit schlechten Daten trainiert, stimmen die Modelle nicht. Das ist in der KI besonders tragisch, weil man anders als bei Analytics nicht herausfinden kann, auf welchen Datenelementen die Vorhersagen basieren, und falsche Daten kaum korrigieren kann.
Im Bankenbereich, wo KI bereits eingesetzt wird, macht man sich Sorgen um die Qualität von KI-basierten Entscheidungen: „Gerade vor dem Hintergrund des vermehrten Einzugs von KI machen ungenaue und ungeprüfte Daten Banken anfällig für falsche Schlussfolgerungen, die schließlich zu Fehlentscheidungen führen können“, erklärt Christian Altrock, Geschäftsführer beim Beratungsunternehmen Accenture und dort Leiter des Bereichs Banken. In anderen Branchen sind die Sorgen nicht weniger: Laut einer Forrester-Umfrage unter Finanz-, Supply-Chain- und Beschaffungsmanagern ist die größte Herausforderung bei der Einführung von KI die schlechte Qualität der Unternehmensdaten. Nahezu zwei Drittel der Befragten sagen, die schlechte Datenqualität mache es der KI unmöglich, genaue und informierte Entscheidungen zu treffen. Das untergrabe das Ziel, mit Investitionen in KI Gewinne zu erzielen.
2. Teil: „Problemzone Kundendaten“
Problemzone Kundendaten
-
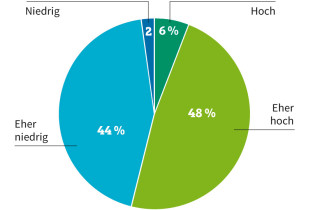
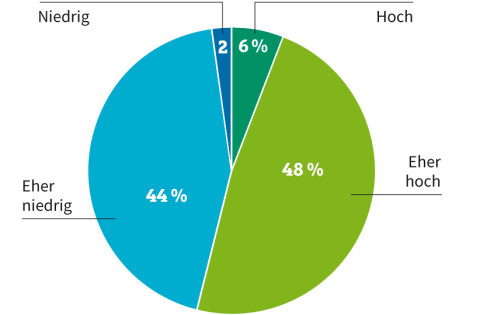
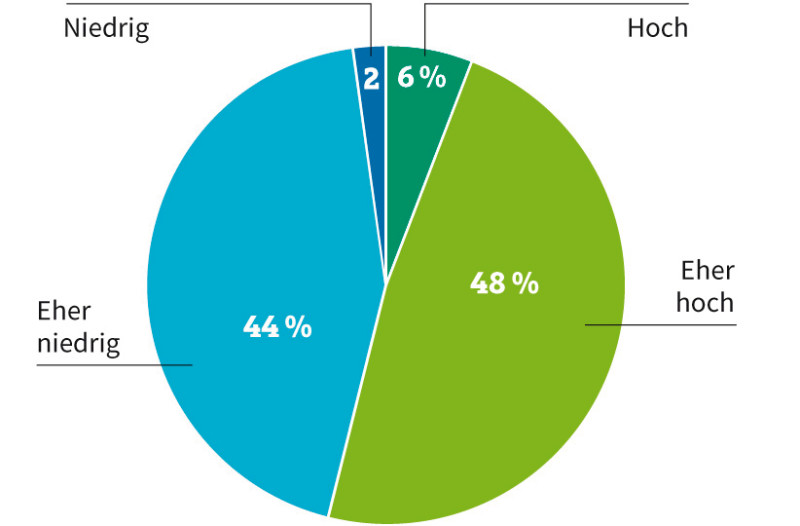
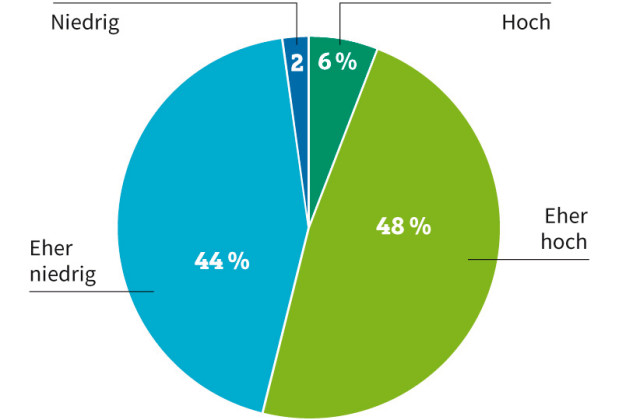 Unternehmensdaten: 46 Prozent der Firmen halten die Datenqualität für "eher niedrig" oder "niedrig"Quelle:Uniserv
Unternehmensdaten: 46 Prozent der Firmen halten die Datenqualität für "eher niedrig" oder "niedrig"Quelle:Uniserv
Ein zentraler Pfeiler für jedes Unternehmen sind die Kundendaten. Diese Daten bilden die Handlungsgrundlage für Marketing, Service und Verkauf. Sie liefern Informationen über das Kauf- und Zahlverhalten, tragen zu einer optimalen Ansprache der Kunden bei und helfen, sie an das Unternehmen zu binden. Schlecht gepflegte Kundendatenbanken konterkarieren diese Ziele.
Konkrete Auswirkungen mangelhafter Kundendaten sind Rückläufer aus Kampagnen des E-Mail-Marketings oder klassischen Mailings. Die Irrläufer müssen manuell aussortiert und die Daten auf den aktuellen Stand gebracht werden. Hohe Kosten und ein enormer Zeitaufwand sind die Folgen. Laut einer DACH-Umfrage von Uniserv, einem spezialisierten Anbieter von Lösungen für das Kundendatenmanagement, ist fast jedes zweite Unternehmen mit der Qualität seiner Kundendaten unzufrieden und stuft diese als niedrig ein.
Einen Grund für die steigende Unzufriedenheit der Befragten mit ihren Daten sieht die Studie auch in den höheren Anforderungen an die Verarbeitung personenbezogener Informationen. Seit Mai letzten Jahres müssen Unternehmen die Vorgaben der Datenschutz-Grundverordnung (DSGVO) umsetzen. Diese stellt höhere Ansprüche an die Verarbeitung personenbezogener Daten und damit auch an die Datenqualität. So müssen Firmen ihren Kunden binnen eines Monats über alle gespeicherten Kundendaten Auskunft geben und diese auf Verlangen löschen können, Stichwort „Recht auf Vergessenwerden“. Ohne eine entsprechend hohe Datenqualität können diese Anforderungen nicht erfüllt werden.
Zahlreiche Gründe
Wie entstehen schlechte Daten? Die Ursachen sind vielfältig: Ein großes Fehlerpotenzial birgt die Datenerfassung. So kommt es etwa bei der Eingabe von Kundendaten via Telefon zu Tippfehlern, Verständnisfehlern und fehlenden oder nicht korrekten Werten, da Kunden oft nicht bereit sind, alle Daten anzugeben oder bewusst falsche Angaben machen.
Ein großes Problem in der Praxis sind auch Dubletten - Mehrfacheinträge, die auftreten, wenn Kunden zum Beispiel über verschiedene Kanäle wie Telefon, E-Mail oder Webformular mit dem Unternehmen in Kontakt treten. Auch wenn die Daten bei der Neuanlage nicht sorgfältig genug erfasst werden oder nicht überprüft wird, ob der Kunde schon vorhanden ist, besteht die Gefahr von Mehrfacheinträgen.
Konkrete Ursachen für falsche Adress-Datensätze sind vor allem Schreibfehler (Alexnader statt Alexander), verschiedene Namensschreibweisen (Maier statt Meier), Namenszusätze (Müller Möbel statt Müller Möbel GmbH), Hörfehler (Maller statt Mahler) oder Verdrehungen (Maier Design statt Design-Maier). Auch Abkürzungen wie Fa. für Firma führen dazu, dass ein Datensatz doppelt und dreifach vorhanden ist. Schätzungen besagen, dass eine gut gepflegte Datenbank zwischen 2 und 10, eine schlecht gepflegte zwischen 20 und 30 Prozent Dubletten enthält.
Eine Rolle kann auch die fehlerhafte Weiterverarbeitung von Ausgangsdaten spielen. Jede Änderung von Daten erhöht die Fehlerwahrscheinlichkeit. Allein Adressdaten müssen im Zuge der zunehmenden Mobilität immer häufiger geändert werden. Auch die wachsenen Datenmassen selbst tragen ihren Teil dazu bei, dass die Datenqualität sinkt. Wo mehr Daten sind, gibt es zwangsläufig auch mehr Fehler.
3. Teil: „Wann sind Daten eigentlich gut?“
Wann sind Daten eigentlich gut?
-
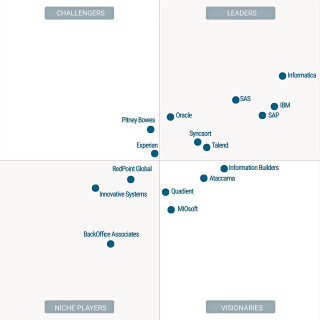
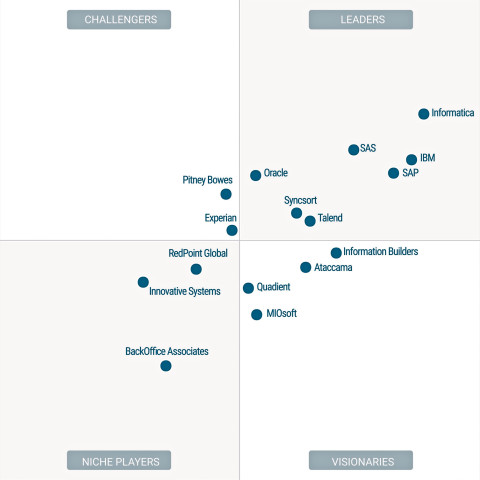
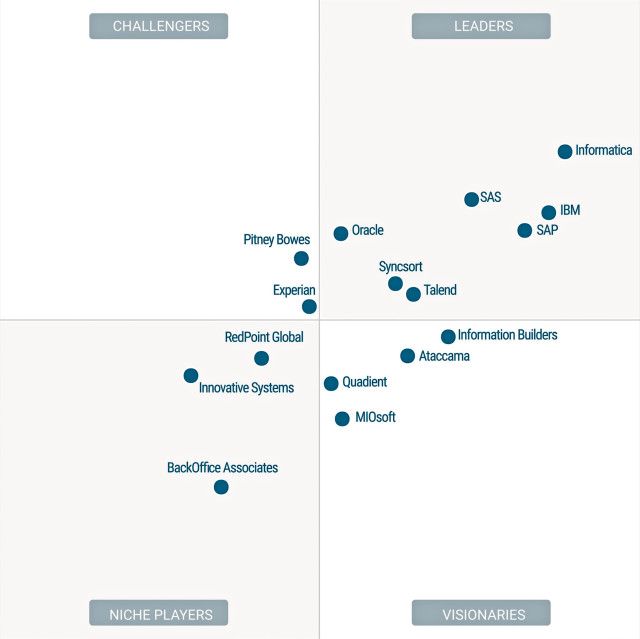
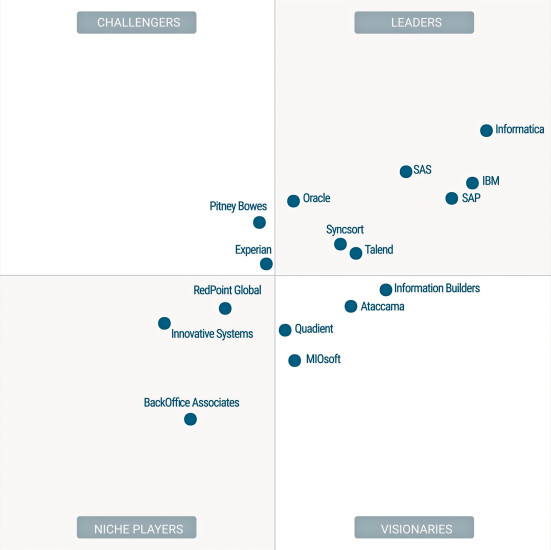
„Magic Quadrant for Data Quality Tools“: Die Gartner-Analysten sehen die Anbieter Informatica, IBM, SAS und SAP derzeit vorn. Quelle:Gartner
Für viele Kriterien lassen sich konkrete Metriken festlegen. Die Vollständigkeit etwa kann über die Menge der eingetragenen Datensätze im Verhältnis zur Menge aller möglichen Datensätze definiert werden, erklärt Felix Naumann vom Hasso-Plattner-Institut der Uni Potsdam. Fehlen bei 100 möglichen Datensätzen 10, dann ist die Vollständigkeit 90 Prozent. Solche Metriken sind auch für andere Kriterien wie Aktualität oder Korrektheit festlegbar. Die Ergebnisse lassen sich auf Spalten, Tabellen und ganze Datensätze aggregieren, sodass Aussagen möglich sind wie „Die Aktualität aller Kundendaten beträgt 80 Prozent“. Immer und überall gültige, objektive Kriterien für gute und schlechte Daten und für alle Anwendungsfälle gibt es allerdings nicht. In der Praxis muss immer aus dem Verwendungskontext entschieden werden, welche Kriterien wichtig sind.
Datenerfassung mit Qualität
Bei der Einhaltung beziehungsweise Verbesserung der Datenqualität gilt grundsätzlich: Am wirkungsvollsten und nachhaltigsten bekämpft man Datenfehler bei ihrer Entstehung - also bei der manuellen Dateneingabe und der automatischen Datenerhebung. Diese Maßnahme nennt sich auch First-Time-Right-Prinzip.
Um von vornherein für klare Verhältnisse zu sorgen, sollte in Form von Metadaten ein Katalog von Eigenschaften definiert werden, die für alle Datenobjekte gelten. Beispielsweise sollte die Art und Weise, wie einzelne Felder in Datensätzen befüllt sein müssen, etwa Schreibweise oder Format, aus dem Regelwerk hervorgehen. Dieser Datenkatalog ist ein Mittel, um die Informationen später für eine Analyse zu identifizieren, und erfüllt zugleich den Zweck, die Vollständigkeit und Konsistenz der Daten sicherzustellen. Der gesamte Datenbestand lässt sich auf diese Weise einheitlich strukturieren und schützt vor Dubletten.
Entsprechend definierte Eingabemasken setzen die Regeln softwaretechnisch um. Moderne ERP- und Datenbank-Software unterstützt bei der Umsetzung. Datenbanksysteme bieten beispielsweise die Möglichkeit, Integritätsbedingungen zu formulieren. Sie erzwingen die Einhaltung bestimmter Formate - bei Datumsangaben etwa die Eingabe bestimmter Werte. Auch wird automatisch geprüft, ob beispielsweise die Kombination aus Postleitzahl und Ort stimmt.
Trotz aller Prüfmechanismen birgt die manuelle Datenerfassung allerdings immer noch ein gewisses Fehlerpotenzial. Wann immer möglich, sollten Daten deshalb automatisch ins System einfließen.
4. Teil: „So bereinigen Sie Ihre Daten“
So bereinigen Sie Ihre Daten
-

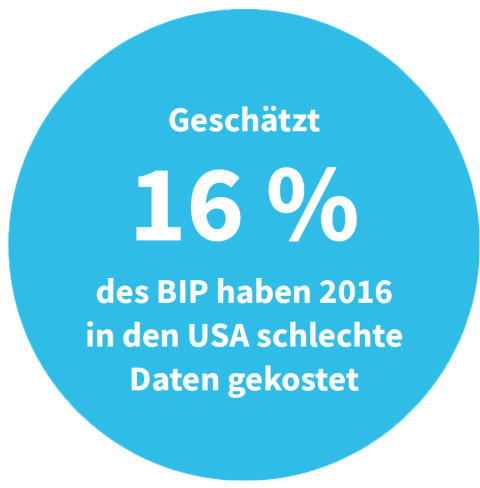
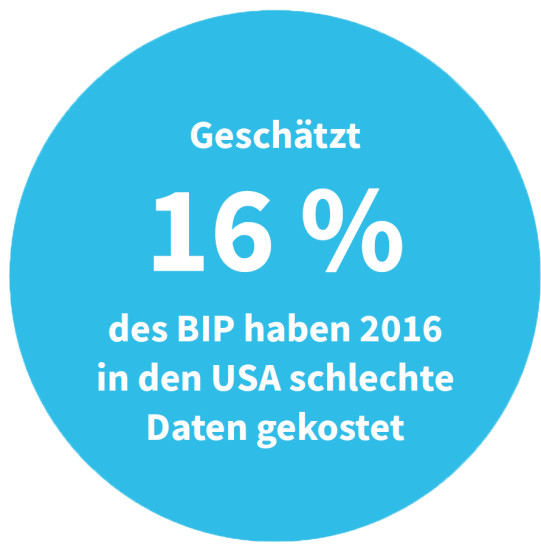
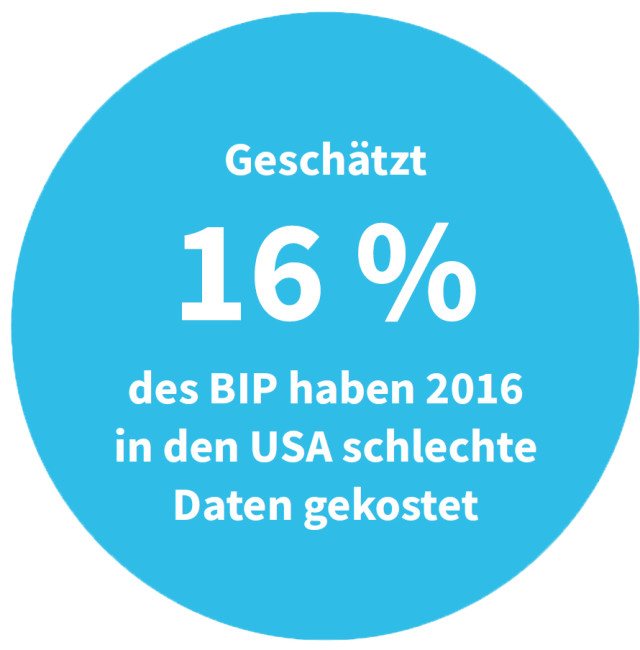 Quelle:Omikron, IBM
Quelle:Omikron, IBM
Die Datenbereinigung - im Fachjargon Data Cleansing genannt - wird aufgrund der großen Datenbestände heute kaum mehr manuell durchgeführt. Stattdessen erledigen Algorithmen diese Aufgabe: Sie überprüfen Datentypen, konvertieren sie und erkennen und vervollständigen lückenhafte Daten. Software übernimmt auch das Bereinigen von Dubletten. Gelöscht werden dürfen Dubletten nicht, denn würde dies geschehen, könnte möglicherweise die richtige, nur einen Tippfehler enthaltende Adresse entfernt werden.
Die Korrektur geschieht im Rahmen eines Regelwerks. Dort wird genau definiert, nach welcher Priorität zwei scheinbar identische Datensätze verändert werden. Wurde beispielsweise eine Dublette identifiziert, bei der mit Ausnahme der Telefonnummer alle Adressbestandteile identisch sind, muss klar sein, welche Nummer übernommen werden soll.
-
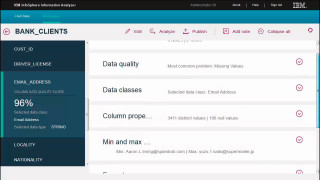
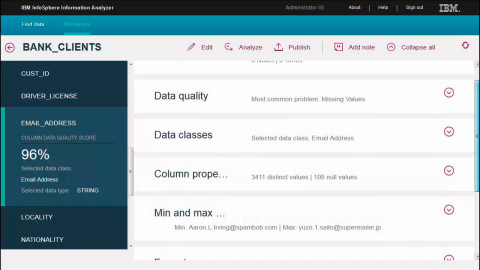
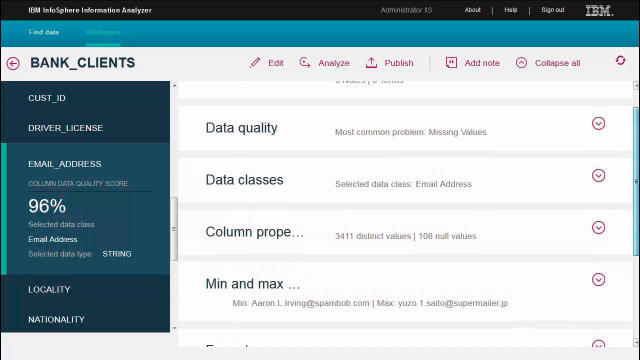 Beispiel für ein Data-Quality-Tool: Der IBM Information Analyzer soll Unternehmen bei der Verbesserung ihrer Datenqualität helfen.Quelle:com! professional / Screenshot
Beispiel für ein Data-Quality-Tool: Der IBM Information Analyzer soll Unternehmen bei der Verbesserung ihrer Datenqualität helfen.Quelle:com! professional / Screenshot
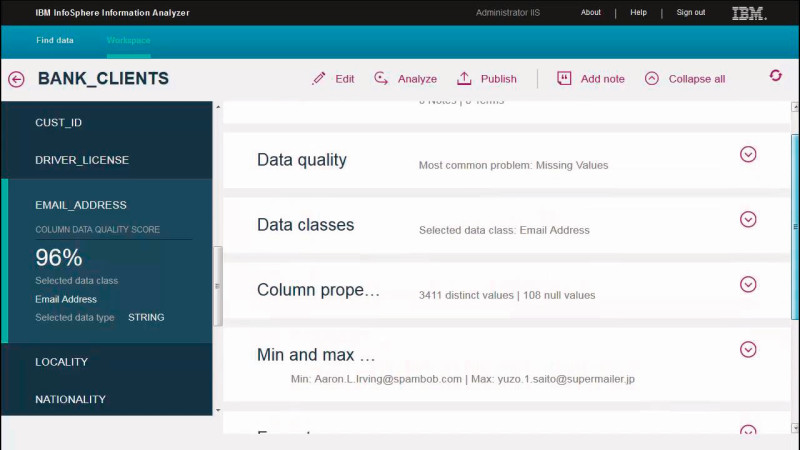
Dazu ein Beispiel: Wenn das Tool mit einer Wahrscheinlichkeit von mindestens 80 Prozent errechnet, dass ein Eintrag ein Duplikat ist, darf es diesen selbstständig als solches behandeln. Ist der Minimumwert 20 Prozent und geringer, ist es automatisch kein Duplikat. Alles, was zwischen 20 und 80 Prozent liegt, sollte sich dann ein Mitarbeiter ansehen.
Für eine optimale Datenqualität zu sorgen ist keine singuläre Herausforderung, sondern ein iterativer Prozess, der fest im Unternehmen verankert werden muss. Weil sich dieser Prozess immer wieder wiederholt, spricht man auch vom Closed-Loop-Prinzip. Gemeint ist damit, ein Datenqualitäts-Managementsystem aufzubauen, das saubere Datensätze auf Dauer sicherstellt.
Hierfür ist es allerdings unerlässlich, wiederkehrende Kontrollen und Bereinigungen einzuplanen. Auch zu diesem Zweck kann Software genutzt werden.
5. Teil: „Qualität als Herausforderung“
Qualität als Herausforderung
-


 Quelle:Omikron, Bostoner Aberdeen Group
Quelle:Omikron, Bostoner Aberdeen Group

Bei unstrukturierten Daten sollte man sich genau überlegen, welche Datenqualität man braucht und wie viel Aufwand man hineinstecken will. Meistens ist bei Textdaten gar keine so hohe Datenqualität notwendig wie im Data Warehouse. „Wenn ich von der nur generell an meinem Unternehmen interessierten Zielgruppe erfahren will, was sie über mein Produkt denkt, ist die maximale Textqualität ziemlich irrelevant“, sagt Harald Gröger, Daten- und Analytics-Spezialist bei IBM. „Ob 78 oder 82 Prozent negativ über mein Produkt sprechen, macht für die Geschäftsentscheidung keinen großen Unterschied.“
Dennoch sollte dem Benutzer eine Information gegeben werden, in welcher Qualität die Daten vorliegen. Besonders im Big-Data-Umfeld ist es mitunter wichtig, die Qualität der Information klar zu kennzeichnen. Dies kann beispielsweise in einem dreistufigen Ampelsystem erfolgen. Grün für qualitätsgeprüfte, hochwertige Daten, Gelb für Daten fragwürdiger Qualität und Rot für nicht geprüfte Daten.
Stammt eine Tabelle aus einem Data Warehouse und ist qualitätsbereinigt, dann stimmen die Daten alle und bekommen das Signal: Grün. Die Social-Media-Analyse hingegen gibt die Stimmung wieder, was Menschen über ein Produkt des Unternehmens sagen, ist von einer geringeren Datenqualität und bekommt die Farbe Gelb oder Rot.
Fazit
Für die softwarebasierte Sicherstellung von Datenqualität gibt es mehrere Optionen. Vieles lässt sich mit klassischen Tools im ETL-Umfeld erledigen. Der ETL-Prozess (Extract, Transform, Load) übernimmt die Bereinigung und Transformation der Daten und stellt sie im Data Warehouse für weitergehende Analysen bereit. Daneben sind auch Spezial-Werkzeuge verfügbar. Zum Beispiel dient Software für Data Profiling zur Standortbestimmung und Aufwandsabschätzung und überprüft Datenbanken und Tabellen auf fehlerhafte Werte. Die eigentliche Bereinigung der Unternehmensdaten übernimmt sogenannte Data-Cleansing-Software. Sie standardisiert und bereinigt Daten. Eine der Hauptaufgaben ist die Identifizierung und Beseitigung von Dubletten. Viele Data-Quality-Werkzeuge bieten auch beide Funktionen in einem.
6. Teil: „Im Gespräch mit Harald Gröger, Daten- und Analytics-Spezialist bei IBM“
Im Gespräch mit Harald Gröger, Daten- und Analytics-Spezialist bei IBM
-


 Harald Gröger: Daten- und Analytics-Spezialist bei IBMQuelle:IBM
Harald Gröger: Daten- und Analytics-Spezialist bei IBMQuelle:IBM

com! professional: Herr Gröger, im Zuge von Big Data und KI erlebt das Thema Datenqualität wieder einen Aufwind. Welche Konsequenzen haben schlechte Daten in diesem Umfeld?
Harald Gröger: Im Big Data-Umfeld werden die Daten oft in großen Data Lakes gesammelt. Stimmt dort die Datenqualität nicht, hat man keinen Datensee, sondern einen Datensumpf. Und der verursacht hohe Kosten. Schließlich kann man nicht tun, was man tun möchte - Analysen fahren und belastbare Prognosen gewinnen.
com! professional: Worin sehen Sie das grundsätzliche Problem bei den Datensammlungen, wie sie heute üblich sind?
Gröger: Das grundsätzliche Problem ist „Garbage in - Garbage out“: Wenn der Input schlecht ist, dann kommt auch ein schlechtes Ergebnis heraus. Leider weiß man über die Qualität des Inputs oft gar nichts. Unternehmen sammeln ja in der Regel alle Daten, die sie bekommen. Weil den größten Teil der Datensammlung noch nie jemand angeschaut hat, kann man nichts über die Datenqualität aussagen.
com! professional: Man braucht doch aber Informationen über die Qualität der Daten. Wie wird die Datenqualität in der Praxis festgestellt?
Gröger: Zunächst muss definiert werden, welche Anforderungen bestehen. Um die notwendige Datenqualität zu definieren, würde ich als Datenverantwortlicher sowohl mit der IT als auch mit den Fachabteilungen sprechen - was schon per se schwierig ist.
Im nächsten Schritt sollten Sie sich dann fragen: Welche Qualität in Prozent brauchen Sie für die konkrete Anwendung aus Sicht der IT und speziell auch des Fachbereichs. Dann sollten Sie sich überlegen, wie viel Aufwand Sie hineinstecken möchten, um die Datenqualität zu verbessern.
com! professional: Sollten Unternehmen nicht generell eine 100-prozentige Datenqualität für alle Daten anstreben?
Gröger: Aus meiner Sicht ist eine 100-prozentige Datenqualität für alle Daten im Data Lake nicht sinnvoll. Der Aufwand würde den Nutzen nicht rechtfertigen. Wenn ich mich bemühe, die Datenqualität auch für Teilbereiche zu erhöhen, die ich gar nicht verwerte, dann ist das nicht adäquat und lohnt nicht. Andererseits sollte im Data Warehouse natürlich schon eine hundertprozentige Datenqualität angestrebt werden.
com! professional: In welchen Bereichen lohnt sich denn eine Verbesserung der Datenqualität?
Gröger: Dafür müssen Sie immer den Anwendungsfall betrachten. Wenn ich an meine Kunden Infobriefe per Post schicke und ein Teil der Adressen ist falsch, lohnt sich eine Datenbereinigung - allein schon wegen der hohen Porto- und Papierkosten. Verschicke ich die Infobriefe per E-Mail, ist
das weniger schlimm, weil die Rückläufe praktisch nichts kosten.
das weniger schlimm, weil die Rückläufe praktisch nichts kosten.
Oder nehmen Sie eine Social-Media-Analyse. Wenn ich mit meinen zehn Top-Kunden eine Analyse mache, muss ich viel in die Textqualität hineinstecken, um genau zu erkennen, was sie über mein Unternehmen gesagt haben. Wenn ich aber von der nur generell an meinem Unternehmen interessierten Zielgruppe erfahren will, was sie über mein Produkt denken, ist die maximale Textqualität ziemlich irrelevant.
com! professional: Sollten aus der Perspektive der Datenqualität Silos verhindert werden und Daten zentral gespeichert werden?
Gröger: Das wäre optimal, entspricht aber nicht der Praxis. In den meisten Unternehmen liegen Daten mehrfach vor - auch wenn sie nur lokal gespeichert werden. Kundenadressen werden gern redundant abgelegt. Da gibt es einen Kundenstamm, eine Auftragsbearbeitung, eine Rechnungsstelle - und alle speichern dieselben Daten ab. Um das zu minimieren, sollten Sie wissen, wo Daten gespeichert sind. Bei einem notwendigen Update ändern Sie die Daten dann wenigstens nur an einer Stelle und übertragen die Änderungen automatisiert auf die redundanten Orte.
com! professional: Wie kann denn nun konkret die Datenqualität festgestellt und verbessert werden?
Gröger: Menschen sind bei der Feststellung der Datenqualität wegen der großen Datenmengen überfordert. Der Grad der Datenqualität wird heute deshalb weitgehend automatisiert untersucht. Solche Tools können beispielsweise Ausreißer finden.
Ein simples Beispiel ist ein Baumarkt, der Besenstiele verkauft. Besenstiele haben normalerweise eine Länge zwischen 1,50 und 1,80 Metern. Steht nun einer mit 25 Metern in der Datenbank, sollte ein Werkzeug diesen Ausreißer identifizieren.
com! professional: Die maschinelle Analyse ist aber nur ein Teil des ganzen Prozesses. Wie ist grundsätzlich die Vorgehensweise bei der Qualitätsanalyse und Datenbereinigung?
Gröger: Grundsätzlich müssen Data Scientists in den großen Datentöpfen, die ihnen zur Verfügung stehen, erst einmal die Quelldaten finden, die für sie relevant sind. Von großem Vorteil ist dabei ein Datenkatalog, aus dem hervorgeht, wo welche Daten liegen. Der Data Scientist „schneidet“ sich dann das Stück an Daten heraus, das er braucht. Für diese Teilbereiche von Daten, die sich die Data Scientists angucken, sollte mit einem Werkzeug eine automatische Datenqualitätsberechnung durchgeführt werden. Dann muss sich der Datenwissenschaftler - eventuell in Absprache mit dem Fachbereich - überlegen, ob die Qualität gut genug ist oder nicht. Wenn nicht, muss eine Bereinigung durchgeführt werden.
com! professional: Kommen wir noch zu einigen Spezialbereichen. Im IoT-Umfeld fallen sehr viele Daten an. Ist die Datenqualität hier besser, weil die Daten von Sensoren und Maschinen kommen?
Gröger: Tendenziell schon, aber nicht grundsätzlich. In den Windrädern der Windradparks sind beispielsweise häufig mehrere Sensoren verbaut. Diese messen Parameter wie die Windgeschwindigkeit und die Temperatur oft mehrfach und liefern gelegentlich widersprüchliche Messdaten. Einfach deshalb, weil sie vielleicht längere Zeit nicht mehr kalibriert wurden. Wenn zwei Sensoren 5 Grad melden und ein anderer 8 Grad, was machen Sie dann? Extra rausfahren und nachgucken ist aufwendig und teuer. Den Mittelwert bilden wäre eine Option, eine andere, sich für die Mehrheit der Messwerte zu entscheiden, also 5 Grad.
com! professional: Können Sie uns noch ein paar Tipps aus Ihrer Kundenpraxis geben, die Ihnen wichtig erscheinen?
Gröger: Spontan fallen mir drei Punkte ein. Erstens: Für jedes Unternehmen, das Daten sammelt, sind beschreibende Daten, also Metadaten, zwingend erforderlich: Welche Struktur haben die Daten? Wo kommen sie her? Wie alt sind sie? Wer ist zuständig?
Zweitens: Was ich in letzter Zeit immer häufiger sehe, ist, dass die Fachabteilungen ihre eigenen Daten pflegen und die IT gar keinen Gesamtüberblick mehr hat. Dieser Tendenz sollten Sie unbedingt entgegensteuern.
Und ein letzter Punkt: Wenden Sie mehr Ressourcen für die Qualitätsbereinigung auf. Dies gilt besonders für die Daten, die für geschäftskritische Analysen eingesetzt werden. Bei anderen Daten reicht eventuell eine weniger gute Qualität, die aber auch dokumentiert sein muss, damit Analysen dies berücksichtigen können.
Test-Framework
Testautomatisierung mit C# und Atata
Atata ist ein umfassendes C#-Framework für die Web-Testautomatisierung, das auf Selenium WebDriver basiert. Es verwendet das Fluent Page Object Pattern und verfügt über ein einzigartiges Protokollierungssystem sowie Trigger-Funktionalitäten.
>>
Programmiersprache
Primärkonstruktoren in C# erleichtern den Code-Refactoring-Prozess
Zusammenfassen, was zusammen gehört: Dabei helfen die in C# 12 neu eingeführten Primärkonstruktoren, indem sie Code kürzer und klarer machen.
>>
Huawei Roadshow 2024
Technologie auf Rädern - der Show-Truck von Huawei ist unterwegs
Die Huawei Europe Enterprise Roadshow läuft dieses Jahr unter dem Thema "Digital & Green: Accelerate Industrial Intelligence". Im Show-Truck zeigt das Unternehmen neueste Produkte und Lösungen. Ziel ist es, Kunden und Partner zusammenzubringen.
>>
Tools
GitLab Duo Chat mit KI-Chat-Unterstützung
Der DevSecOps-Plattform-Anbieter GitLab führt den GitLab Duo Chat ein. Dieses Tool integriert Künstliche Intelligenz in die DevSecOps-Workflows.
>>